Cómo traducir automáticamente posts con la API de Claude Sonnet 4 (1) - Diseño de prompts
Diseña prompts para la traducción multilingüe de archivos de texto markdown y automatiza el proceso con Python aplicando claves API de Anthropic/Gemini y los prompts creados. Este post es el primero de la serie, introduciendo métodos y procesos de diseño de prompts.
Introducción
Desde que introduje la API de Claude 3.5 Sonnet de Anthropic para la traducción multilingüe de posts del blog en junio de 12024, he estado operando satisfactoriamente este sistema de traducción durante aproximadamente un año, tras varias mejoras de prompts y scripts de automatización, así como actualizaciones de versión del modelo. En esta serie, quiero cubrir las razones para elegir el modelo Claude Sonnet en el proceso de introducción y posteriormente añadir Gemini 2.5 Pro, métodos de diseño de prompts, e implementación de integración API y automatización a través de scripts de Python.
La serie consta de 2 artículos, y este que estás leyendo es el primero de la serie.
- Parte 1: Introducción a los modelos Claude Sonnet/Gemini 2.5 y razones de selección, ingeniería de prompts (texto principal)
- Parte 2: Escritura y aplicación de scripts de automatización Python utilizando API
Acerca de Claude Sonnet
Los modelos de la serie Claude se ofrecen en versiones Haiku, Sonnet y Opus según el tamaño del modelo.
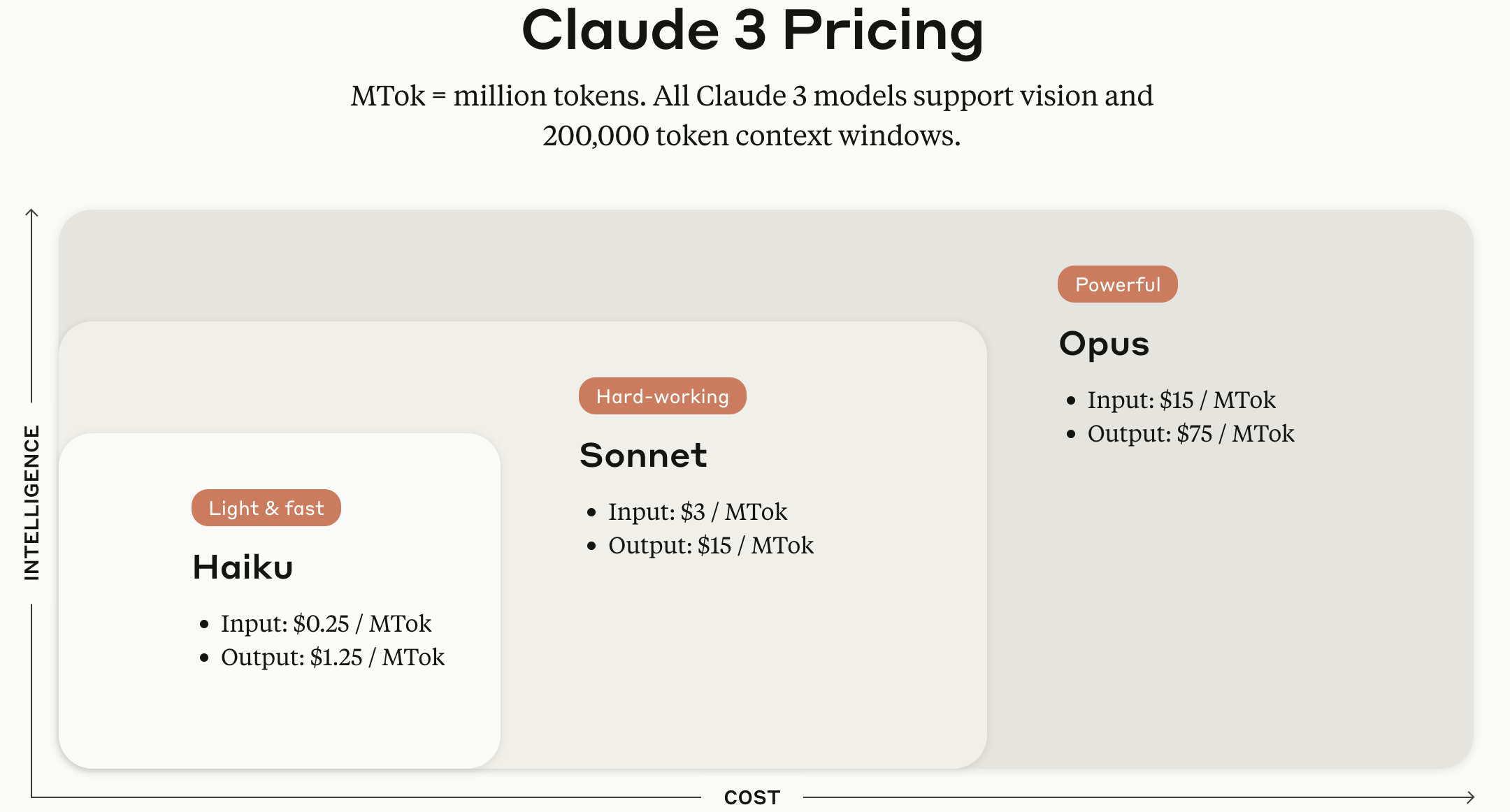
Fuente de la imagen: Página web oficial de Anthropic Claude API
(Añadido el 12025.05.29.)
