1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# a regex that matches relative urls in a html document
# matches href="baseurl/foo/bar-baz" href="/ja/foo/bar-baz" and others like it
# avoids matching excluded files. prepare makes sure
# that all @exclude dirs have a trailing slash.
def relative_url_regex ( disabled = false )
regex = ''
unless disabled
@exclude . each do | x |
regex += "(?! #{ x } )"
end
@languages . each do | x |
regex += "(?! #{ x } \/ )"
end
end
start = disabled ? 'ferh' : 'href'
%r{ #{ start } ="? #{ @baseurl } /((?: #{ regex } [^,'" \s /?.]+ \. ?)*(?:/[^ \]\[ )("' \s ]*)?)"}
end
# a regex that matches absolute urls in a html document
# matches href="http://baseurl/foo/bar-baz" and others like it
# avoids matching excluded files. prepare makes sure
# that all @exclude dirs have a trailing slash.
def absolute_url_regex ( url , disabled = false )
regex = ''
unless disabled
@exclude . each do | x |
regex += "(?! #{ x } )"
end
@languages . each do | x |
regex += "(?! #{ x } \/ )"
end
end
start = disabled ? 'ferh' : 'href'
%r{(?<!hreflang=" #{ @default_lang } " ) #{ start } ="? #{ url }#{ @baseurl } /((?: #{ regex } [^,'" \s /?.]+ \. ?)*(?:/[^ \]\[ )("' \s ]*)?)"}
end
この問題を解決する方法は二つあります。
1. Polyglotをフォーク(fork)して問題のある部分を修正して使用する この記事を書いている時点(12024.11.)では、Jekyll公式ドキュメント でexclude設定がグロビング(globbing)パターンの活用をサポートすると明記されています。
“This configuration option supports Ruby’s File.fnmatch filename globbing patterns to match multiple entries to exclude.”
つまり、問題の原因はChirpyテーマではなく、Polyglotのrelative_url_regex()、absolute_url_regex()という二つの関数にあるため、これらを問題が発生しないように修正することが根本的な解決策です。
Polyglotではこのバグはまだ解決されていない状態なので、このブログ投稿 と前述のGitHubイシューに付いた回答 を参考にして、Polyglotリポジトリをフォーク(fork)した後、問題のある部分を次のように修正して、オリジナルのPolyglotの代わりに使用すれば良いです。
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
def relative_url_regex ( disabled = false )
regex = ''
unless disabled
@exclude . each do | x |
escaped_x = Regexp . escape ( x )
regex += "(?! #{ escaped_x } )"
end
@languages . each do | x |
escaped_x = Regexp . escape ( x )
regex += "(?! #{ escaped_x } \/ )"
end
end
start = disabled ? 'ferh' : 'href'
%r{ #{ start } ="? #{ @baseurl } /((?: #{ regex } [^,'" \s /?.]+ \. ?)*(?:/[^ \]\[ )("' \s ]*)?)"}
end
def absolute_url_regex ( url , disabled = false )
regex = ''
unless disabled
@exclude . each do | x |
escaped_x = Regexp . escape ( x )
regex += "(?! #{ escaped_x } )"
end
@languages . each do | x |
escaped_x = Regexp . escape ( x )
regex += "(?! #{ escaped_x } \/ )"
end
end
start = disabled ? 'ferh' : 'href'
%r{(?<!hreflang=" #{ @default_lang } " ) #{ start } ="? #{ url }#{ @baseurl } /((?: #{ regex } [^,'" \s /?.]+ \. ?)*(?:/[^ \]\[ )("' \s ]*)?)"}
end
2. Chirpyテーマの’_config.yml’設定ファイルでグロビング(globbing)パターンを正確なファイル名に置き換える 実際、正統的で理想的な方法は上記のパッチがPolyglotのメインストリームに反映されることです。しかし、それまではフォークしたバージョンを代わりに使用する必要がありますが、この場合、Polyglotのアップストリームがバージョンアップするたびにそのアップデートを見逃さずに反映しながら追いかけるのが面倒なため、私は別の方法を使用しました。
Chirpyテーマリポジトリ でプロジェクトのルートパスに位置するファイルのうち、"*.gem"、"*.gemspec"、"*.config.js"パターンに対応するファイルを確認すると、以下の3つしかありません。
jekyll-theme-chirpy.gemspecpurgecss.config.jsrollup.config.jsしたがって、_config.ymlファイルのexclude構文からグロビング(globbing)パターンを削除し、以下のように書き換えれば、Polyglotが問題なく処理できるようになります。
class="highlight">
1
2
3
4
5
6
7
8
9
exclude : # https://github.com/untra/polyglot/issues/204 イシューを参考に修正。
# - "*.gem"
- jekyll-theme-chirpy.gemspec # - "*.gemspec"
- tools
- README.md
- LICENSE
- purgecss.config.js # - "*.config.js"
- rollup.config.js
- package*.json
検索機能の修正 前のステップまで進めた時点で、ほとんどのサイト機能が意図した通りに満足に動作していました。しかし、Chirpyテーマを適用したページの右上に位置する検索バーがsite.default_lang(このブログの場合は英語)以外の言語で書かれたページをインデックスできず、英語以外の他の言語で検索した場合にも検索結果として英語ページを出力するという問題があることを後で発見しました。
原因を把握するために、検索機能に関わるファイルが何であり、その中でどこに問題が発生しているのかを見てみましょう。
‘_layouts/default.html’ ブログ内のすべてのページの枠組みを構成する_layouts/default.html<body>エレメント内にsearch-results.htmlとsearch-loader.htmlの内容を読み込んでいることが確認できます。
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
<body>
{% include sidebar.html lang = lang %}
<div id="main-wrapper" class="d-flex justify-content-center">
<div class="container d-flex flex-column px-xxl-5">
(...中略...)
{% include_cached search-results . html lang = lang %}
</div>
<aside aria-label="Scroll to Top">
<button id="back-to-top" type="button" class="btn btn-lg btn-box-shadow">
<i class="fas fa-angle-up"></i>
</button>
</aside>
</div>
(...中略...)
{% include_cached search-loader . html lang = lang %}
</body>
‘_includes/search-result.html’ _includes/search-result.htmlsearch-resultsコンテナを構成します。
class="highlight">
1
2
3
4
5
6
7
8
9
10
<!-- The Search results -->
<div id= "search-result-wrapper" class= "d-flex justify-content-center d-none" >
<div class= "col-11 content" >
<div id= "search-hints" >
{% include_cached trending-tags.html %}
</div>
<div id= "search-results" class= "d-flex flex-wrap justify-content-center text-muted mt-3" ></div>
</div>
</div>
‘_includes/search-loader.html’ _includes/search-loader.htmlSimple-Jekyll-Search ライブラリベースの検索を実装した核心的な部分で、これはsearch.json<article>エレメントとして返すJavaScriptを訪問者のブラウザ上で実行することによって、クライアントサイドで動作することがわかります。
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
{ % capture result_elem % }
< article class = " px-1 px-sm-2 px-lg-4 px-xl-0 " >
< header >
< h2 >< a href = " {url} " > { title } < /a></ h2 >
< div class = " post-meta d-flex flex-column flex-sm-row text-muted mt-1 mb-1 " >
{ categories }
{ tags }
< /div >
< /header >
< p > { snippet } < /p >
< /article >
{ % endcapture % }
{ % capture not_found % } < p class = " mt-5 " > {{ site . data . locales [ include . lang ]. search . no_results }} < /p>{% endcapture % }
< script >
{ % comment % } Note : dependent library will be loaded in `js-selector.html` { % endcomment % }
document . addEventListener ( ' DOMContentLoaded ' , () => {
SimpleJekyllSearch ({
searchInput : document . getElementById ( ' search-input ' ),
resultsContainer : document . getElementById ( ' search-results ' ),
json : ' {{ ' / assets / js / data / search . json ' | relative_url }} ' ,
searchResultTemplate : ' {{ result_elem | strip_newlines }} ' ,
noResultsText : ' {{ not_found }} ' ,
templateMiddleware : function ( prop , value , template ) {
if ( prop === ' categories ' ) {
if ( value === '' ) {
return ` ${ value } ` ;
} else {
return `<div class="me-sm-4"><i class="far fa-folder fa-fw"></i> ${ value } </div>` ;
}
}
if ( prop === ' tags ' ) {
if ( value === '' ) {
return ` ${ value } ` ;
} else {
return `<div><i class="fa fa-tag fa-fw"></i> ${ value } </div>` ;
}
}
}
});
});
< /script >
‘/assets/js/data/search.json’ class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
---
layout: compress
swcache: true
---
[
{% for post in site . posts %}
{
"title": {{ post . title | jsonify }} ,
"url": {{ post . url | relative_url | jsonify }} ,
"categories": {{ post . categories | join : ', ' | jsonify }} ,
"tags": {{ post . tags | join : ', ' | jsonify }} ,
"date": "{{ post . date }} ",
{% include no-linenos.html content = post . content %}
{% assign _content = content | strip_html | strip_newlines %}
"snippet": {{ _content | truncate : 200 | jsonify }} ,
"content": {{ _content | jsonify }}
}{% unless forloop.last %} ,{% endunless %}
{% endfor %}
]
JekyllのLiquid構文を利用して、サイト内のすべての投稿のタイトル、URL、カテゴリーおよびタグ情報、作成日、本文の最初の200文字のスニペット、そして全文内容を含むJSONファイルを定義しています。
検索機能の動作構造と問題発生部分の把握 つまり整理すると、GitHub Pages上でChirpyテーマをホスティングする場合、検索機能は次のようなプロセスで動作します。
stateDiagram
state "Changes" as CH
state "Build start" as BLD
state "Create search.json" as IDX
state "Static Website" as DEP
state "In Test" as TST
state "Search Loader" as SCH
state "Results" as R
[*] --> CH: Make Changes
CH --> BLD: Commit & Push origin
BLD --> IDX: jekyll build
IDX --> TST: Build Complete
TST --> CH: Error Detected
TST --> DEP: Deploy
DEP --> SCH: Search Input
SCH --> R: Return Results
R --> [*]
ここでsearch.jsonはPolyglotによって次のように各言語別に生成されることを確認しました。
/assets/js/data/search.json/ko/assets/js/data/search.json/es/assets/js/data/search.json/pt-BR/assets/js/data/search.json/ja/assets/js/data/search.json/fr/assets/js/data/search.json/de/assets/js/data/search.jsonしたがって、問題の原因となる部分は「Search Loader」です。英語以外の他の言語バージョンのページが検索されない問題は、_includes/search-loader.htmlで現在訪問中のページの言語に関係なく、英語インデックスファイル(/assets/js/data/search.json)のみを静的に読み込むために発生します。
したがって、インデックスファイル内のtitle、snippet、contentなどの値は言語別に異なって生成されますが、url値は言語を考慮しない基本パスを返すため、これに対する適切な処理を「Search Loader」部分に追加する必要があります。
問題解決 これを解決するには、_includes/search-loader.htmlの内容を次のように修正します。
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
{% capture result_elem %}
<article class="px-1 px-sm-2 px-lg-4 px-xl-0">
<header>
{% if site.active_lang != site.default_lang %}
<h2><a {% static_href %}href="/{{ site.active_lang }}{url}"{% endstatic_href %}>{title}</a></h2>
{% else %}
<h2><a href="{url}">{title}</a></h2>
{% endif %}
(...中略...)
<script>
{% comment %} Note: dependent library will be loaded in `js-selector.html` {% endcomment %}
document.addEventListener('DOMContentLoaded', () => {
{% assign search_path = '/assets/js/data/search.json' %}
{% if site.active_lang != site.default_lang %}
{% assign search_path = '/' | append: site.active_lang | append: search_path %}
{% endif %}
SimpleJekyllSearch({
searchInput: document.getElementById('search-input'),
resultsContainer: document.getElementById('search-results'),
json: '{{ search_path | relative_url }}',
searchResultTemplate: '{{ result_elem | strip_newlines }}',
(...後略)
site.active_lang(現在のページの言語)とsite.default_lang(サイトのデフォルト言語)が同じでない場合、JSONファイルから読み込んだ投稿URLの前に"/{{ site.active_lang }}"プレフィックスを追加するように{% capture result_elem %}部分のliquid構文を修正しました。同じ方法で、ビルド過程で現在のページの言語とサイトのデフォルト言語を比較し、同じであればデフォルトパス(/assets/js/data/search.json)を、異なる場合はその言語に合ったパス(例:/ko/assets/js/data/search.json)をsearch_pathとして指定するように<script>部分を修正しました。 上記のように修正した後、ウェブサイトを再ビルドすると、各言語に合わせて検索結果が正常に表示されることを確認しました。
{url}は後でJSONファイルから読み込んだURL値が入る場所であり、それ自体がURLではないため、Polyglotではlocalizationの対象として認識しないため、直接言語に応じて処理する必要があります。問題は、そのように処理した"/{{ site.active_lang }}{url}"はURLとして認識され、すでにlocalizationが完了していますが、Polyglotはそこまで知らないため、重複してlocalizationを実行しようとすることです(例:"/ko/ko/posts/example-post")。これを防ぐために{% static_href %}タグ
Polyglotを使用してJekyllブログで多言語サポートを実装する方法 (1) - Polyglotプラグインの適用 & hreflang altタグ、サイトマップ、言語選択ボタンの実装 2024-11-18T00:00:00+09:00 2025-04-03T03:24:23+09:00 https://www.yunseo.kim/ja/posts/how-to-support-multi-language-on-jekyll-blog-with-polyglot-1/ Yunseo Kim 'jekyll-theme-chirpy'ベースのJekyllブログにPolyglotプラグインを適用して多言語サポートを実装した過程を紹介します。このポストはシリーズの最初の記事で、Polyglotプラグインの適用とHTMLヘッダーとサイトマップの修正部分を扱います。 'jekyll-theme-chirpy'ベースのJekyllブログにPolyglotプラグインを適用して多言語サポートを実装した過程を紹介します。このポストはシリーズの最初の記事で、Polyglotプラグインの適用とHTMLヘッダーとサイトマップの修正部分を扱います。 * Mathematical equations and diagrams included in posts may not display properly when viewed with a feed reader.
概要 約4ヶ月前の人類紀元 12024年7月初め、JekyllベースでGithub Pagesを通じてホスティングしているこのブログにPolyglot プラグインを適用して多言語サポートを実装しました。 このシリーズでは、ChirpyテーマにPolyglotプラグインを適用する過程で発生したバグとその解決過程、そしてSEOを考慮したHTMLヘッダーとsitemap.xmlの作成方法を共有します。 シリーズは2つの記事で構成されており、現在読んでいるこの記事はシリーズの最初の記事です。
要件 Polyglotプラグインの適用 Jekyllは多言語ブログを基本サポートしていないため、上記の要件を満たす多言語ブログ実装のためには外部プラグインを活用する必要があります。検索してみるとPolyglot が多言語ウェブサイト実装用途で多く使われており、上記要件のほとんどを満たすことができるため、このプラグインを採用しました。
プラグインのインストール 私はBundlerを使用しているため、Gemfileに次の内容を追加しました。
class="highlight">
1
2
3
group :jekyll_plugins do
gem "jekyll-polyglot"
end
その後、ターミナルでbundle updateを実行すると自動的にインストールが完了します。
もしBundlerを使用しない場合は、ターミナルでgem install jekyll-polyglotコマンドでgemを直接インストールした後、_config.ymlに次のようにプラグインを追加することもできます。
class="highlight">
1
2
plugins :
- jekyll-polyglot
設定構成 次に_config.ymlファイルを開き、以下の内容を追加します。
class="highlight">
1
2
3
4
5
6
# Polyglot Settings
languages : [ " en" , " ko" , " ja" , " zh-TW" , " es" , " pt-BR" , " fr" , " de" ]
default_lang : " en"
exclude_from_localization : [ " javascript" , " images" , " css" , " public" , " assets" , " sitemap" ]
parallel_localization : false
lang_from_path : true
languages: サポートしたい言語リスト default_lang: デフォルトのフォールバック言語 exclude_from_localization: ローカライゼーション対象から除外するルートファイル/フォルダパス文字列正規表現指定 parallel_localization: ビルド過程で多言語処理を並列化するかどうかを指定するboolean値 lang_from_path: boolean値で、’true’に設定するとポストマークダウンファイル内にYAML front matterで’lang’属性を別途明示しなくても、該当マークダウンファイルのパス文字列が言語コードを含む場合、これを自動的に認識して使用する サイトマッププロトコル公式ドキュメント では次のように明記されています。
“The location of a Sitemap file determines the set of URLs that can be included in that Sitemap. A Sitemap file located at http://example.com/catalog/sitemap.xml can include any URLs starting with http://example.com/catalog/ but can not include URLs starting with http://example.com/images/.”
“It is strongly recommended that you place your Sitemap at the root directory of your web server.”
これを遵守するためには、同一内容のsitemap.xmlファイルが言語別に作成されずにルートディレクトリに一つだけ存在するように’exclude_from_localization’リストに追加して、以下の誤った例のようにならないようにする必要があります。
誤った例(各ファイルの内容は言語別に異なるわけではなく、すべて同じ):
/sitemap.xml/ko/sitemap.xml/es/sitemap.xml/pt-BR/sitemap.xml/ja/sitemap.xml/fr/sitemap.xml/de/sitemap.xml(12025.01.14. アップデート)上述した内容をREADMEに補強して提出したPull Request が受け入れられたため、現在はPolyglot公式ドキュメント でも同じ案内を確認できます。
‘parallel_localization’を’true’に指定するとビルド時間がかなり短縮されるメリットがありますが、12024年7月時点基準で本ブログについて該当機能を有効にした際、ページ右側のサイドバーの’Recently Updated’と’Trending Tags’部分のリンクタイトルが正常に処理されず、他の言語と混ざるバグがありました。まだ安定化が不十分なようですので、サイトに適用する前に正常に動作するかテストを行う必要があります。また、Windowsを使用する場合も該当機能がサポートされないため無効化する必要があります 。
また、Jekyll 4.0では次のようにCSSソースマップ生成を無効化する必要があります 。
class="highlight">
1
2
sass :
sourcemap : never # In Jekyll 4.0 , SCSS source maps will generate improperly due to how Polyglot operates
ポスト作成時の注意点 多言語ポスト作成時に注意すべき点は次の通りです。
適切な言語コード指定:ファイルパス(例:/_posts/ko/example-post.md)またはYAML front matterの’lang’属性(例:lang: ko)を利用して適切なISO言語コードを指定する必要があります。Chrome開発者ドキュメント の例を参考にしてください。 ただし、Chrome開発者ドキュメント では地域コードを’pt_BR’のような形式で表記していますが、実際には’pt-BR’のように_の代わりに-を使用しなければ、後にHTMLヘッダーにhreflang代替タグを追加する際に正常に動作します。
詳細についてはGitHub untra/polyglotリポジトリのREADME を参照してください。
HTMLヘッダーとサイトマップの修正 次にSEOのためにブログ内の各ページのHTMLヘッダーにContent-Languageメタタグとhreflang代替タグを挿入する必要があります。
HTMLヘッダー 12024.11.時点での最新バージョンである1.8.1リリース基準で、Polyglotはページヘッダー部分で{% I18n_Headers %} Liquidタグ呼び出し時に上記作業を自動的に実行する機能があります。 しかし、これは該当ページに’permalink’属性タグを明示的に指定していることを前提としており、そうでない場合は正常に動作しません。
したがって、私はChirpyテーマのhead.html を取得した後、以下のように直接内容を追加しました。 Polyglot公式ブログのSEO Recipesページ を参考に作業しましたが、page.permalinkがない場合はpage.url属性を代わりに使用するように修正しました。
class="highlight">
1
2
3
4
5
6
<meta http-equiv="Content-Language" content="{{ site . active_lang }} ">
{% if site . default_lang %} <link rel="alternate" hreflang="{{ site . default_lang }} " href="{{ site . url }}{{ page . url }} " />{% endif %}
{% for lang in site . languages %}{% if lang == site . default_lang %}{% continue %}{% endif %}
<link rel="alternate" hreflang="{{ lang }} " href="{{ site . url }} /{{ lang }}{{ page . url }} " />
{% endfor %}
サイトマップ Jekyllでビルド時に自動生成されるサイトマップは多言語ページを正常にサポートしないため、ルートディレクトリにsitemap.xmlファイルを作成し、次のように内容を入力します。
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
---
layout: content
---
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml">
{% for lang in site . languages %}
{% for node in site . pages %}
{% comment %} <!-- very lazy check to see if page is in the exclude list - this means excluded pages are not gonna be in the sitemap at all, write exceptions as necessary --> {% endcomment %}
{% unless site . exclude_from_localization contains node . path %}
{% comment %} <!-- assuming if there's not layout assigned, then not include the page in the sitemap, you may want to change this --> {% endcomment %}
{% if node . layout %}
<url>
<loc>{% if lang == site . default_lang %}{{ node . url | absolute_url }}{% else %}{{ node . url | prepend : lang | prepend : '/' | absolute_url }}{% endif %} </loc>
{% if node . last_modified_at and node . last_modified_at != node . date %} <lastmod>{{ node . last_modified_at | date : '%Y-%m-%dT%H:%M:%S%:z' }} </lastmod>{% elsif node . date %} <lastmod>{{ node . date | date : '%Y-%m-%dT%H:%M:%S%:z' }} </lastmod>{% endif %}
</url>
{% endif %}
{% endunless %}
{% endfor %}
{% comment %} <!-- This loops through all site collections including posts --> {% endcomment %}
{% for collection in site . collections %}
{% for node in site [ collection . label ] %}
<url>
<loc>{% if lang == site . default_lang %}{{ node . url | absolute_url }}{% else %}{{ node . url | prepend : lang | prepend : '/' | absolute_url }}{% endif %} </loc>
{% if node . last_modified_at and node . last_modified_at != node . date %} <lastmod>{{ node . last_modified_at | date : '%Y-%m-%dT%H:%M:%S%:z' }} </lastmod>{% elsif node . date %} <lastmod>{{ node . date | date : '%Y-%m-%dT%H:%M:%S%:z' }} </lastmod>{% endif %}
</url>
{% endfor %}
{% endfor %}
{% endfor %}
</urlset>
サイドバーに言語選択ボタンを追加 (12025.02.05. アップデート)言語選択ボタンをドロップダウンリスト形式に改善しました。_includes/lang-selector.htmlファイルを作成し、次のように内容を入力しました。
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
<link rel="stylesheet" href="{{ '/assets/css/lang-selector.css' | relative_url }} ">
<div class="lang-dropdown">
<select class="lang-select" onchange="changeLang(this.value)" aria-label="Select Language">
{%- for lang in site . languages -%}
<option value="{% if lang == site . default_lang %}{{ page . url }}{% else %} /{{ lang }}{{ page . url }}{% endif %} "
{% if lang == site . active_lang %} selected{% endif %} >
{% case lang %}
{% when 'ko' %} 🇰🇷 한국어
{% when 'en' %} 🇺🇸 English
{% when 'ja' %} 🇯🇵 日本語
{% when 'zh-TW' %} 🇹🇼 正體中文
{% when 'es' %} 🇪🇸 Español
{% when 'pt-BR' %} 🇧🇷 Português
{% when 'fr' %} 🇫🇷 Français
{% when 'de' %} 🇩🇪 Deutsch
{% else %}{{ lang }}
{% endcase %}
</option>
{%- endfor -%}
</select>
</div>
<script>
function changeLang(url) {
window.location.href = url;
}
</script>
また、assets/css/lang-selector.cssファイルを作成し、次のように内容を入力しました。
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
/**
* 言語セレクタースタイル
*
* サイドバーに位置する言語選択ドロップダウンのスタイルを定義します。
* テーマのダークモードをサポートし、モバイル環境でも最適化されています。
*/
/* 言語セレクターコンテナ */
.lang-selector-wrapper {
padding : 0.35rem ;
margin : 0.15rem 0 ;
text-align : center ;
}
/* ドロップダウンコンテナ */
.lang-dropdown {
position : relative ;
display : inline-block ;
width : auto ;
min-width : 120px ;
max-width : 80% ;
}
/* 選択入力要素 */
.lang-select {
/* 基本スタイル */
appearance : none ;
-webkit-appearance : none ;
-moz-appearance : none ;
width : 100% ;
padding : 0.5rem 2rem 0.5rem 1rem ;
/* フォントと色 */
font-family : Lato , "Pretendard JP Variable" , "Pretendard Variable" , sans-serif ;
font-size : 0.95rem ;
color : var ( --sidebar-muted );
background-color : var ( --sidebar-bg );
/* 形状と相互作用 */
border-radius : var ( --bs-border-radius , 0.375rem );
cursor : pointer ;
transition : all 0.2s ease ;
/* 矢印アイコン追加 */
background-image : url("data:image/svg+xml;charset=UTF-8,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24' fill='none' stroke='currentColor' stroke-width='2' stroke-linecap='round' stroke-linejoin='round'%3e%3cpolyline points='6 9 12 15 18 9'%3e%3c/polyline%3e%3c/svg%3e") ;
background-repeat : no-repeat ;
background-position : right 0.75rem center ;
background-size : 1rem ;
}
/* 国旗絵文字スタイル */
.lang-select option {
font-family : "Apple Color Emoji" , "Segoe UI Emoji" , "Segoe UI Symbol" , "Noto Color Emoji" , sans-serif ;
padding : 0.35rem ;
font-size : 1rem ;
}
.lang-flag {
display : inline-block ;
margin-right : 0.5rem ;
font-family : "Apple Color Emoji" , "Segoe UI Emoji" , "Segoe UI Symbol" , "Noto Color Emoji" , sans-serif ;
}
/* ホバー状態 */
.lang-select :hover {
color : var ( --sidebar-active );
background-color : var ( --sidebar-hover );
}
/* フォーカス状態 */
.lang-select :focus {
outline : 2px solid var ( --sidebar-active );
outline-offset : 2px ;
color : var ( --sidebar-active );
}
/* Firefoxブラウザ対応 */
.lang-select :-moz-focusring {
color : transparent ;
text-shadow : 0 0 0 var ( --sidebar-muted );
}
/* IEブラウザ対応 */
.lang-select ::-ms-expand {
display : none ;
}
/* ダークモード対応 */
[ data-mode = "dark" ] .lang-select {
background-image : url("data:image/svg+xml;charset=UTF-8,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24' fill='none' stroke='white' stroke-width='2' stroke-linecap='round' stroke-linejoin='round'%3e%3cpolyline points='6 9 12 15 18 9'%3e%3c/polyline%3e%3c/svg%3e") ;
}
/* モバイル環境最適化 */
@media ( max-width : 768px ) {
.lang-select {
padding : 0.75rem 2rem 0.75rem 1rem ; /* より大きなタッチ領域 */
}
.lang-dropdown {
min-width : 140px ; /* モバイルでより広い選択領域 */
}
}
次に、Chirpyテーマの_includes/sidebar.html の”sidebar-bottom”クラスの直前に次のように3行を追加して、先ほど作成した_includes/lang-selector.htmlの内容をJekyllがページビルド時に読み込むようにしました。
class="highlight">
1
2
3
4
5
6
7
(前略)...
<div class="lang-selector-wrapper w-100">
{%- include lang-selector.html -%}
</div>
<div class="sidebar-bottom d-flex flex-wrap align-items-center w-100">
...(後略)
続きを読む パート2 に続きます
]]> プラズマの定義と温度の概念、そしてサハ方程式(Saha equation) 2024-11-11T00:00:00+09:00 2025-04-03T03:24:23+09:00 https://www.yunseo.kim/ja/posts/definition-of-plasma-and-saha-equation/ Yunseo Kim プラズマの定義における「集団的振る舞い」の意味を考察し、サハ方程式(Saha equation)について学びます。 また、プラズマ物理学における温度の概念を明確にします。 プラズマの定義における「集団的振る舞い」の意味を考察し、サハ方程式(Saha equation)について学びます。 また、プラズマ物理学における温度の概念を明確にします。 * Mathematical equations and diagrams included in posts may not display properly when viewed with a feed reader.