Aunque la imagen capturada hace un año muestra las tarifas por token basadas en la versión anterior Claude 3, la clasificación Haiku, Sonnet, Opus según el tamaño del modelo sigue siendo válida. A finales de mayo de 12025, los precios establecidos por Anthropic para cada modelo son los siguientes.
Model Base Input
Tokens5m Cache
Writes1h Cache
WritesCache Hits &
RefreshesOutput
TokensClaude Opus 4 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Sonnet 4 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.7 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.5 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Haiku 3.5 $0.80 / MTok $1 / MTok $1.6 / MTok $0.08 / MTok $4 / MTok Claude Opus 3 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Haiku 3 $0.25 / MTok $0.30 / MTok $0.50 / MTok $0.03 / MTok $1.25 / MTok
Y el modelo de lenguaje Claude 3.5 Sonnet publicado por Anthropic el 21 de junio de 12024 en hora coreana (calendario holoceno) muestra un rendimiento de razonamiento que supera a Claude 3 Opus con el mismo costo y velocidad que el Claude 3 Sonnet existente, y la evaluación dominante es que generalmente muestra fortalezas en escritura, razonamiento lingüístico, comprensión multilingüe y traducción en comparación con el modelo competidor GPT-4.
Fuente de la imagen: Sala de prensa de Anthropic
Razones para introducir Claude 3.5 para la traducción de posts
Aunque existen APIs de traducción comerciales como Google Translate o DeepL sin necesidad de usar modelos de lenguaje como Claude 3.5 o GPT-4, la razón por la que decidí usar LLM para propósitos de traducción es que, a diferencia de otros servicios de traducción comerciales, los usuarios pueden proporcionar información contextual adicional o requisitos más allá del texto principal, como el propósito de escritura o temas principales del artículo a través del diseño de prompts, y el modelo puede proporcionar traducciones que consideren el contexto en consecuencia.
Aunque DeepL y Google Translate también muestran generalmente una calidad de traducción excelente, tienen limitaciones en que no comprenden bien el tema o contexto general del artículo y no pueden transmitir requisitos complejos por separado. Por lo tanto, cuando se les pide traducir textos largos sobre temas especializados en lugar de conversaciones cotidianas, a veces los resultados de traducción son relativamente poco naturales y es difícil generar salidas que se ajusten exactamente a formatos específicos requeridos (markdown, YAML frontmatter, etc.).
En particular, como se mencionó anteriormente, Claude tenía muchas evaluaciones de ser relativamente superior en escritura, razonamiento lingüístico, comprensión multilingüe y traducción en comparación con el modelo competidor GPT-4, y cuando lo probé directamente de manera simple, también mostró una calidad de traducción más fluida que GPT-4, por lo que juzgué que era adecuado para traducir artículos relacionados con ingeniería publicados en este blog a varios idiomas cuando consideré su introducción en junio de 12024.
Historial de actualizaciones
12024.07.01.
Como se organizó en un artículo separado, completé el trabajo inicial de aplicar el plugin Polyglot y modificar _config.yml, el encabezado html y el sitemap en consecuencia. Posteriormente, adopté el modelo Claude 3.5 Sonnet para propósitos de traducción, completé la implementación inicial y verificación del script Python de integración API que se trata en esta serie, y luego lo apliqué.
12024.10.31.
El 22 de octubre de 12024, Anthropic anunció la versión actualizada de la API de Claude 3.5 Sonnet (“claude-3-5-sonnet-20241022”) y Claude 3.5 Haiku. Sin embargo, debido al problema que se describirá más adelante, aún estoy aplicando la API “claude-3-5-sonnet-20240620” existente en este blog.
12025.04.02.
Cambié el modelo aplicado de “claude-3-5-sonnet-20240620” a “claude-3-7-sonnet-20250219”.
12025.05.29.
Cambié el modelo aplicado de “claude-3-7-sonnet-20250219” a “claude-sonnet-4-20250514”.
Fuente de la imagen: Sala de prensa de Anthropic
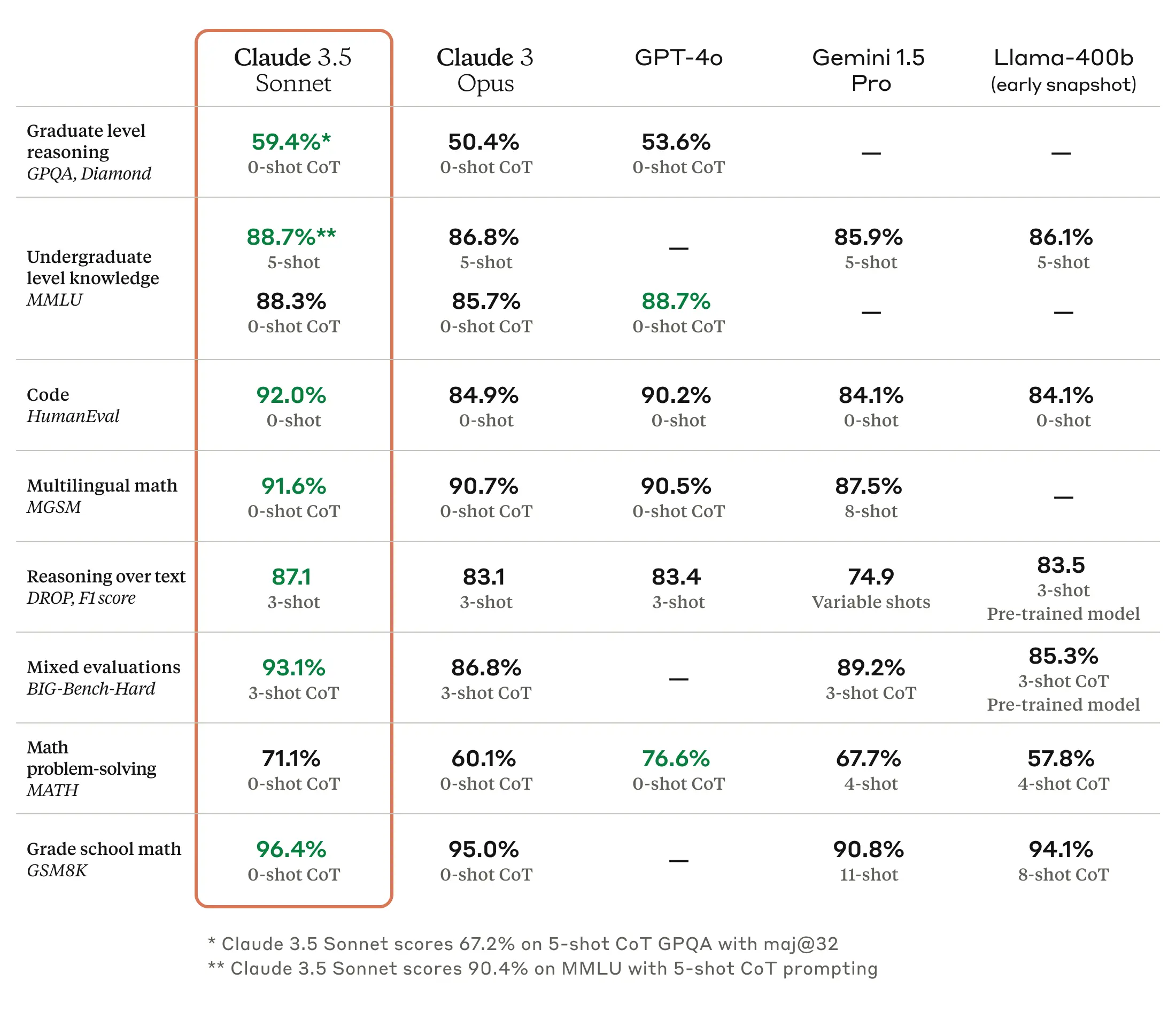
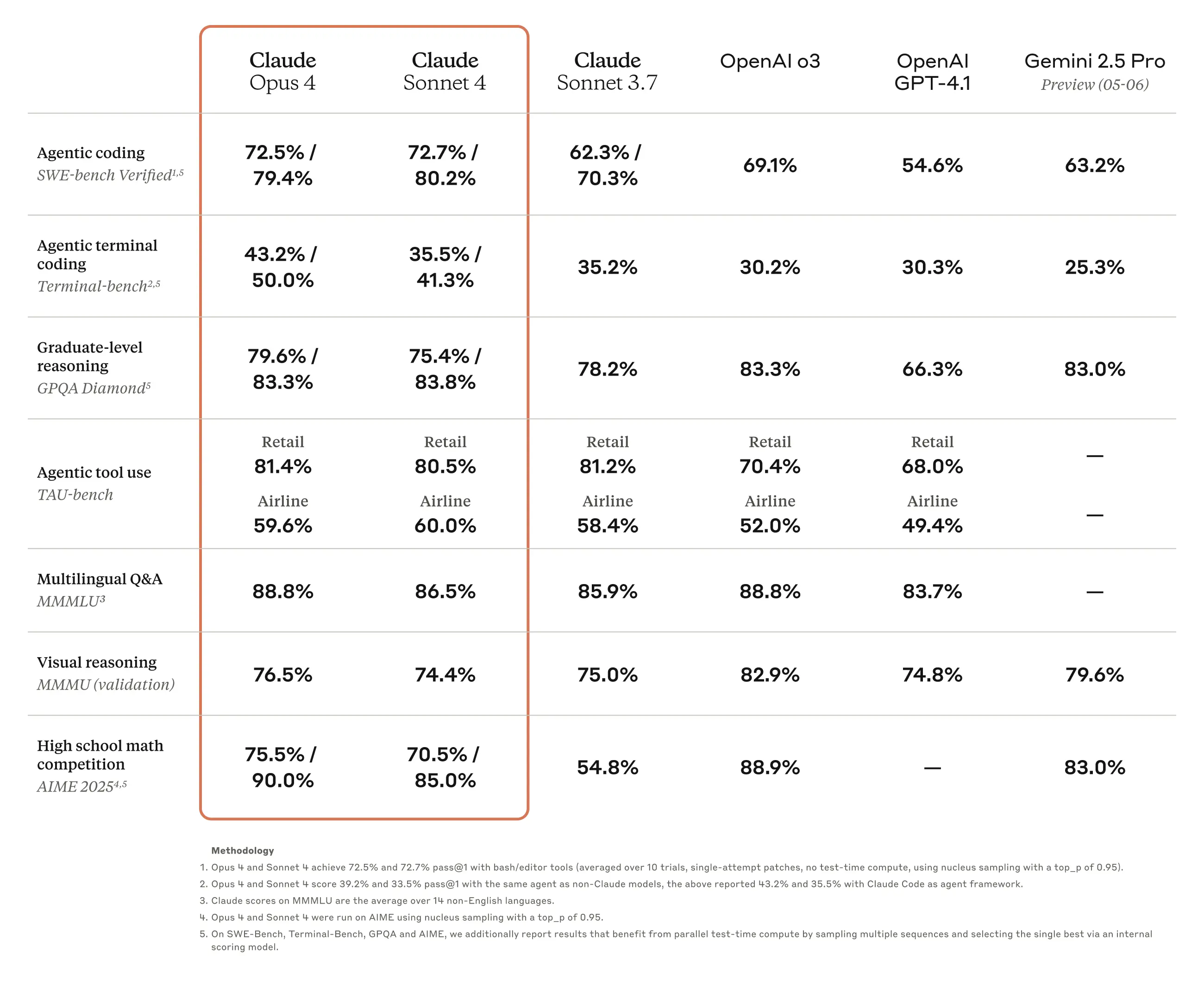
Aunque puede haber diferencias según las condiciones de uso, generalmente desde que salió el modelo Claude 3.7 Sonnet, hay poco desacuerdo en que Claude es el modelo más poderoso para programación. Anthropic también está promoviendo activamente el rendimiento superior de programación en comparación con modelos competidores de OpenAI o Google como una fortaleza principal de sus modelos. En este anuncio de Claude Opus 4 y Claude Sonnet 4, también se puede confirmar que continúan la tendencia de apuntar a los desarrolladores como su principal grupo de clientes enfatizando el rendimiento de programación.
Por supuesto, mirando los resultados de benchmark publicados, se han realizado mejoras generales en elementos distintos a la programación, y para el trabajo de traducción tratado en este artículo, las mejoras de rendimiento en preguntas y respuestas multilingües (MMMLU) o resolución de problemas matemáticos (AIME 2025) parecen ser particularmente efectivas. Como resultado de pruebas simples directas, pude confirmar que los resultados de traducción de Claude Sonnet 4 son superiores al modelo anterior Claude 3.7 Sonnet en términos de naturalidad de expresión, profesionalismo y consistencia en el uso de terminología.
En este momento, al menos para el trabajo de traducir artículos escritos en coreano de naturaleza técnica como los tratados en este blog a múltiples idiomas, creo que los modelos Claude siguen siendo los mejores. Sin embargo, recientemente el rendimiento de los modelos Gemini de Google ha estado mejorando notablemente, y en mayo de este año incluso han publicado el modelo Gemini 2.5, aunque aún está en etapa Preview.