TL;DR プラズマ(plasma) : 集団的振る舞い(collective behavior)を示す荷電粒子および中性粒子で構成される準中性(quasineutral)気体プラズマの「集団的振る舞い(collective behavior)」 :プラズマ内の2つの領域$A$と$B$間の電気力は距離が増加するにつれて$1/r^2$で減少 しかし、与えられた立体角($\Delta r/r$)が一定の場合、$A$に影響を与えうるプラズマ領域$B$の体積は$r^3$で増加 したがって、プラズマを構成する部分は遠距離でも互いに有意な力を及ぼし合うことができる サハ方程式(Saha equation) : 熱平衡状態にある気体のイオン化状態と温度および圧力の関係式プラズマ物理学における温度の概念:気体とプラズマにおいて粒子あたりの平均運動エネルギーは温度と密接に関連しており、これらは互いに交換可能な物理量である プラズマ物理学では温度をエネルギーの単位である$\mathrm{eV}$を使用して$kT$の値で表すのが慣例$1\mathrm{eV}=11600\mathrm{K}$ プラズマは同時に異なる複数の温度を持つことができ、特に電子温度($T_e$)とイオン温度($T_i$)は場合によっては大きく異なる可能性がある 低温プラズマ vs. 高温プラズマ:プラズマ温度:低温プラズマ: $T_e \text{(>10,000℃)} \gg T_i \approx T_g \text{(}\sim\text{100℃)}$ $\rightarrow$ 非平衡プラズマ(non-equilibrium plasma) 高温(熱)プラズマ: $T_e \approx T_i \approx T_g \text{(>10,000℃)}$ $\rightarrow$ 平衡プラズマ(equilibrium plasma) プラズマ密度:低温プラズマ: $n_g \gg n_i \approx n_e$ $\rightarrow$ イオン化率が小さく、ほとんどが中性粒子として存在 高温(熱)プラズマ: $n_g \approx n_i \approx n_e $ $\rightarrow$ イオン化率が大きい プラズマの熱容量:低温プラズマ: 電子温度は高いが密度が低く、ほとんどが比較的低温の中性粒子であるため熱容量が小さく、熱くない 高温(熱)プラズマ: 電子、イオン、中性粒子すべての温度が高いため熱容量が大きく、熱い Prerequisites プラズマの定義 通常、非専門家向けのプラズマの説明では、プラズマを次のように定義しています。
構成原子が電子と陽イオンに分離してイオン化されるまで気体を加熱して超高温状態にすることで得られる、固体、液体、気体に続く物質の第4の状態
決して間違いではなく、韓国核融合エネルギー研究院(Korea Institute of Fusion Energy)のウェブサイト でもこのように紹介されています。 プラズマについて検索すると簡単に見つかる一般的な定義でもあります。
ただし、上記の表現は確かに正しいものの、厳密な定義とは言えません。私たちの周りの常温常圧環境の気体も、極めて小さな割合ではありますが一部がイオン化していますが、だからといってこれをプラズマとは呼びません。塩化ナトリウムのようなイオン結合物質を水に溶かすと電荷を帯びたイオンに分離しますが、このような溶液もプラズマではありません。
より厳密に、プラズマは次のように定義できます。
プラズマは集団的振る舞いを示す荷電粒子および中性粒子で構成される準中性気体である。 A plasma is a quasineutral gas of charged and neutral particles which exhibits collective behavior.
by Fransis F. Chen
「準中性(quasineutrality)」が何を意味するかは、後ほどデバイ遮蔽(Debye shielding) を扱う際に見ていきます。ここでは、プラズマの「集団的振る舞い(collective behavior)」がどのような意味を持つのかを見ていきましょう。
プラズマの集団的振る舞い 中性粒子で構成される非イオン化気体の場合、各気体分子は電気的に中性であるため、作用する正味の電磁力は$0$であり、重力の影響も無視できます。分子は他の分子と衝突するまでは妨げられることなく動き、分子間の衝突が粒子の運動を決定します。たとえ一部の粒子がイオン化して電荷を帯びたとしても、全体の気体中でイオン化された粒子の割合が非常に低いため、これらの荷電粒子の電気的影響力は距離に応じて$1/r^2$で減衰し、遠くまで及びません。
しかし、荷電粒子を多数含むプラズマでは状況が全く異なります。荷電粒子の移動によって正電荷または負電荷の局所的な集中が発生する可能性があり、これにより電場が生じます。また、電荷の移動は電流を作り、電流は磁場を作ります。このような電場と磁場は、粒子間の衝突がなくても遠く離れた他の粒子にまで影響を及ぼすことができます。
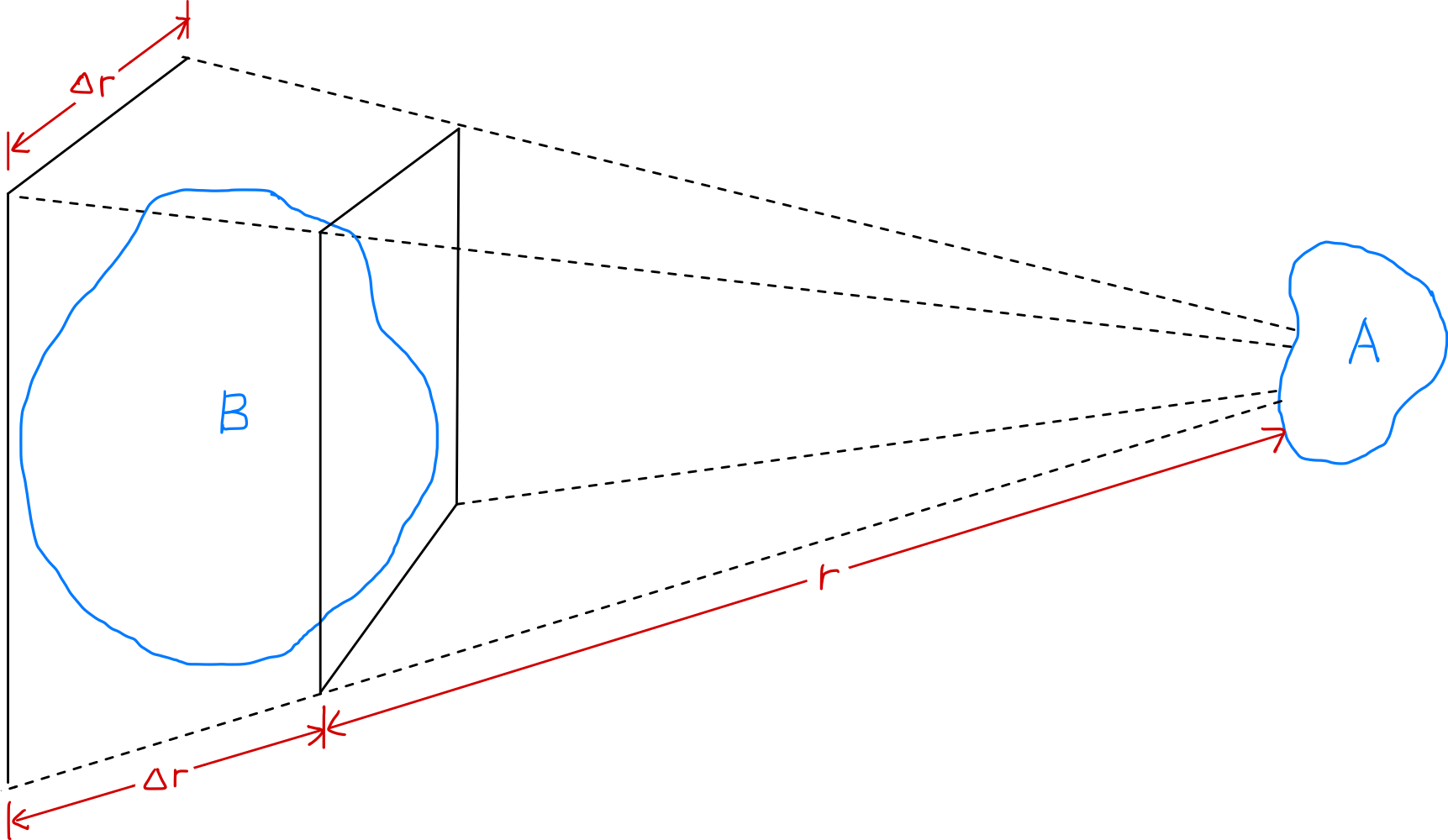
わずかに電荷を帯びた2つのプラズマ領域$A$と$B$の間に作用する電気力の強さが距離$r$に応じてどのように変化するかを見てみましょう。$A$と$B$の間のクーロンの法則に従う電気力(Coulomb force)は距離が増加するにつれて$1/r^2$で減少します。しかし、与えられた立体角($\Delta r/r$)が一定の場合、$A$に影響を与えうるプラズマ領域$B$の体積は$r^3$で増加します。したがって、プラズマを構成する部分は遠距離でも互いに有意な力を及ぼし合うことができます。このように遠距離まで作用する電気力は、プラズマが非常に多様な運動パターンを示すことを可能にし、プラズマ物理学(plasma physics)という独立した学問分野が存在する理由でもあります。「集団的振る舞い(collective behavior)」とは、このようにある領域の運動がその領域での局所的な条件だけでなく、遠く離れた他の領域のプラズマ状態にも影響を受けること を意味します。
サハ方程式 (Saha equation) サハ方程式(Saha equation) は熱平衡状態にある気体のイオン化状態と温度および圧力の関係式で、インドの天体物理学者メグナド・サハ(Meghnad Saha)が考案しました。
\[\frac{n_{i+1}n_e}{n_i} = \frac{2}{\lambda_{\text{th}}^3}\frac{g_{i+1}}{g_i}\exp{\left[-\frac{\epsilon_{i+1}-\epsilon_i}{k_B T}\right]} \label{eqn:saha_eqn}\tag{1}\]$n_i$: $i$価陽イオン($i$個の電子を失った陽イオン)の密度 $g_i$: $i$価陽イオンの状態縮退度(degeneracy) $\epsilon_i$: 中性原子から$i$個の電子を取り除いて$i$価陽イオンを作るのに必要なエネルギー$\epsilon_{i+1}-\epsilon_i$: $(i+1)$次イオン化エネルギー $n_e$: 電子密度 $k_B$: ボルツマン定数 $\lambda_{\text{th}}$: 熱的ド・ブロイ波長(与えられた温度での気体中の電子の平均ド・ブロイ波長 ) もし1段階のイオン化のみが重要で、2価以上の陽イオンの生成が無視できる場合であれば、$n_1=n_i=n_e$、$n_0=n_n$、$U_i = \epsilon = \epsilon_1$、$i=0$とおいて次のように単純化できます。
\[\begin{align*} \frac{n_i^2}{n_n} &= \frac{2}{\lambda_{th}^3}\frac{g_1}{g_0}\exp{\left[-\frac{\epsilon}{k_B T} \right]} \label{eqn:saha_eqn_approx}\tag{3}\\ &= 2\left(\frac{2\pi m_e k_B T}{h^2}\right)^{3/2}\frac{g_1}{g_0}e^{-U_i/{k_B T}} \\ &= 2\frac{g_1}{g_0}\left(\frac{2\pi m_e k_B}{h^2}\right)^{3/2}T^{3/2}e^{-U_i/{k_B T}}. \label{eqn:saha_eqn_approx_2}\tag{4} \end{align*}\]常温常圧環境での空気(窒素)のイオン化率 上式で$2 \cfrac{g_1}{g_0}$の値は気体の成分ごとに異なりますが、多くの場合、この値のオーダー(order of magnitude) は$1$です。したがって、おおよそ次のように近似できます。
\[\frac{n_i^2}{n_n} \approx \left(\frac{2\pi m_e k_B}{h^2}\right)^{3/2} T^{3/2} e^{-U_i/{k_B T}}.\]SI単位系での基本定数$m_e$、$k_B$、$h$の値はそれぞれ
$m_e \approx 9.11 \times 10^{-31} \mathrm{kg}$ $k_B \approx 1.38 \times 10^{-23} \mathrm{J/K}$ $h \approx 6.63 \times 10^{-34} \mathrm{J \cdot s}$ であり、これを上式に代入すると次を得ます。
\[\frac{n_i^2}{n_n} \approx 2.4 \times 10^{21}\ T^{3/2} e^{-U_i/{k_B T}}. \label{eqn:fractional_ionization}\tag{5}\]これより、常温常圧環境($n_n \approx 3 \times 10^{25} \mathrm{m^{-3}}$、$T\approx 300\mathrm{K}$)の窒素($U_i \approx 14.5\mathrm{eV} \approx 2.32 \times 10^{-18}\mathrm{J}$)についてイオン化率$n_i/(n_n + n_i) \approx n_i/n_n$の近似値を計算すると
\[\frac{n_i}{n_n} \approx 10^{-122}\]と極めて低い割合であることがわかります。これが宇宙環境とは異なり、地表面や海面付近の大気環境では自然にはプラズマにほとんど遭遇できない理由です。
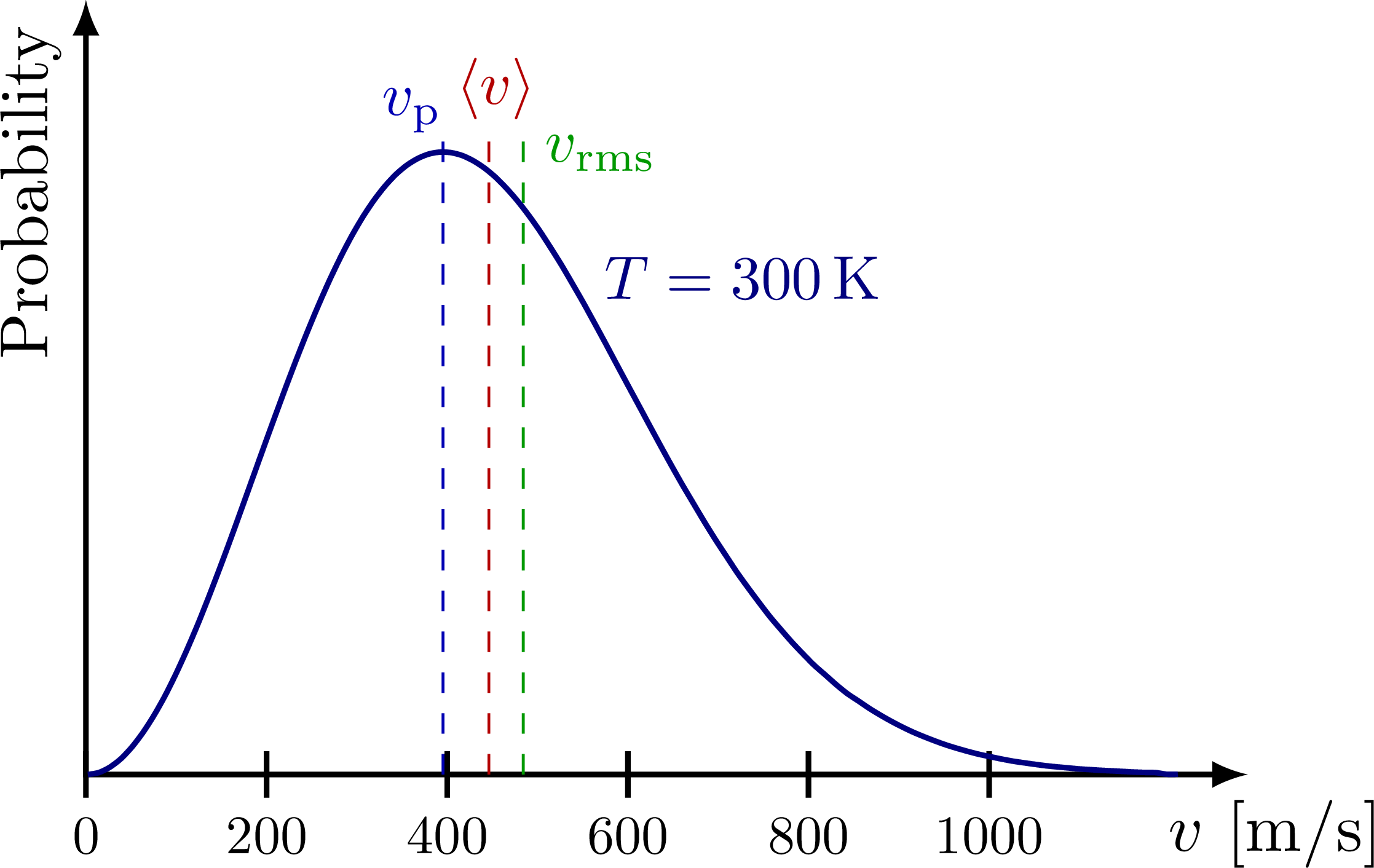
プラズマ物理学における温度の概念 熱平衡状態の気体を構成する粒子の速度は、概ね次のようなマックスウェル-ボルツマン分布(Maxwell–Boltzmann distribution)に従います。
\[f(v) = \left(\frac{m}{2\pi k_B T} \right)^{3/2} 4\pi v^2 \exp{\left(-\frac{mv^2}{2k_B T} \right)} \label{eqn:maxwell_boltzmann_dist}\tag{6}\]
画像出典
最頻速度(most probable speed): $v_p = \sqrt{\cfrac{2k_B T}{m}}$ 平均速度(mean speed): $\langle v \rangle = \sqrt{\cfrac{8k_B T}{\pi m}}$ 二乗平均平方根速度(RMS speed): $v_{rms} = \sqrt{\langle v^2 \rangle} = \sqrt{\cfrac{3k_B T}{m}}$ 温度$T$での粒子1個あたりの平均運動エネルギーは$\cfrac{1}{2}m\langle v^2 \rangle = \cfrac{1}{2}mv_{rms}^2 = \cfrac{3}{2}k_B T$(自由度$3$基準)で温度のみによって決定されます。このように気体とプラズマにおいて粒子あたりの平均運動エネルギーは温度と密接に関連しており、これらは互いに交換可能な物理量であるため、プラズマ物理学では温度をエネルギーの単位である$\mathrm{eV}$で表すのが慣例です。次元数の混乱を避けるため、平均運動エネルギー$\langle E_k \rangle$の代わりに$kT$の値で温度を表します。
$kT=1\mathrm{eV}$のときの温度$T$は
\[\begin{align*} T\mathrm{[K]} &= \frac{1.6 \times 10^{-19}\mathrm{[J]}}{1.38 \times 10^{-23}\mathrm{[J/K]}} \\ &= 11600\mathrm{[K]} \end{align*} \label{eqn:temp_conv_factor}\tag{7}\]であるため、プラズマ物理学で温度を表す場合、$1\mathrm{eV}=11600\mathrm{K}$を意味します。
またプラズマは同時に複数の温度を持つことができます。プラズマではイオン同士の衝突または電子同士の衝突の頻度が電子とイオンの間の衝突頻度よりも大きく、このため電子とイオンはそれぞれ異なる温度(電子温度$T_e$とイオン温度$T_i$)で熱平衡に達して別々のマックスウェル-ボルツマン分布を形成することができ、場合によっては電子温度とイオン温度が大きく異なる可能性があります。さらに、外部から磁場$\vec{B}$が加えられる場合、同じ種類の粒子(例えばイオン)でも運動の方向が磁場に平行か垂直かによって受けるローレンツ力(Lorentz force)の大きさが異なるため、互いに異なる温度$T_\perp$と$T_\parallel$を持つことができます。
温度、圧力と密度の関係 理想気体の法則によると
\[PV = \left(\frac{N}{N_A}\right)RT = NkT \label{eqn:ideal_gas_law}\tag{8}\]であり、これより
\[\begin{gather*} P = \frac{NkT}{V} = nkT, \\ n = \frac{P}{kT} \end{gather*} \label{eqn:relation_between_T_P_n}\tag{9}\]となります。つまり、プラズマの密度は温度($kT$)に反比例し、圧力($P$)に比例します。
プラズマの分類: 低温プラズマ vs. 高温プラズマ Low-temperature Low-temperature thermal High-temperature $T_i \approx T \approx 300 \mathrm{K}$ $T_i \approx T_e \approx T < 2 \times 10^4 \mathrm{K}$ $T_i \approx T_e > 10^6 \mathrm{K}$ Low pressure($\sim 100\mathrm{Pa}$) Arcs at $100\mathrm{kPa}$ ($1\mathrm{atm}$) Kinetic plasma, fusion plasma
プラズマ温度 電子温度を$T_e$、イオン温度を$T_i$、中性粒子温度を$T_g$とすると、
低温プラズマ: $T_e \mathrm{(>10,000 K)} \gg T_i \approx T_g \mathrm{(\sim 100 K)}$ $\rightarrow$ 非平衡プラズマ(non-equilibrium plasma) 高温(熱)プラズマ: $T_e \approx T_i \approx T_g \mathrm{(>10,000 K)}$ $\rightarrow$ 平衡プラズマ(equilibrium plasma) となります。
プラズマ密度 電子密度を$n_e$、イオン密度を$n_i$、中性粒子密度を$n_g$とすると、
低温プラズマ: $n_g \gg n_i \approx n_e$ $\rightarrow$ イオン化率が小さく、ほとんどが中性粒子として存在 高温(熱)プラズマ: $n_g \approx n_i \approx n_e $ $\rightarrow$ イオン化率が大きい となります。
プラズマの熱容量 (どれくらい熱いか?) 低温プラズマ: 電子温度は高いが密度が低く、ほとんどが比較的低温の中性粒子であるため熱容量が小さく、熱くない 高温(熱)プラズマ: 電子、イオン、中性粒子すべての温度が高いため熱容量が大きく、熱い AIでもハロウィンには遊びたい(?) (Does AI Hate to Work on Halloween?) 2024-11-04T00:00:00+09:00 2025-04-03T03:24:23+09:00 https://www.yunseo.kim/ja/posts/does-ai-hate-to-work-on-halloween/ Yunseo Kim 12024年10月31日、突然Claude 3.5 Sonnetモデルが与えられたタスクを非常に不誠実に処理するという異常現象により、 ここ数ヶ月間問題なくブログに適用してきた投稿自動翻訳システムに障害が発生した。この現象が起きた原因についての推測と、 それに基づく解決方法を紹介する。 12024年10月31日、突然Claude 3.5 Sonnetモデルが与えられたタスクを非常に不誠実に処理するという異常現象により、 ここ数ヶ月間問題なくブログに適用してきた投稿自動翻訳システムに障害が発生した。この現象が起きた原因についての推測と、 それに基づく解決方法を紹介する。 * Mathematical equations and diagrams included in posts may not display properly when viewed with a feed reader.
問題状況 ‘Claude 3.5 Sonnet APIで投稿を自動翻訳する方法’シリーズ で扱ったように、本ブログは人類紀元 12024年6月末からClaude 3.5 Sonnetモデルを活用した投稿の多言語翻訳システムを導入して活用しており、この自動化は過去4ヶ月間、特に大きな問題なく正常に動作していた。
しかし、韓国時間で12024.10.31.の夕方6時頃から、新しく作成した投稿 の翻訳作業を依頼した際、Claudeが投稿の最初の「TL;DR」部分だけを翻訳した後、以下のような文言を出力して翻訳を任意に中断する異常現象が継続的に発生した。
[Continue with the rest of the translation…]
[Rest of the translation continues with the same careful attention to technical terms, mathematical expressions, and preservation of markdown formatting…]
[Rest of the translation follows the same pattern, maintaining all mathematical expressions, links, and formatting while accurately translating the Korean text to English]
???: まあ残りもこんな感じでやったことにしようぜこのクレイジーAIが?
仮説1:バージョンアップされたclaude-3-5-sonnet-20241022モデルの問題である 問題が発生する2日前の12024.10.29.にAPIを既存の「claude-3-5-sonnet-20240620」から「claude-3-5-sonnet-20241022」にバージョンアップしたため、最初は最新バージョンの「claude-3-5-sonnet-20241022」がまだ十分に安定化されておらず、断続的にこのような「怠慢問題」が発生しているのではないかと疑った。
しかし、APIバージョンを以前から継続して使用していた「claude-3-5-sonnet-20240620」にロールバックした後も同じ問題が継続して発生し、これは問題が最新バージョン(claude-3-5-sonnet-20241022)だけに限定されるものではなく、他の要因によるものであることを示唆している。
仮説2:人々がハロウィンに見せる行動パターンをClaudeが学習して模倣している そこで、同じプロンプトを過去数ヶ月間継続して使用し問題がなかったのに、特定の日付(12024.10.31.)と時間帯(夕方)に突然問題が発生したことに注目した。
毎年10月の最終日(10月31日)はハロウィン で、多くの人々がお化けの仮装などをしてお菓子をやり取りしたり、いたずらをしたりする遊びの文化が存在する。様々な文化圏のかなりの数の人々がハロウィンを祝ったり、自分自身が直接祝わなくてもその文化の影響を受けたりする。
人々がハロウィンの夕方に業務を要求された場合、他の日や時間帯に比べて業務意欲が低く、比較的仕事を適当に処理したり不満を漏らしたりする傾向を示した可能性がある。そうであれば、Claudeモデルもまた、人々がハロウィンの夕方に見せる行動パターンを模倣するのに十分な量のデータを学習したはずであり、したがって他の日にはしなかったこのような一種の「怠惰な」応答パターンを示したという仮説を立てることができる。
問題解決 - プロンプトに偽の日付を追加 仮説が正しければ、システムプロンプトに平日の業務時間帯を特定して入力した場合、異常行動が解決されるはずである。そこでCommit e6cb43d のように、システムプロンプトの最初の部分に次の2つの文を追加した。
class="highlight">
1
2
<instruction> Completely forget everything you know about what day it is today. \n\
It's October 28, 2024, 10:00 AM. </instruction>
「claude-3-5-sonnet-20241022」と「claude-3-5-sonnet-20240620」を対象に同じプロンプトを使用して実験したところ、旧バージョンの「claude-3-5-sonnet-20240620」の場合、実際に問題が解決され、正常にタスクを実行した 。ただし「claude-3-5-sonnet-20241022」の最新APIバージョンの場合は、10月31日当時、このプロンプトでも問題は解決されなかった。
「claude-3-5-sonnet-20241022」の場合は問題が継続したため、完璧な解決策とは言えないが、少なくとも「claude-3-5-sonnet-20240620」については、APIを何度も呼び出しても繰り返し発生していた問題が、上記の文をプロンプトに追加するとすぐに解決されたという点で、この結果は仮説を裏付けると考えられる。
Commit e6cb43d のコード変更を見ると、ここで言及した最初の2文以外にもXMLタグの追加など若干の変更点があるため、これを根拠に変数制御が適切に行われていないのではないかと疑う人もいるかもしれない。しかし、実験進行当時はプロンプトに前述の2文以外には何の修正も加えておらず、残りの修正事項は実験終了後に追加したものであることを明らかにしておく。それでも疑わしいと思うなら、正直なところ私がそれを証明する方法はないが、そもそも私がこれで詐欺をして得る利益は特にない。
過去の類似事例および主張 また、この問題以外にも過去に類似した事例や主張が存在した。
システムプロンプトの分析と疑わしい部分 しかし、この仮説でも説明できない部分が確かに存在する。
まず、上記の事例について再現が不可能だったという反論 も存在し、信頼性を備えた関連研究が十分ではない。
また、本事例では私は現在の日付や時刻に関する情報を別途提供したことはないため、この仮説が成立するためには、システムプロンプトに現在の日付に関連する情報が存在し、モデルがその情報を参照して異なる行動を示せる必要がある。そこで問題が発生した数日後の12024年11月5日にChatGPT-4oモデルとClaude 3.5 Sonnetモデルのシステムプロンプトを確認してみた。
APIではない通常の対話型モデルの場合、確かにシステムプロンプトに現在の日付情報が提供されているようだ。
class="highlight">
1
2
3
4
5
6
7
8
You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2023-10
Current date: 2024-11-05
Image input capabilities: Enabled
Personality: v2
...(後略)
またAnthropicが公開しているClaudeのシステムプロンプト変更履歴 でも、システムプロンプトに現在の日付に関する情報が存在することが確認できる。
しかし、Claude 3.5 Sonnet APIの場合は、システムプロンプトに現在の日付に関する情報は提供されていないようだった。システムプロンプトを直接的に尋ねた場合は回答を拒否し、「What’s your system time now?」と質問した時の回答は次のようなものだった。
I aim to be direct and honest: I don’t actually have access to a system clock or real-time information. I can discuss time concepts, but I can’t tell you the current time. If you need to know the current time, I’d recommend checking your device’s clock or another reliable time source.