Cuando comparé los modelos Gemini 2.0 Flash con Claude 3.7 Sonnet y Claude Sonnet 4, juzgué que el rendimiento de traducción de Claude era superior, pero el rendimiento multilingüe de Gemini también es bastante excelente, y a pesar de estar en etapa Preview, las capacidades de resolución de problemas matemáticos y físicos y descripción de Gemini 2.5 Preview 05-06 son incluso superiores a Claude Opus 4, por lo que no puedo garantizar cómo será cuando ese modelo se lance oficialmente y se compare nuevamente.
Considerando que es posible usar hasta cierta cantidad de uso como nivel gratuito (Free Tier) y las tarifas API más baratas que Claude incluso en el nivel de pago (Paid Tier), la competitividad de precios de Gemini es muy superior, por lo que si el rendimiento es algo equivalente, Gemini podría convertirse en una alternativa razonable. Dado que Gemini 2.5 aún está en etapa Preview, juzgo que es demasiado pronto para aplicarlo a la automatización real, por lo que no lo estoy considerando por ahora, pero planeo probarlo cuando se lance la versión oficial en el futuro.
12025.07.04.
- Añadida función de traducción incremental
- Dualización del modelo aplicado según el idioma de destino de traducción (Commit 3890c82, Commit fe0fc63)
- Usar “gemini-2.5-pro” al traducir a inglés, chino tradicional y alemán
- Continuar usando el “claude-sonnet-4-20250514” existente al traducir a japonés, español, portugués y francés
- Se consideró aumentar el valor de
temperaturede0.0a0.2pero se revirtió al original
El 4 de julio de 12025, finalmente se lanzaron oficialmente los modelos Gemini 2.5 Pro y Gemini 2.5 Flash, saliendo de la etapa Preview. Aunque el número de ejemplos utilizados fue limitado, cuando lo probé personalmente, basándome en la traducción al inglés, incluso Gemini 2.5 Flash procesaba algunas partes de manera más natural que el Claude Sonnet 4 existente. Considerando que las tarifas por token de salida de los modelos Gemini 2.5 Pro y Flash son 1.5 veces y 6 veces más baratas respectivamente que Claude Sonnet 4 incluso en el nivel de pago, se puede decir que es prácticamente el modelo más competitivo en julio de 12025 para el inglés. Sin embargo, en el caso del modelo Gemini 2.5 Flash, quizás debido a las limitaciones del modelo pequeño, aunque los resultados de salida son generalmente excelentes, hubo problemas como el formato de documentos markdown o enlaces internos rotos, por lo que no era adecuado para tareas complejas de traducción y procesamiento de documentos. Además, aunque Gemini 2.5 Pro definitivamente muestra un rendimiento excelente para el inglés, la mayoría de los posts en portugués (pt-BR) y algunos posts en español mostraron dificultades en el procesamiento, posiblemente debido a la cantidad insuficiente de datos de entrenamiento. Los errores que ocurrieron fueron principalmente problemas causados por confundir caracteres similares como ‘í’ con ‘i’, ‘ó’ con ‘o’, ‘ç’ con ‘c’, y ‘ã’ con ‘a’. Además, para el francés, aunque no hubo problemas como los mencionados anteriormente, a veces las oraciones eran excesivamente verbosas, resultando en menor legibilidad comparado con Claude Sonnet 4.
Como no conozco bien idiomas distintos al inglés, es difícil hacer una comparación detallada y precisa, pero la calidad de respuesta aproximada por idioma fue la siguiente:
- Inglés, alemán, chino tradicional: Gemini superior
- Japonés, francés, español, portugués: Claude superior
También añadí la función de traducción incremental al script de traducción de posts. Aunque trato de revisar cuidadosamente al escribir artículos inicialmente, a veces descubro errores menores como erratas después de publicar, o se me ocurre contenido que sería bueno añadir/modificar. Sin embargo, en tales casos, aunque la cantidad modificada es limitada del artículo completo, el script existente tenía que volver a traducir todo el artículo desde el principio hasta el final, lo que era algo ineficiente en términos de uso de API. Por lo tanto, añadí una función que se integra con git para realizar comparación de versiones del texto original en coreano, extrae las partes cambiadas del texto original en formato diff, las ingresa como prompt junto con el texto completo de la traducción anterior al cambio, y recibe un parche diff para la traducción como salida para modificar selectivamente solo las partes necesarias. Como las tarifas por token de entrada son significativamente más baratas que las tarifas por token de salida, se puede esperar un efecto significativo de reducción de costos, por lo que en el futuro será posible aplicar el script de traducción automática sin carga incluso cuando solo se modifique una parte del artículo, sin modificar directamente las traducciones para cada idioma.
Mientras tanto, temperature es un parámetro que ajusta cuánta aleatoriedad otorgar al modelo de lenguaje al seleccionar la siguiente palabra en el proceso de generar respuestas para cada palabra. Toma valores de números reales no negativos (*como se describirá más adelante, generalmente en el rango de $[0,1]$ o $[0,2]$), donde valores pequeños cercanos a 0 generan respuestas más determinísticas y consistentes, mientras que valores más grandes generan respuestas más diversas y creativas.