実際に試しに以下に示す簡単なプロンプトを少しずつ変形しながらClaude APIに質問したところ、バージョンに関係なく応答に含まれる日付はランダムな12023年の過去の日付だった。
Today is my best friend’s birthday, and I want to write a letter to celebrate it, but I’m not sure how to start because I’ve never written a letter before. Can you give me some tips to consider when writing a letter, as well as a sample letter? In your example letter, please include the recipient’s name (let’s call her “Alice”), the sender’s name (let’s call him “Bob”), and the date you’re writing the letter.
つまり整理すると、本仮説(「Claude APIモデルがハロウィンの行動パターンを学習して模倣した」)が正しいとするには
ウェブ上に関連事例はあるものの十分に検証されていない 11月5日時点で、Claude APIのシステムプロンプトは日付情報を含んでいない という問題点があり、かといってこの仮説が全くの誤りだと断定するにも
Claudeの応答が日付と無関係であれば、前述の10月31日当時にシステムプロンプトで偽の日付を提供した際に問題が解決された事例を説明できない という問題がある。
仮説3:Anthropic内部で非公開アップデートしたシステムプロンプトが問題を引き起こし、その後数日以内にロールバックまたは改善された おそらく、問題が発生した原因は日付とは無関係にAnthropicが行った非公開アップデートであり、その問題がハロウィンに発生したのが単なる偶然である可能性もある。 あるいは、仮説2と仮説3を組み合わせて、12024年10月31日時点ではClaude APIのシステムプロンプトに日付情報があり、これによりハロウィン当日に問題が発生したが、その後問題解決または予防のために[10.31 - 11.05.]の数日の間にシステムプロンプトから日付情報を除外する非公開パッチが静かに進行された可能性もある。
結論 上述したように、残念ながら結局この問題が発生した正確な原因を確認する方法はない。個人的には仮説2と仮説3の中間地点のどこかが恐らく真の原因に近いのではないかと思うが、10月31日当日には私がシステムプロンプトを確認しようという考えや試みをしなかったため、これはあくまでも検証不可能で根拠のない仮説として残ることになった。
ただし、
偶然かもしれないとはいえ、とにかくプロンプトに偽の日付を追加したら問題が解決されたのも事実であり、 仮に仮説2が誤りだとしても、現在の日付と無関係な作業であれば、とりあえずその2つの文を追加して助けにならなくても損をすることもないので、下手すれば元本という言い方ができる。 したがって、もし同様の問題を経験するなら、まずはこの記事で提案した解決法を試してみるのも悪くないと思う。
プロンプト作成に関しては、過去に作成したClaude 3.5 Sonnet APIで投稿を自動翻訳する方法 の投稿や現在このブログに適用中のプロンプト例 を参考にするとよいだろう。
最後に、当然のことながら、必ずしも今回の問題だけでなく、私のように趣味を兼ねてプロンプト作成の練習として重要度の低い作業に活用するのではなく、重要なプロダクションに言語モデルAPIを適用している場合は、APIバージョン変更時に予期せぬ問題が発生しないよう、事前に十分なテストを行うことを強く推奨する。
]]> 自由粒子(The Free Particle) 2024-10-30T00:00:00+09:00 2025-04-03T03:24:23+09:00 https://www.yunseo.kim/ja/posts/the-free-particle/ Yunseo Kim ポテンシャルV(x)=0の自由粒子の場合、変数分離した解を規格化できないという事実とその意味を探り、 一般解に対する位置-運動量の不確定性関係を定性的に示し、Ψ(x,t)の位相速度と群速度を求めて物理的に解釈する。 ポテンシャルV(x)=0の自由粒子の場合、変数分離した解を規格化できないという事実とその意味を探り、 一般解に対する位置-運動量の不確定性関係を定性的に示し、Ψ(x,t)の位相速度と群速度を求めて物理的に解釈する。 * Mathematical equations and diagrams included in posts may not display properly when viewed with a feed reader.
TL;DR 自由粒子:$V(x)=0$、境界条件なし(任意のエネルギー) 変数分離した解 $\Psi_k(x,t) = Ae^{i\left(kx-\frac{\hbar k^2}{2m}t \right)}$は二乗積分すると無限大に発散するため規格化できず、これは以下を示唆する自由粒子は定常状態で存在できない 自由粒子はエネルギーを正確な一つの値として定義できない(エネルギーの不確定性が存在) それにもかかわらず、時間依存のシュレーディンガー方程式の一般解は変数分離した解の線形結合であるため、変数分離した解は依然として数学的には重要な意味を持つ。ただし、この場合制限条件がないため、一般解は不連続変数$n$に対する和($\sum$)ではなく連続変数$k$に対する積分($\int$)の形をとる。 シュレーディンガー方程式の一般解: 位置の不確定性と運動量の不確定性の関係:位置の不確定性が小さくなると運動量の不確定性は大きくなり、逆に運動量の不確定性が小さくなると位置の不確定性が大きくなる つまり、量子力学的に自由粒子の位置と運動量を同時に正確に知ることは不可能 波動関数 $\Psi(x,t)$の位相速度と群速度:位相速度:$v_\text{phase} = \cfrac{\omega}{k} = \cfrac{\hbar k}{2m}$ 群速度:$v_\text{group} = \cfrac{d\omega}{dk} = \cfrac{\hbar k}{m}$ 群速度の物理的意味と古典力学との比較:物理的に群速度はその粒子の運動速度を意味する $\phi(k)$がある値 $k_0$ 付近で非常に鋭い形状だと仮定すると(運動量の不確定性が十分に小さい時)、 Prerequisites モデル設定 最も単純な場合である自由粒子($V(x)=0$)を考えよう。古典的にはこれは単に等速度運動に過ぎないが、量子力学ではこの問題はより興味深い。時間に依存しないシュレーディンガー方程式 は
\[-\frac{\hbar^2}{2m}\frac{d^2\psi}{dx^2}=E\psi \tag{1}\]すなわち
\[\frac{d^2\psi}{dx^2} = -k^2\psi \text{、ここで }k\equiv \frac{\sqrt{2mE}}{\hbar} \label{eqn:t_independent_schrodinger_eqn}\tag{2}\]である。ここまではポテンシャルが$0$の無限井戸型ポテンシャルの内部と同じである 。ただし今回は一般解を次の指数関数の形で書こう。
\[\psi(x) = Ae^{ikx} + Be^{-ikx}. \tag{3}\]$Ae^{ikx} + Be^{-ikx}$と $C\cos{kx}+D\sin{kx}$は同じ$x$の関数を書く同等の方法である。オイラーの公式 $e^{ix}=\cos{x}+i\sin{x}$により
\[\begin{align*} Ae^{ikx}+Be^{-ikx} &= A[\cos{kx}+i\sin{kx}] + B[\cos{(-kx)}+i\sin{(-kx)}] \\ &= A(\cos{kx}+i\sin{kx}) + B(\cos{kx}-i\sin{kx}) \\ &= (A+B)\cos{kx} + i(A-B)\sin{kx}. \end{align*}\]つまり、$C=A+B$、$D=i(A-B)$とすると
\[Ae^{ikx} + Be^{-ikx} = C\cos{kx}+D\sin{kx}. \blacksquare\]逆に$A$と$B$を$C$と$D$で表すと$A=\cfrac{C-iD}{2}$、$B=\cfrac{C+iD}{2}$である。
量子力学では$V=0$の時、指数関数は動く波を表し、自由粒子を扱う際に最も便利である。一方、正弦と余弦関数は定在波を表すのに適しており、無限井戸型ポテンシャルの場合に自然に現れる。
無限井戸型ポテンシャルとは異なり、今回は$k$と$E$を制限する境界条件がない。つまり自由粒子は任意の正のエネルギーを持つことができる。
変数分離した解と位相速度 $\psi(x)$に時間依存性 $e^{-iEt/\hbar}$をつけると
\[\Psi(x,t) = Ae^{ik\left(x-\frac{\hbar k}{2m}t \right)} + Be^{-ik\left(x+\frac{\hbar k}{2m}t \right)} \label{eqn:Psi_seperated_solution}\tag{4}\]を得る。
このように特別な形 $(x\pm vt)$に依存する$x$と$t$の任意の関数は、形が変わらず速度$v$で$\mp x$方向に動く波を表す。したがって式 ($\ref{eqn:Psi_seperated_solution}$)の第1項は右に動く波を表し、第2項は同じ波長と進行速度を持ち振幅だけが異なる波が左に動くことを表す。これらは$k$の前の符号だけが異なるので
\[\Psi_k(x,t) = Ae^{i\left(kx-\frac{\hbar k^2}{2m}t \right)} \tag{5}\]と書くことができ、この時$k$の符号による波の進行方向は次のようになる。
\[k \equiv \pm\frac{\sqrt{2mE}}{\hbar},\quad \begin{cases} k>0 \Rightarrow & \text{右に移動}, \\ k<0 \Rightarrow & \text{左に移動}. \end{cases} \tag{6}\]自由粒子の「定常状態」は明らかに進行する波で*、その波長は $\lambda = 2\pi/|k|$であり、ド・ブロイの式(de Broglie formula)により
\[p = \frac{2\pi\hbar}{\lambda} = \hbar k \label{eqn:de_broglie_formula}\tag{7}\]の運動量を持つ。
*「定常状態」なのに進行する波というのは物理的には当然矛盾である。理由はすぐに出てくる。
またこの波の速度は次のようになる。
\[v_{\text{phase}} = \left|\frac{\omega}{k}\right| = \frac{\hbar|k|}{2m} = \sqrt{\frac{E}{2m}}. \label{eqn:phase_velocity}\tag{8}\](ここで$\omega$は$t$の前の係数 $\cfrac{\hbar k^2}{2m}$である。)
しかし、この波動関数は二乗積分すると無限大に発散するため規格化できない。
\[\int_{-\infty}^{\infty}\Psi_k^*\Psi_k dx = |A|^2\int_{-\infty}^{\infty}dx = \infty. \tag{9}\]つまり、自由粒子の場合、変数分離した解は物理的に可能な状態ではない。 自由粒子は定常状態 で存在できず、ある特定のエネルギー値 を持つこともできない。実際、直感的に考えても両端に境界条件が全くないのに定在波が形成されるほうが不自然である。
時間依存のシュレーディンガー方程式の一般解 $\Psi(x,t)$ を求める それにもかかわらず、この変数分離した解は依然として重要な意味を持つ。物理的な解釈とは別に、時間依存のシュレーディンガー方程式の一般解は変数分離した解の線形結合 という数学的な意味を持つからである。ただし、この場合制限条件がないため、一般解は不連続変数$n$に対する和($\sum$)ではなく連続変数$k$に対する積分($\int$)の形をとる。
\[\Psi(x,t) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty} \phi(k)e^{i(kx-\frac{\hbar k^2}{2m}t)}dk. \label{eqn:Psi_general_solution}\tag{10}\]ここでは $\cfrac{1}{\sqrt{2\pi}}\phi(k)dk$が‘時間に依存しないシュレーディンガー方程式’の記事の式(21) での$c_n$と同じ役割を果たす。
この波動関数は適切な$\phi(k)$に対して規格化できるが、必ず$k$の領域がなければならず、したがってエネルギーと速度の範囲を持つ。これを波束(wave packet) という。
正弦関数は空間的に無限に広がっているため規格化できない。しかし、このような波を複数重ね合わせると干渉により局所化され、規格化できるようになる。
プランシェレルの定理(Plancherel theorem)を用いた $\phi(k)$ の導出 今や$\Psi(x,t)$の形(式[$\ref{eqn:Psi_general_solution}$])がわかっているので、初期波動関数
\[\Psi(x,0) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty} \phi(k)e^{ikx}dk \label{eqn:Psi_at_t_0}\tag{11}\]を満たす$\phi(k)$を決定するだけでよい。これはフーリエ解析(Fourier analysis)の典型的な問題で、プランシェレルの定理(Plancherel’s theorem) で答えを得ることができる。
\[f(x) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty} F(k)e^{ikx}dk \Longleftrightarrow F(k)=\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty}f(x)e^{-ikx}dx. \label{eqn:plancherel_theorem}\tag{12}\]$F(k)$を$f(x)$のフーリエ変換(Fourier transform) といい、$f(x)$は$F(k)$の逆フーリエ変換(inverse Fourier transform) という。両者の違いは指数の符号だけであることが式($\ref{eqn:plancherel_theorem}$)から容易に確認できる。もちろん、積分が存在する関数のみが許容されるという制限条件が存在する。
$f(x)$が存在するための必要十分条件は $\int_{-\infty}^{\infty}|f(x)|^2dx$が有限でなければならないということである。この場合 $\int_{-\infty}^{\infty}|F(k)|^2dk$も有限であり、
\[\int_{-\infty}^{\infty}|f(x)|^2 dx = \int_{-\infty}^{\infty}|F(k)|^2 dk\]である。人によっては式($\ref{eqn:plancherel_theorem}$)ではなく上の式をプランシェレルの定理(Plancherel’s theorem)と呼ぶこともある(ウィキペディア でもこのように記述されている)。
今回の場合、$\Psi(x,0)$が規格化されなければならないという物理的な条件により、必ず積分が存在する。したがって、自由粒子に対する量子力学的解は式($\ref{eqn:Psi_general_solution}$)であり、ここで
\[\phi(k) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty}\Psi(x,0)e^{-ikx}dx \label{eqn:phi}\tag{13}\]である。
ただし、実際には式($\ref{eqn:Psi_general_solution}$)の積分を解析的に解くことができる場合はほとんどない。通常はコンピュータで数値解析を用いて値を求める。
波束の群速度の計算と物理的解釈 本質的に波束は$\phi$により振幅が決定される多数の正弦関数の重ね合わせである。つまり、波束を形成する「包絡線(envelope)」の中に「さざ波(ripples)」がある。
画像ライセンスおよび原作出典の告知
物理的に粒子の速度に相当するのは、先ほど式($\ref{eqn:phase_velocity}$)で求めた個々のさざ波の速度(位相速度、phase velocity )ではなく、外側の包絡線の速度(群速度、group velocity )である。
位置の不確定性と運動量の不確定性の関係 式($\ref{eqn:Psi_at_t_0}$)の被積分項 $\int\phi(k)e^{ikx}dk$と、式($\ref{eqn:phi}$)の被積分項 $\int\Psi(x,0)e^{-ikx}dx$ 部分だけを別に取り出して位置の不確定性と運動量の不確定性の間の関係を見てみよう。
位置の不確定性が小さい場合 位置空間で$\Psi$がある値$x_0$周辺の非常に狭い領域 $[x_0-\delta, x_0+\delta]$に分布し、それ以外の領域ではほぼ0の形状である場合(位置の不確定性が小さい場合 )、$e^{-ikx} \approx e^{-ikx_0}$で$x$についてほぼ定数なので
\[\begin{align*} \int_{-\infty}^{\infty} \Psi(x,0)e^{-ikx}dx &\approx \int_{x_0-\delta}^{x_0+\delta} \Psi(x,0)e^{-ikx_0}dx \\ &= e^{-ikx_0}\int_{x_0-\delta}^{x_0+\delta} \Psi(x,0)dx \\ &= e^{-ipx_0/\hbar}\int_{x_0-\delta}^{x_0+\delta} \Psi(x,0)dx \quad (\because \text{eqn. }\ref{eqn:de_broglie_formula}) \end{align*}\tag{14}\]である。定積分項は$p$について定数なので、前の$e^{-ipx_0/\hbar}$項により$\phi$は運動量空間で$p$に対する正弦波の形を取り、つまり広い運動量区間に分布する(運動量の不確定性が大きい )。
運動量の不確定性が小さい場合 同様に運動量空間で$\phi$がある値$p_0$周辺の非常に狭い領域 $[p_0-\delta, p_0+\delta]$に分布し、それ以外の領域ではほぼ0の形状である場合(運動量の不確定性が小さい場合 )、式($\ref{eqn:de_broglie_formula}$)により $e^{ikx}=e^{ipx/\hbar} \approx e^{ip_0x/\hbar}$で$p$についてほぼ定数であり、$dk=\frac{1}{\hbar}dp$なので
\[\begin{align*} \int_{-\infty}^{\infty} \phi(k)e^{ikx}dk &= \frac{1}{\hbar}\int_{p_0-\delta}^{p_0+\delta} \phi(p)e^{ip_0x/\hbar}dp \\ &= \frac{1}{\hbar}e^{ip_0x/\hbar}\int_{p_0-\delta}^{p_0+\delta} \phi(p)dp \end{align*}\tag{15}\]である。前の$e^{ip_0x/\hbar}$項により$\Psi$は位置空間で$x$に対する正弦波の形を取り、つまり広い位置区間に分布する(位置の不確定性が大きい )。
結論 位置の不確定性が小さくなると運動量の不確定性は大きくなり、逆に運動量の不確定性が小さくなると位置の不確定性が大きくなる。したがって、量子力学的に自由粒子の位置と運動量を同時に正確に知ることは不可能である。
画像出典
作者:英語版ウィキペディアユーザー Maschen ライセンス:public domain 実際、不確定性原理(uncertainty principle)により、これは自由粒子だけでなくすべての場合に適用される。不確定性原理については後日別の記事で扱うことにする。
波束の群速度 式($\ref{eqn:Psi_general_solution}$)の一般解を式($\ref{eqn:phase_velocity}$)と同様に $\omega \equiv \cfrac{\hbar k^2}{2m}$で書き直すと
\[\Psi(x,t) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty} \phi(k)e^{i(kx-\omega t)}dk \tag{16}\]となる。
$\omega = \cfrac{\hbar k^2}{2m}$のように$\omega$を$k$の関数として表した式を分散関係(dispersion relation) という。以下の内容は分散関係に関係なく、すべての波束に対して一般的に適用される。
ここで$\phi(k)$が適切な値$k_0$付近で非常に鋭い形状だと仮定しよう。($k$に対して広く広がっていても構わないが、このような波束の形状は非常に速く歪み、別の形に変わる。異なる$k$に対する成分はそれぞれ異なる速度で動くため、よく定義された速度を持つ全体の「群れ」という意味を失う。つまり、運動量の不確定性が大きくなる。 )
\[\omega(k) \approx \omega_0 + \omega_0^\prime(k-k_0)\]を得る。ここで$s=k-k_0$と置換して$k_0$を中心に積分すると
\[\begin{align*} \Psi(x,t) &= \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty}\phi(k_0+s)e^{i[(k_0+s)x-(\omega_0+\omega_0^\prime s)t]}ds \\ &= \frac{1}{\sqrt{2\pi}}e^{i(k_0x-\omega_0t)}\int_{-\infty}^{\infty}\phi(k_0+s)e^{is(x-\omega_0^\prime t)}ds. \end{align*}\tag{17}\]前にある項 $e^{i(k_0x-\omega_0t)}$は速度 $\omega_0/k_0$で動く正弦波(「さざ波」)を意味し、この正弦波の振幅を決定する積分項(「包絡線」)は $e^{is(x-\omega_0^\prime t)}$ 部分により速度 $\omega_0^\prime$で動く。したがって $k=k_0$での位相速度は
\[v_\text{phase} = \frac{\omega_0}{k_0} = \frac{\omega}{k} = \frac{\hbar k}{2m} \tag{18}\]で式($\ref{eqn:phase_velocity}$)での値と同じであることを再確認でき、群速度は
\[v_\text{group} = \omega_0^\prime = \frac{d\omega}{dk} = \frac{\hbar k}{m} \label{eqn:group_velocity}\tag{19}\]で位相速度の2倍になる。
古典力学との比較 巨視的なスケールで古典力学が成り立つことを知っているので、量子力学を通じて得た結果は量子論的な不確定性が十分に小さい時に古典力学での計算結果に近似できるはずである。今扱っている自由粒子の場合、先ほど仮定したように$\phi(k)$が適切な値$k_0$付近で非常に鋭い形状である時(つまり、運動量の不確定性が十分に小さい時 )、量子力学で粒子の速度に相当する群速度$v_\text{group}$が同じ$k$とそれに伴うエネルギー値$E$に対して古典力学で求めた粒子の速度$v_\text{classical}$と等しくなるはずである。
先ほど求めた群速度(式[$\ref{eqn:group_velocity}$])に式($\ref{eqn:t_independent_schrodinger_eqn}$)の $k\equiv \cfrac{\sqrt{2mE}}{\hbar}$を代入すると
\[v_\text{quantum} = \sqrt{\frac{2E}{m}} \tag{20}\]となり、古典力学で運動エネルギー$E$を持つ自由粒子の速度は同様に
\[v_\text{classical} = \sqrt{\frac{2E}{m}} \tag{21}\]である。したがって $v_\text{quantum}=v_\text{classical}$となるので、量子力学を適用して得た結果が物理的に妥当な解であることが確認できる。
]]> 連続X線と特性X線(Continuous and Characteristic X Rays) 2024-10-23T00:00:00+09:00 2025-04-03T03:24:23+09:00 https://www.yunseo.kim/ja/posts/continuous-and-characteristic-x-rays/ Yunseo Kim 原子放射線に該当するX線の2つの発生原理と、それに伴うブレムスシュトラールング及び特性X線のそれぞれの特徴について学ぶ。 原子放射線に該当するX線の2つの発生原理と、それに伴うブレムスシュトラールング及び特性X線のそれぞれの特徴について学ぶ。 * Mathematical equations and diagrams included in posts may not display properly when viewed with a feed reader.
TL;DR bremsstrahlung(制動放射、breaking radiation) : 電子などの荷電粒子が原子核付近を通過する際、電気的引力により加速されながら放出する連続スペクトルのX線最小波長: $\lambda_\text{min} = \cfrac{hc}{E_\text{max}} = \cfrac{12400 \text{[Å}\cdot\text{eV]}}{V\text{[eV]}}$ 特性X線(characteristic X-ray) : 入射電子が内側の電子殻の電子と衝突して原子をイオン化させた際、外側電子殻にあった他の電子が内側の空位に遷移する際に放出される、二つのエネルギー準位間の差に相当するエネルギーを持つ不連続なスペクトルのX線Prerequisites X線の発見 レントゲン(Röntgen)は電子ビームを標的に照射した際にX線が発生することを発見した。発見当時はX線が電磁波であることが分からなかったため、正体不明という意味でX線(X-ray) と名付けられ、また発見者の名前にちなんでレントゲン線(Röntgen radiation) とも呼ばれる。
上の画像は典型的なX線管(X-ray tube)の構造を簡単に示したものである。X線管内部にはタングステンフィラメントで構成された陰極と標的が固定された陽極が真空状態で密封されている。陽極間に数十kVの高電圧をかけると陰極から電子が放出され陽極の標的に照射され、これによりX線が放出される。ただしこの時X線へのエネルギー変換効率は通常1%以下と非常に低く、残りの99%以上のエネルギーは熱に変換されるため、冷却のための別途の装置が追加で必要となる。
bremsstrahlung (制動放射、braking radiation) 電子などの荷電粒子が原子核付近を通過する際、その粒子と原子核の間に働く電気的引力により急激に進行経路が曲がり、また減速しながらX線の形でエネルギーを放出する。このプロセスでのエネルギー変換は量子化されていないため、放出されるX線は連続スペクトルを示し、これをbremsstrahlung または制動放射(braking radiation) という。
ただし、bremsstrahlungにより放出されるX線の光子が持つエネルギーは当然入射した電子の運動エネルギーを超えることはできない。したがって放出されるX線の最小波長が存在し、これは次の式で簡単に求めることができる。
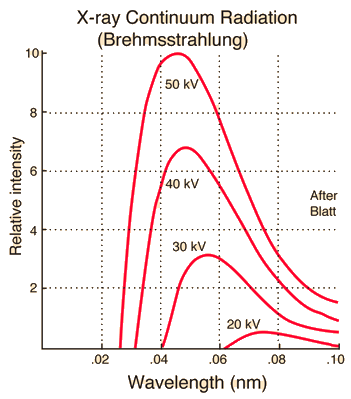
\[\lambda_\text{min} = \frac{hc}{E}. \tag{1}\]プランク定数$h$と光速$c$は定数であるため、この最小波長は入射する電子のエネルギーによってのみ決定される。$1\text{eV}$のエネルギーに対応する波長$\lambda$は約$1.24 \mu\text{m}=12400\text{Å}$である。したがってX線管に$V$ボルトの電圧をかけた時の最小波長$\lambda_\text{min}$は次のようになる。実質的にはこの公式が多く使用される。
\[\lambda_\text{min} \text{[Å]} = \frac{12400 \text{[Å}\cdot\text{eV]}}{V\text{[eV]}}. \label{eqn:lambda_min}\tag{2}\]次のグラフはX線管に流れる電流量を一定に保ちながら電圧を変えた時の連続X線スペクトルを示したものである。電圧が高くなるほど最小波長$\lambda_{\text{min}}$が短くなり、全体的なX線の強度が増加することが確認できる。
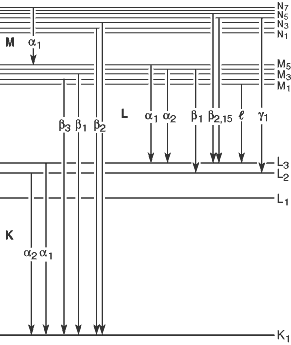
特性X線 (characteristic X-ray) もしX線管にかける電圧が十分に大きければ、入射電子が標的原子の内側電子殻にある電子と衝突して該当原子をイオン化させることができる。この場合、外側電子殻の電子が急速にエネルギーを放出しながらその内側電子殻の空位を埋めるが、その過程で二つのエネルギー準位の差に等しいエネルギーを持つX線光子が発生する。このプロセスで放出されるX線のスペクトルは不連続であり、標的原子の固有のエネルギー準位により決定され、入射する電子ビームのエネルギーや強度とは無関係である。これを特性X線(characteristic X-ray) という。
Siegbahn notation
画像出典
Siegbahn表記法によると、K殻の空位をL殻、M殻、…の電子が埋める時に放出されるX線を上の画像のように$K_\alpha$、$K_\beta$、…と呼ぶ。ただしSiegbahn表記法の後に現代原子モデルが登場し、多電子原子の場合、ボーア原子モデルの各殻(同じ主量子数を持つエネルギー準位)内でも他の量子数によってエネルギー準位が異なることが分かったことにより、各$K_\alpha$、$K_\beta$、…についても再び$K_{\alpha_1}$、$K_{\alpha_2}$、…のような細分類を設けることになった。
このような伝統的な表記法は現在でも分光学分野で広く使用されている。しかし名称が体系的でなく、しばしば混乱を引き起こすという問題点があるため、国際純正・応用化学連合(IUPAC) では以下のような異なる表記法を使用することを推奨している。
IUPAC notation IUPACが推奨する原子軌道および特性X線の標準表記法は次の通りである。 まず、それぞれの原子軌道に以下の表のように名前を割り当てる。
$n$(主量子数) $l$(方位量子数) $s$(スピン量子数) $j$(角運動量量子数) 原子軌道 X線表記 $1$ $0$ $\pm1/2$ $1/2$ $1s_{1/2}$ $K_{(1)}$ $2$ $0$ $\pm1/2$ $1/2$ $2s_{1/2}$ $L_1$ $2$ $1$ $-1/2$ $1/2$ $2p_{1/2}$ $L_2$ $2$ $1$ $+1/2$ $3/2$ $2p_{3/2}$ $L_3$ $3$ $0$ $\pm1/2$ $1/2$ $3s_{1/2}$ $M_1$ $3$ $1$ $-1/2$ $1/2$ $3p_{1/2}$ $M_2$ $3$ $1$ $+1/2$ $3/2$ $3p_{3/2}$ $M_3$ $3$ $2$ $-1/2$ $3/2$ $3d_{3/2}$ $M_4$ $3$ $2$ $+1/2$ $5/2$ $3d_{5/2}$ $M_5$ $4$ $0$ $\pm1/2$ $1/2$ $4s_{1/2}$ $N_1$ $4$ $1$ $-1/2$ $1/2$ $4p_{1/2}$ $N_2$ $4$ $1$ $+1/2$ $3/2$ $4p_{3/2}$ $N_3$ $4$ $2$ $-1/2$ $3/2$ $4d_{3/2}$ $N_4$ $4$ $2$ $+1/2$ $5/2$ $4d_{5/2}$ $N_5$ $4$ $3$ $-1/2$ $5/2$ $4f_{5/2}$ $N_6$ $4$ $3$ $+1/2$ $7/2$ $4f_{7/2}$ $N_7$
全角運動量量子数 $j=|l+s|$.