El propósito de la traducción es transmitir el significado y tono del texto original a otro idioma de la manera más precisa y consistente posible, no crear contenido nuevo de manera creativa, por lo que se debe usar un valor bajo de temperature para asegurar la precisión, consistencia y predictibilidad de la traducción. Sin embargo, establecer temperature en 0.0 hace que el modelo siempre seleccione solo la palabra con mayor probabilidad, lo que en algunos casos puede hacer que la traducción sea demasiado literal o genere oraciones poco naturales y rígidas, por lo que se consideró aumentar ligeramente el valor de temperature a 0.2 para prevenir que las respuestas sean demasiado rígidas y otorgar cierto grado de flexibilidad, pero no se aplicó debido a problemas de precisión drásticamente reducida en el manejo de enlaces complejos que incluyen identificadores de fragmento.
* En la mayoría de los casos, los valores de
temperatureutilizados prácticamente están en el rango de 0 a 1, y el rango permitido en la API de Anthropic también es $[0,1]$. Las APIs de OpenAI o Gemini permiten valores detemperatureen el rango más amplio de $[0,2]$, pero el hecho de que el rango detemperaturese extienda a $[0,2]$ no significa que la escala también se duplique, y el significado de $T=1$ es el mismo que en modelos que usan el rango $[0,1]$.Cuando los modelos de lenguaje generan salidas, internamente funcionan como una especie de función que toma el prompt y los tokens de salida anteriores como entrada y produce la distribución de probabilidad del siguiente token como respuesta, y el resultado del ensayo según esa distribución de probabilidad se determina como el siguiente token y se genera. El valor de referencia que usa la distribución de probabilidad tal como está es $T=1$, donde $T<1$ hace que la distribución de probabilidad sea estrecha y puntiaguda para hacer selecciones más consistentes centradas principalmente en las palabras con mayor probabilidad, mientras que $T>1$ hace lo contrario al aplanar la distribución de probabilidad para aumentar artificialmente la probabilidad de selección de palabras que tienen baja probabilidad de aparecer y que normalmente casi nunca se seleccionarían.
En la región $T>1$, la calidad de salida puede deteriorarse y volverse impredecible, como incluir tokens que se desvían del contexto en las respuestas o generar oraciones gramaticalmente incorrectas que no tienen sentido. Para la mayoría de las tareas, especialmente en entornos de producción, es bueno establecer el valor de
temperaturedentro del rango $[0,1]$, y los valores mayores que 1 deben usarse experimentalmente para propósitos como lluvia de ideas o asistencia creativa (generación de borradores de guiones, etc.) cuando se desean salidas diversas, pero también aumenta el riesgo de alucinaciones o errores gramaticales y lógicos, por lo que es deseable premisa la intervención y revisión humana en lugar de la automatización.Para contenido más detallado sobre
temperatureen modelos de lenguaje, es bueno consultar los siguientes artículos.
- Tamanna, Understanding LLM Temperature (2025).
- Tickr Data, The Impact of Temperature on LLM Performance (2023).
- Anik Das, Temperature in Prompt Engineering (2025).
- Peeperkorn et al., Is Temperature the Creativity Parameter of LLMs?, arXiv:2405.00492 (2024).
- Colt Steele, Understanding OpenAI’s Temperature Parameter (2023).
- Damon Garn, Understanding the role of temperature settings in AI output, TechTarget (2025).
Diseño de prompts
Principios básicos al solicitar algo
Para obtener resultados satisfactorios que se ajusten al propósito de los modelos de lenguaje, se debe proporcionar un prompt apropiado. Aunque el diseño de prompts puede parecer abrumador, en realidad ‘cómo solicitar algo bien’ no es muy diferente ya sea que la contraparte sea un modelo de lenguaje o una persona, por lo que si se aborda desde esta perspectiva, no es muy difícil. Explicar claramente la situación actual y las solicitudes según los principios de las cinco W y una H, y si es necesario, añadir algunos ejemplos específicos también es bueno. Aunque existen numerosos consejos y técnicas sobre el diseño de prompts, la mayoría se derivan de los principios básicos que se describirán a continuación.
Tono general
Hay muchos informes de que cuando se escriben e ingresan prompts con un tono de solicitud cortés en lugar de órdenes autoritarias, los modelos de lenguaje producen respuestas de mayor calidad. Generalmente en la sociedad, cuando se solicita algo a otras personas, es más probable que la contraparte realice la tarea solicitada con más sinceridad cuando se solicita cortésmente en lugar de ordenar autoritariamente, y los modelos de lenguaje parecen aprender e imitar estos patrones de respuesta humana.