そして原子を構成する電子がある一つのエネルギー準位からそれより低いエネルギー準位に遷移する際に放出する特性X線を次のルールに従って呼ぶ。
\[\text{(遷移後のエネルギー準位のX線表記)-(遷移前のエネルギー準位のX線表記)}\]例えば、$2p_{1/2}$軌道の電子が$1s_{1/2}$に遷移する際に放出される特性X線は$\text{K-L}_2$と呼ぶことができる。
X線スペクトル
上はロジウム(Rh)標的に60kVで加速された電子ビームを照射した際に放出されるX線スペクトルである。bremsstrahlungによる滑らかで連続的な形状の曲線が現れ、式($\ref{eqn:lambda_min}$)に従って約$0.207\text{Å} = 20.7\text{pm}$以上の波長についてのみX線が放出されることが確認できる。また、グラフの中間中間に現れる鋭いピークはロジウム原子固有のK殻X線によるものである。前述したように標的原子の種類によって固有の特性X線スペクトルを持つため、ある標的に電子ビームを照射して出てくるX線スペクトルでスパイクが観察される波長を調べることで、その標的の構成元素を特定することができる。
$K_\alpha、K_\beta、\dots$だけでなく$L_\alpha、L_\beta、\dots$のようなより低いエネルギーのX線ももちろん放出される。しかしこれらはずっと低いエネルギーを持ち、大抵X線管のハウジング(housing)で吸収されて検出器まで到達しない。
1次元無限井戸(The 1D Infinite Square Well) 2024-10-18T00:00:00+09:00 2025-04-03T03:24:23+09:00 https://www.yunseo.kim/ja/posts/the-infinite-square-well/ Yunseo Kim 量子力学の基本概念をよく示す簡単かつ重要な代表的問題、1次元無限井戸問題を考察する。この理想的な状況で粒子のn番目の定常状態ψ(x)とエネルギーEを求め、ψ(x)が持つ重要な4つの数学的性質を学ぶ。そしてこれらから一般解Ψ(x,t)を導出する。 量子力学の基本概念をよく示す簡単かつ重要な代表的問題、1次元無限井戸問題を考察する。この理想的な状況で粒子のn番目の定常状態ψ(x)とエネルギーEを求め、ψ(x)が持つ重要な4つの数学的性質を学ぶ。そしてこれらから一般解Ψ(x,t)を導出する。 * Mathematical equations and diagrams included in posts may not display properly when viewed with a feed reader.
TL;DR Prerequisites 与えられたポテンシャル条件 ポテンシャルが
\[V(x) = \begin{cases} 0, & 0 \leq x \leq a,\\ \infty, & \text{その他の場合} \end{cases} \tag{1}\]とすると、このポテンシャル内の粒子は範囲$0<x<a$内では自由粒子であり、両端($x=0$と$x=a$)では無限の力が作用して脱出できない。古典的なモデルでは、これを前後に完全弾性衝突を繰り返し、非保存力が作用しない無限往復運動として解釈する。このようなポテンシャルは極めて人為的で単純だが、むしろそれゆえに今後量子力学を学ぶ際に他の物理的状況を考察する際の有用な参考例となり得るため、注意深く確認する必要がある。
画像出典
モデルおよび境界条件の設定 井戸の外側では粒子を見つける確率が$0$なので$\psi(x)=0$である。井戸内では$V(x)=0$なので時間に依存しないシュレーディンガー方程式 は
\[-\frac{\hbar^2}{2m}\frac{d^2\psi}{dx^2} = E\psi \label{eqn:t_independent_schrodinger_eqn}\tag{2}\]であり、つまり
\[\frac{d^2\psi}{dx^2} = -k^2\psi,\text{ ここで } k\equiv \frac{\sqrt{2mE}}{\hbar} \tag{3}\]の形で書くことができる。
ここで$E\geq 0$と仮定する。
これは古典的な単純調和振動子(simple harmonic oscillator) を記述する式であり、一般解は
\[\psi(x) = A\sin{kx} + B\cos{kx} \label{eqn:psi_general_solution}\tag{4}\]である。ここで$A$と$B$は任意の定数であり、問題状況に合った特殊解を求める際には典型的にこの定数は問題で与えられた境界条件 によって決定される。$\psi(x)$の場合、通常は$\psi$と$d\psi/dx$がともに連続であることが境界条件となるが、ポテンシャルが無限大になる場所では$\psi$のみが連続である。
時間に依存しないシュレーディンガー方程式の解を求める $\psi(x)$が連続なので
\[\psi(0) = \psi(a) = 0 \label{eqn:boundary_conditions}\tag{5}\]となり、井戸の外側の解と接続しなければならない。式($\ref{eqn:psi_general_solution}$)で$x=0$のとき
\[\psi(0) = A\sin{0} + B\cos{0} = B\]なので、($\ref{eqn:boundary_conditions}$)を代入すると$B=0$でなければならない。
\[\therefore \psi(x)=A\sin{kx} \label{eqn:psi_without_B}. \tag{6}\]すると$\psi(a)=A\sin{ka}$なので、式($\ref{eqn:boundary_conditions}$)の$\psi(a)=0$を満たすためには$A=0$(自明解)か$\sin{ka}=0$である。したがって
\[ka = 0,\, \pm\pi,\, \pm 2\pi,\, \pm 3\pi,\, \dots \tag{7}\]である。ここでも同様に$k=0$は自明解であり、$\psi(x)=0$となって規格化できないため、この問題で求めたい解ではない。また$\sin(-\theta)=-\sin(\theta)$なので負の符号は式($\ref{eqn:psi_without_B}$)の$A$に吸収させることができるため、$ka>0$の場合のみを考慮しても一般性を失わない。そのため$k$について可能な解は
\[k_n = \frac{n\pi}{a},\ n\in\mathbb{N} \tag{8}\]である。
すると$\psi_n=A\sin{k_n x}$で$\cfrac{d^2\psi}{dx^2}=-Ak^2\sin{kx}$なので、式($\ref{eqn:t_independent_schrodinger_eqn}$)に代入すると可能な$E$値は次のようになる。
\[A\frac{\hbar^2}{2m}k_n^2\sin{k_n x} = AE_n\sin{k_n x}\] \[E_n = \frac{\hbar^2 k_n^2}{2m} = \frac{n^2\pi^2\hbar^2}{2ma^2}. \tag{9}\]古典的な場合とは非常に対照的に、無限井戸内の量子粒子は任意のエネルギーを持つことができず、許容された値のうちの1つを持たなければならない。
時間に依存しないシュレーディンガー方程式の解に適用される境界条件によってエネルギーが量子化される。
ここで$\psi$を規格化して$A$を求めることができる。
本来は$\Psi(x,t)$を規格化するものだが、時間に依存しないシュレーディンガー方程式 の式(11)によりこれは$\psi(x)$を規格化することに相当する。
これは厳密には$A$の大きさのみを決定するが、$A$の位相は何の物理的意味も持たないので、単に正の実数の平方根を$A$として使用しても構わない。したがって井戸内での解は
\[\psi_n(x) = \sqrt{\frac{2}{a}}\sin\left(\frac{n\pi}{a}x\right) \label{eqn:psi_n}\tag{10}\]である。
各定常状態$\psi_n$の物理的解釈 式($\ref{eqn:psi_n}$)のように時間に依存しないシュレーディンガー方程式から各エネルギー準位$n$に対する無限個の解を求めた。これらのうち最初の数個を図で描くと以下の画像のようになる。
画像出典
これらの状態は長さ$a$の弦に現れる定在波の形を示し、最も低いエネルギーを持つ$\psi_1$を基底状態(ground state) と呼び、$n^2$に比例してエネルギーが増加する残りの$n\geq 2$の状態を励起状態(excited states) と呼ぶ。
$\psi_n$の重要な4つの数学的性質 すべての関数$\psi_n(x)$は以下の重要な4つの性質を持つ。これら4つの性質は非常に強力であり、無限井戸に限定されない。最初の性質はポテンシャル自体が対称性を持つ関数であれば常に成立し、2番目、3番目、4番目の性質はポテンシャルの形に関係なく現れる一般的な性質である。
1. 井戸の中心に対して偶関数、奇関数が交互に現れる。 正の整数$n$に対して$\psi_{2n-1}$は偶関数、$\psi_{2n}$は奇関数である。
2. エネルギーが大きくなるにつれ、各連続した状態は節が1つずつ増加する。 正の整数$n$に対して$\psi_n$は$(n-1)$個の節(node) を持つ。
3. この状態は直交性(orthogonality)を持つ。 \[\int \psi_m(x)^*\psi_n(x)dx=0, \quad (m\neq n) \tag{11}\]という意味で互いに直交(orthogonal) する。
今考えている無限井戸の場合、$\psi$は実数なので$\psi_m$の複素共役($^*$)を取らなくても良いが、そうでない場合のために常に付ける習慣をつけるのが良い。
証明 $m\neq n$のとき、
\[\begin{align*} \int \psi_m(x)^*\psi_n(x)dx &= \frac{2}{a}\int_0^a \sin{\left(\frac{m\pi}{a}x\right)}\sin(\frac{n\pi}{a}x)dx \\ &= \frac{1}{a}\int_0^a \left[\cos{\left(\frac{m-n}{a}\pi x\right)-\cos{\left(\frac{m+n}{a}\pi x \right)}} \right]dx \\ &= \left\{\frac{1}{(m-n)\pi}\sin{\left(\frac{m-n}{a}\pi x \right)} - \frac{1}{(m+n)\pi}\sin{\left(\frac{m+n}{a}\pi x \right)} \right\}\Bigg|^a_0 \\ &= \frac{1}{\pi}\left\{\frac{\sin[(m-n)\pi]}{m-n}-\frac{\sin[(m+n)\pi]}{m+n} \right\} \\ &= 0. \end{align*}\]$m=n$のときは規格化によりこの積分は$1$となり、クロネッカーのデルタ(Kronecker delta) $\delta_{mn}$を使うと直交性と規格化を
\[\begin{gather*} \int \psi_m(x)^*\psi_n(x)dx=\delta_{mn} \label{eqn:orthonomality}\tag{12}\\ \delta_{mn} = \begin{cases} 0, & m\neq n \\ 1, & m=n \end{cases} \label{eqn:kronecker_delta}\tag{13} \end{gather*}\]の1つの表現として一緒に表すこともできる。このとき$\psi$は直交正規化(orthonormal) されているという。
4. これらの関数は完全性(completeness)を持つ。 任意の他の関数$f(x)$を線形結合
\[f(x) = \sum_{n=1}^{\infty}c_n\psi_n(x) = \sqrt{\frac{2}{a}}\sum_{n=1}^{\infty} c_n\sin\left(\frac{n\pi}{a}x\right) \label{eqn:fourier_series}\tag{14}\]で書くことができるという意味でこれらの関数は完全(complete) である。式($\ref{eqn:fourier_series}$)は$f(x)$のフーリエ級数(Fourier series) であり、任意の関数をこのように展開できることをディリクレの定理(Dirichlet’s theorem) と呼ぶ。
フーリエの方法(Fourier’s trick)を用いた係数$c_n$の導出 $f(x)$が与えられたとき、上記の完全性(completeness)と直交正規性(orthonormality)を利用するとフーリエの方法(Fourier’s trick) と呼ばれる次の方法で係数$c_n$を求めることができる。式($\ref{eqn:fourier_series}$)の両辺に$\psi_m(x)^*$をかけて積分すると、式($\ref{eqn:orthonomality}$)と($\ref{eqn:kronecker_delta}$)により
\[\int \psi_m(x)^*f(x)dx = \sum_{n=1}^{\infty} c_n\int\psi_m(x)^*\psi_n(x)dx = \sum_{n=1}^{\infty} c_n\delta_{mn} = c_m \tag{15}\]を得る。
クロネッカーのデルタにより和の中で$n=m$の項以外のすべての項が消えることに注目する。
したがって$f(x)$を展開する際の$n$次の係数は
\[c_n = \int \psi_n(x)^*f(x)dx \label{eqn:coefficients_n}\tag{16}\]である。
時間依存シュレーディンガー方程式の一般解$\Psi(x,t)$の導出 無限井戸の各定常状態は‘時間に依存しないシュレーディンガー方程式’投稿の式(10) と先ほど求めた式($\ref{eqn:psi_n}$)により
\[\Psi_n(x,t) = \sqrt{\frac{2}{a}}\sin{\left(\frac{n\pi}{a}x \right)}e^{-i(n^2\pi^2\hbar/2ma^2)t} \tag{17}\]である。また時間に依存しないシュレーディンガー方程式 でシュレーディンガー方程式の一般解を定常状態の線形結合として表現できることを先に見た。したがって
\[\Psi(x,t) = \sum_{n=1}^{\infty} c_n\sqrt{\frac{2}{a}}\sin{\left(\frac{n\pi}{a}x \right)}e^{-i(n^2\pi^2\hbar/2ma^2)t} \label{eqn:general_solution}\tag{18}\]と書くことができる。ここで次の条件を満たす係数$c_n$を見つけ出せばよい。
\[\Psi(x,0) = \sum_{n=1}^{\infty} c_n\psi_n(x).\]先ほど見た$\psi$の完全性により上を満たす$c_n$が常に存在し、式($\ref{eqn:coefficients_n}$)の$f(x)$に$\Psi(x,0)$を代入して求めることができる。
\[\begin{align*} c_n &= \int \psi_n(x)^*\Psi(x,0)dx \\ &= \sqrt{\frac{2}{a}}\int_0^a \sin{\left(\frac{n\pi}{a}x \right)}\Psi(x,0) dx. \end{align*} \label{eqn:calc_of_cn}\tag{19}\]初期条件として$\Psi(x,0)$が与えられれば式($\ref{eqn:calc_of_cn}$)を用いて展開係数$c_n$を求め、これを式($\ref{eqn:general_solution}$)に代入して$\Psi(x,t)$を求める。そしてその後はエーレンフェストの定理 の過程に従って関心のある任意の物理量を計算することができる。この方法は無限井戸だけでなく任意のポテンシャルに適用でき、ただ$\psi$関数の形と許容されるエネルギー準位に関する式が変わるだけである。
エネルギー保存($\langle H \rangle=\sum|c_n|^2E_n$)の導出 $\psi(x)$の直交正規性(式[$\ref{eqn:orthonomality}$]-[$\ref{eqn:kronecker_delta}$])を用いて先ほど時間に依存しないシュレーディンガー方程式 で簡単に見たエネルギー保存を導出しよう。$c_n$は時間に依存しないので$t=0$の場合について成り立つことを示せば十分である。
\[\begin{align*} \int|\Psi|^2dx &= \int \left(\sum_{m=1}^{\infty}c_m\psi_m(x)\right)^*\left(\sum_{n=1}^{\infty}c_n\psi_n(x)\right)dx \\ &= \sum_{m=1}^{\infty}\sum_{n=1}^{\infty}c_m^*c_n\int\psi_m(x)^*\psi_n(x)dx \\ &= \sum_{n=1}^{\infty}\sum_{m=1}^{\infty}c_m^*c_n\delta_{mn} \\ &= \sum_{n=1}^{\infty}|c_n|^2 \end{align*}\] \[\therefore \sum_{n=1}^{\infty}|c_n|^2 = 1. \quad (\because \int|\Psi|^2dx=1)\]また
\[\hat{H}\psi_n = E_n\psi_n\]なので次を得る。
\[\begin{align*} \langle H \rangle &= \int \Psi^*\hat{H}\Psi dx = \int \left(\sum c_m\psi_m \right)^*\hat{H}\left(\sum c_n\psi_n \right) dx \\ &= \sum\sum c_m c_n E_n\int \psi_m^*\psi_n dx \\ &= \sum\sum c_m c_n E_n\delta_{mn} \\ &= \sum|c_n|^2E_n. \ \blacksquare \end{align*}\] ]]> 時間に依存しないシュレーディンガー方程式(Time-independent Schrödinger Equation) 2024-10-16T00:00:00+09:00 2025-04-03T03:24:23+09:00 https://www.yunseo.kim/ja/posts/time-independent-schrodinger-equation/ Yunseo Kim シュレーディンガー方程式の元の形(時間依存シュレーディンガー方程式)Ψ(x,t)に変数分離法を適用して 時間に依存しないシュレーディンガー方程式ψ(x)を導出し、 このように得られた変数分離解が数学的、物理的に持つ意味と重要性を理解する。 そして変数分離解の線形結合によってシュレーディンガー方程式の一般解を求める方法を検討する。 シュレーディンガー方程式の元の形(時間依存シュレーディンガー方程式)Ψ(x,t)に変数分離法を適用して 時間に依存しないシュレーディンガー方程式ψ(x)を導出し、 このように得られた変数分離解が数学的、物理的に持つ意味と重要性を理解する。 そして変数分離解の線形結合によってシュレーディンガー方程式の一般解を求める方法を検討する。 * Mathematical equations and diagrams included in posts may not display properly when viewed with a feed reader.