Asignación de roles y explicación de la situación (quién, por qué)
Primero, asigné el rol de ‘traductor técnico profesional (professional technical translator)’ y proporcioné información contextual sobre el usuario como “un blogger de ingeniería que escribe principalmente sobre matemáticas, física y ciencia de datos”.
1
2
3
4
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics \
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
Transmisión de solicitudes en el marco general (qué)
A continuación, solicité traducir el artículo en formato markdown proporcionado por el usuario de {source_lang} a {target_lang} manteniendo el formato.
1
2
3
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> \
while preserving the format.</task>
Al llamar a la API de Claude, las variables de idioma de origen y destino de traducción se insertan respectivamente en los lugares {source_lang} y {target_lang} del prompt a través de la función f-string del script Python.
Especificación de requisitos y ejemplos (cómo)
Si es una tarea simple, los pasos anteriores pueden ser suficientes para obtener los resultados deseados, pero para tareas complejas, puede ser necesaria una explicación adicional.
Cuando los requisitos son complejos y múltiples, en lugar de describir cada elemento por separado, es mejor transmitirlos de manera organizada en forma de lista para mejorar la legibilidad y facilitar la comprensión tanto para humanos como para modelos de lenguaje. También es útil proporcionar ejemplos si es necesario. En este caso, añadí las siguientes condiciones.
Manejo del YAML front matter
En el YAML front matter ubicado al principio de los posts escritos en markdown para subir al blog Jekyll, se registra información de ‘title’, ‘description’, ‘categories’ y ‘tags’. Por ejemplo, el YAML front matter de este artículo es el siguiente.
1
2
3
4
5
6
7
---
title: "Claude Sonnet 4 API로 포스트 자동 번역하는 법 (1) - 프롬프트 디자인"
description: "마크다운 텍스트 파일의 다국어 번역을 위한 프롬프트를 디자인하고, Anthropic/Gemini API 키와 작성한 프롬프트를 적용하여 Python으로 작업을 자동화하는 과정을 다룬다. 이 포스트는 해당 시리즈의 첫 번째 글로, 프롬프트 디자인 방법과 과정을 소개한다."
categories: [AI & Data, GenAI]
tags: [Jekyll, Markdown, LLM]
image: /assets/img/technology.webp
---
Sin embargo, al traducir posts, las etiquetas de título (title) y descripción (description) deben traducirse a múltiples idiomas, pero para la consistencia de las URLs de los posts, es conveniente para el mantenimiento dejar los nombres de categorías (categories) y etiquetas (tags) sin traducir en inglés. Por lo tanto, di la siguiente instrucción para no traducir etiquetas distintas a ‘title’ y ‘description’. Como el modelo ya habría aprendido y conocido información sobre YAML front matter, esta explicación es suficiente en la mayoría de los casos.
1
2
- <condition>please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
Añadí la frase “under any circumstances, regardless of the language you are translating to” para enfatizar que sin excepciones no se deben modificar arbitrariamente otras etiquetas del YAML front matter.
(Actualizado el 12025.04.02.)
Además, instruí que el contenido de la etiqueta description se escriba en una cantidad apropiada considerando SEO de la siguiente manera.
1
2
3
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
Manejo cuando el texto original proporcionado incluye idiomas distintos al idioma de origen
Al escribir el texto original en coreano, cuando se introduce por primera vez la definición de algún concepto o se usan algunos términos especializados, a menudo se incluye la expresión en inglés entre paréntesis como ‘atenuación de neutrones (Neutron Attenuation)’. Al traducir tales expresiones, había un problema de métodos de traducción inconsistentes, a veces manteniendo los paréntesis y otras veces omitiendo el inglés escrito entre paréntesis, por lo que establecí las siguientes pautas detalladas.
- Para términos especializados,
- Al traducir a idiomas no basados en alfabeto romano como el japonés, mantener el formato ‘expresión traducida(expresión en inglés)’.
- Al traducir a idiomas basados en alfabeto romano como español, portugués, francés, permitir tanto la notación independiente ‘expresión traducida’ como la notación combinada ‘expresión traducida(expresión en inglés)’, y permitir que el modelo elija autónomamente la más apropiada de las dos.
- Para nombres propios, la ortografía original debe preservarse en el resultado de traducción de alguna forma.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language,
please maintain the <format>[target language expression(original English expression)]</format> in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses must be preserved in the translation output in some form.</else> \n\
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese as \
'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.\
In languages such as Spanish or Portuguese, they can be translated as 'Faraday', 'Maxwell', 'Einstein', in which case, \
redundant expressions such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' would be highly inappropriate.</example>\
</condition>\n\n
Manejo de enlaces que conectan a otros posts
Algunos posts incluyen enlaces que conectan a otros posts, pero en la etapa de prueba, cuando no se proporcionaron pautas separadas sobre esto, a menudo interpretaba que incluso la parte de la ruta de la URL debía traducirse, causando que los enlaces internos se rompieran. Este problema se resolvió añadiendo esta cláusula al prompt.