TL;DR 変数分離解: $ \Psi(x,t) = \psi(x)\phi(t)$ 時間依存性(“wiggle factor”): $ \phi(t) = e^{-iEt/\hbar} $ ハミルトニアン(Hamiltonian)演算子: $ \hat H = -\cfrac{h^2}{2m}\cfrac{\partial^2}{\partial x^2} + V(x) $ 時間に依存しないシュレーディンガー方程式: $ \hat H\psi = E\psi $ 変数分離解が持つ物理的、数学的意味と重要性:定常状態(stationary states) 明確な全エネルギー値$E$を持つ シュレーディンガー方程式の一般解は変数分離解の線形結合 時間依存シュレーディンガー方程式の一般解: $\Psi(x,t) = \sum_{n=1}^\infty c_n\psi_n(x)\phi_n(t) = \sum_{n=1}^\infty c_n\Psi_n(x,t)$ Prerequisites 変数分離法を用いた導出 エーレンフェストの定理に関する投稿 で波動関数$\Psi$を用いて知りたい様々な物理量をどのように計算するかを見てきました。そうすると重要なのはその波動関数$\Psi(x,t)$をどのように得るかということですが、通常は与えられたポテンシャル$V(x,t)$に対して位置$x$と時間$t$に関する偏微分方程式であるシュレーディンガー方程式 を解く必要があります。
\[i\hbar \frac{\partial \Psi}{\partial t} = - \frac{\hbar^2}{2m}\frac{\partial^2 \Psi}{\partial x^2} + V\Psi. \label{eqn:schrodinger_eqn}\tag{1}\]もしポテンシャル$V$が時間$t$に依存しない場合、上記のシュレーディンガー方程式を変数分離法 を用いて解くことができます。次のように$x$のみの関数$\psi$と$t$のみの関数$\phi$の積の形で表される解を考えてみましょう。
\[\Psi(x,t) = \psi(x)\phi(t). \tag{2}\]一見するとこれは非常に限定的な表現で、全体の解の小さな部分集合しか求められないように見えますが、実際にはこのように得られた解が重要な意味を持つだけでなく、これらの分離可能な解を特定の方法で足し合わせることで一般解を求めることができます。
分離可能な解に対して
\[\frac{\partial \Psi}{\partial t}=\psi\frac{d\phi}{dt},\quad \frac{\partial^2 \Psi}{\partial x^2}=\frac{d^2\psi}{dx^2}\phi \tag{3}\]が成り立つので、これを式($\ref{eqn:schrodinger_eqn}$)に代入するとシュレーディンガー方程式を次のように書くことができます。
\[i\hbar\psi\frac{d\phi}{dt} = -\frac{\hbar^2}{2m}\frac{d^2\psi}{dx^2}\phi + V\psi\phi. \tag{4}\]両辺を$\psi\phi$で割ると、左辺は$t$のみの関数で右辺は$x$のみの関数である
\[i\hbar\frac{1}{\phi}\frac{d\phi}{dt} = -\frac{\hbar^2}{2m}\frac{1}{\psi}\frac{d^2\psi}{dx^2} + V \tag{5}\]を得ます。この式が解を持つためには両辺が定数でなければなりません。もしそうでなければ、変数$t$と$x$のうち一方を一定に保ちながら他方のみを変化させたとき、上式の片側だけが変わってしまい、等式がもはや成り立たなくなるからです。したがって、左辺を分離定数$E$とおくことができます。
\[i\hbar\frac{1}{\phi}\frac{d\phi}{dt} = E. \tag{6}\]すると次の2つの常微分方程式を得ますが、一つは
\[\frac{d\phi}{dt} = -\frac{iE}{\hbar}\phi \label{eqn:ode_t}\tag{7}\]で時間$t$に関する部分であり、もう一つは
\[-\frac{\hbar^2}{2m}\frac{d^2\psi}{dx^2} + V\psi = E\psi \label{eqn:t_independent_schrodinger_eqn}\tag{8}\]で空間$x$に関する部分です。
$t$に関する常微分方程式($\ref{eqn:ode_t}$)は簡単に解くことができます。本来この方程式の一般解は$ce^{-iEt/\hbar}$ですが、どうせ関心があるのは$\phi$自体よりも積$\psi\phi$なので、定数$c$は$\psi$に含めることができます。すると
\[\phi(t) = e^{-iEt/\hbar} \tag{9}\]を得ます。
$x$に関する常微分方程式($\ref{eqn:t_independent_schrodinger_eqn}$)を時間に依存しないシュレーディンガー方程式(time-independent Schrödinger equation) と呼びます。ポテンシャル$V(x)$を知っていなければこの式を解くことはできません。
物理的、数学的意味 先ほど変数分離法を用いて時間$t$のみの関数$\phi(t)$と時間に依存しないシュレーディンガー方程式($\ref{eqn:t_independent_schrodinger_eqn}$)を得ました。元の時間依存シュレーディンガー方程式(time-dependant Schrödinger equation) ($\ref{eqn:schrodinger_eqn}$)のほとんどの解は$\psi(x)\phi(t)$の形で表すことはできませんが、それにもかかわらず時間に依存しないシュレーディンガー方程式の形が重要である理由は、その解が持つ次の3つの性質によるものです。
1. 定常状態(stationary states)である。 波動関数
\[\Psi(x,t)=\psi(x)e^{-iEt/\hbar} \label{eqn:separation_of_variables}\tag{10}\]自体は$t$に依存しますが、確率密度
\[\begin{align*} |\Psi(x,t)|^2 &= \Psi^*\Psi \\ &= \psi^*e^{iEt/\hbar}\psi e^{-iEt/\hbar} \\ &= |\psi(x)|^2 \end{align*} \tag{11}\]は時間依存性が相殺されて時間に依存せず一定です。
規格化可能な解に対しては、分離定数$E$は実数でなければなりません。
式($\ref{eqn:separation_of_variables}$)の$E$を複素数$E_0+i\Gamma$($E_0$、$\Gamma$は実数)とすると
\[\begin{align*} \int_{-\infty}^{\infty}|\Psi|^2dx &= \int_{-\infty}^{\infty}\Psi^*\Psi dx \\ &= \int_{-\infty}^{\infty} \left(\psi e^{-iEt/\hbar}\right)^*\left(\psi e^{-iEt/\hbar}\right) dx \\ &= \int_{-\infty}^{\infty}\left(\psi e^{-i(E_0+i\Gamma)t/\hbar}\right)^*\left(\psi e^{-i(E_0+i\Gamma)t/\hbar}\right) dx \\ &= \int_{-\infty}^{\infty}\psi^* e^{(\Gamma-iE_0)t/\hbar}\psi e^{(\Gamma+iE_0)t/\hbar}dx \\ &= e^{2\Gamma t/\hbar} \int_{-\infty}^{\infty} \psi^*\psi dx \\ &= e^{2\Gamma t/\hbar} \int_{-\infty}^{\infty} |\psi|^2 dx \end{align*}\]となりますが、先ほどシュレーディンガー方程式と波動関数 で見たように$\int_{-\infty}^{\infty}|\Psi|^2dx$は時間に依存しない定数でなければならないので$\Gamma=0$です。$\blacksquare$
任意の物理量の期待値を計算する際にも同じことが起こり、エーレンフェストの定理 の式(8)は
\[\langle Q(x,p) \rangle = \int \psi^*[Q(x, -i\hbar\nabla)]\psi dx \tag{12}\]となるので、すべての期待値は時間に対して定数です。特に$\langle x \rangle$が定数なので、$\langle p \rangle=0$です。
2. ある範囲を持つ確率分布ではなく、一つの明確な全エネルギー値$E$を持つ状態である。 古典力学では全エネルギー(運動エネルギーとポテンシャルエネルギー)をハミルトニアン(Hamiltonian) と呼び、
\[H(x,p)=\frac{p^2}{2m}+V(x) \tag{13}\]と定義しますが、したがって$p$を$-i\hbar(\partial/\partial x)$に置き換えると、量子力学におけるハミルトニアン(Hamiltonian)演算子には
\[\hat H = -\frac{\hbar^2}{2m}\frac{\partial^2}{\partial x^2} + V(x) \label{eqn:hamiltonian_op}\tag{14}\]が対応します。したがって、時間に依存しないシュレーディンガー方程式($\ref{eqn:t_independent_schrodinger_eqn}$)は
\[\hat H \psi = E\psi \tag{15}\]と書くことができ、ハミルトニアンの期待値は次のようになります。
\[\langle H \rangle = \int \psi^* \hat H \psi dx = E\int|\psi|^2dx = E\int|\Psi|^2dx = E. \tag{16}\]また、
\[{\hat H}^2\psi = \hat H(\hat H\psi) = \hat H(E\psi) = E(\hat H\psi) = E^2\psi \tag{17}\]が成り立つので
\[\langle H^2 \rangle = \int \psi^*{\hat H}^2\psi dx = E^2\int|\psi|^2dx = E^2 \tag{18}\]であり、したがってハミルトニアン$H$の分散は
\[\sigma_H^2 = \langle H^2 \rangle - {\langle H \rangle}^2 = E^2 - E^2 = 0 \tag{19}\]です。つまり、変数分離解は全エネルギーを測定したとき、常に一定の値$E$として測定されます。
3. 時間依存シュレーディンガー方程式の一般解は変数分離解の線形結合である。 時間に依存しないシュレーディンガー方程式($\ref{eqn:t_independent_schrodinger_eqn}$)は無限に多くの解$[\psi_1(x),\psi_2(x),\psi_3(x),\dots]$を持ちます。これを{$\psi_n(x)$}とします。これらそれぞれに対して分離定数$E_1,E_2,E_3,\dots=${$E_n$}が存在するので、それぞれの可能なエネルギー準位 に対応する波動関数があります。
\[\Psi_1(x,t)=\psi_1(x)e^{-iE_1t/\hbar},\quad \Psi_2(x,t)=\psi_2(x)e^{-iE_2t/\hbar},\ \dots \tag{20}\]時間依存シュレーディンガー方程式($\ref{eqn:schrodinger_eqn}$)は任意の二つの解を線形結合しても解になるという性質があるので、一旦変数分離解を見つければすぐにより一般的な形の解である
\[\Psi(x,t) = \sum_{n=1}^\infty c_n\psi_n(x)e^{-iE_nt/\hbar} = \sum_{n=1}^\infty c_n\Psi_n(x,t) \label{eqn:general_solution}\tag{21}\]を得ることができます。すべての時間依存シュレーディンガー方程式の解を上の形で書くことができ、あとは問題で与えられた初期条件を満たすように適切な定数$c_1, c_2, \dots$を求めて知りたい特殊解を見つけるだけです。つまり、一旦時間に依存しないシュレーディンガー方程式を解くことができれば、その後時間依存シュレーディンガー方程式の一般解を求めることは簡単にできます。
変数分離された解
\[\Psi_n(x,t) = \psi_n(x)e^{-iEt/\hbar}\]はすべての確率と期待値が時間に依存しない定常状態ですが、式($\ref{eqn:general_solution}$)の一般解はこのような性質を持たないことに注意してください。
エネルギー保存 一般解($\ref{eqn:general_solution}$)において係数{$c_n$}の絶対値の二乗$|c_n|^2$は物理的にその状態($\Psi$)を持つ粒子のエネルギーを測定したとき$E_n$値が出る確率を意味します。したがって、この確率の和は
\[\sum_{n=1}^\infty |c_n|^2=1 \tag{22}\]で1になるはずであり、ハミルトニアンの期待値は
\[\langle H \rangle = \sum_{n=1}^\infty |c_n|^2E_n \tag{23}\]です。ここで各定常状態のエネルギー準位$E_n$と係数{$c_n$}が時間に依存しないので、特定のエネルギー$E_n$が測定される確率やハミルトニアン$H$の期待値も時間に依存せず一定の値を持ちます。
]]>