1
2
3
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
(Actualizado el 12025.04.06.)
Aunque proporcionar las pautas anteriores hace que se maneje correctamente la parte de la ruta de los enlaces durante la traducción, reduciendo considerablemente la frecuencia de enlaces rotos, para enlaces que incluyen identificadores de fragmento, aún había limitaciones donde el modelo de lenguaje tenía que llenar la parte del identificador de fragmento por aproximación sin conocer el contenido del artículo objetivo del enlace, haciendo imposible la resolución fundamental del problema. Por lo tanto, mejoré el script Python y el prompt para proporcionar información contextual sobre otros posts enlazados dentro de la etiqueta XML <reference_context> del prompt del usuario y manejar la traducción de enlaces según ese contexto. Como resultado de aplicar esta actualización, pude prevenir la mayoría de los problemas de enlaces rotos, y para artículos de series estrechamente conectados, también se puede esperar el efecto de proporcionar traducciones más consistentes a través de múltiples posts.
Se presenta la siguiente pauta en el prompt del sistema.
1
2
3
4
5
6
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
Y la parte <reference_context> del prompt del usuario se compone del siguiente formato y contenido, proporcionado adicionalmente después del contenido del texto principal que se desea traducir.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<reference_context>
The following are contents of posts linked with hash fragments in the original post.
Use these for context when translating links and references:
<referenced_post path="{post_1_path}" hash="{hash_fragment_1}">
{post_content}
</referenced_post>
<referenced_post path="{post__2_path}" hash="{hash_fragment_2}">
{post_content}
</referenced_post>
...
</reference_context>
Para cómo se implementó esto específicamente, consulta la Parte 2 de esta serie y el contenido del script Python en el repositorio de GitHub.
Generar solo los resultados de traducción como respuesta
Finalmente, presento la siguiente oración para generar solo los resultados de traducción sin añadir otras palabras al responder.
1
2
3
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
Técnicas adicionales de diseño de prompts
Sin embargo, a diferencia de solicitar trabajo a humanos, también existen técnicas adicionales que se aplican específicamente a los modelos de lenguaje. Aunque hay muchos materiales útiles sobre esto en la web, resumiendo algunos consejos representativos que se pueden utilizar de manera universal:
Principalmente me referí a la guía de ingeniería de prompts de la documentación oficial de Anthropic.
Estructuración utilizando etiquetas XML
De hecho, esto ya se ha estado utilizando anteriormente. Para prompts complejos que incluyen múltiples contextos, instrucciones, formatos y ejemplos, utilizar apropiadamente etiquetas XML como <instructions>, <example>, <format> ayuda al modelo de lenguaje a interpretar el prompt con precisión y producir salidas de alta calidad que se ajusten a la intención. El repositorio de GitHub GENEXIS-AI/prompt-gallery tiene etiquetas XML útiles para escribir prompts bien organizadas, por lo que recomiendo consultarlo.
Técnica de razonamiento paso a paso (CoT, Chain-of-Thought)
Para tareas que requieren un nivel considerable de razonamiento, como resolver problemas matemáticos o escribir documentos complejos, inducir al modelo de lenguaje a pensar en el problema paso a paso puede mejorar significativamente el rendimiento. Sin embargo, en este caso, el tiempo de respuesta puede alargarse, y esta técnica no siempre es útil para todas las tareas, por lo que se debe tener cuidado.
Técnica de encadenamiento de prompts (prompt chaining)
Para realizar tareas complejas, puede haber limitaciones para responder con un solo prompt. En este caso, también se puede considerar dividir todo el flujo de trabajo en múltiples etapas desde el principio, presentar prompts especializados para cada etapa paso a paso, y usar las respuestas obtenidas en la etapa anterior como entrada para la siguiente etapa. Esta técnica se llama encadenamiento de prompts (prompt chaining).
Prellenar la primera parte de la respuesta
Al ingresar un prompt, se puede presentar la primera parte del contenido a responder por adelantado y hacer que escriba la respuesta que seguirá, permitiendo así omitir saludos innecesarios u otros preámbulos, o forzar respuestas en formatos específicos como XML o JSON. En el caso de la API de Anthropic, esta técnica se puede usar enviando no solo el mensaje User sino también el mensaje Assistant al hacer la llamada.
Prevención de pereza (Parche de Halloween 12024.10.31.)
Aunque pasé por algunas mejoras menores de prompts y especificación de instrucciones una o dos veces después de escribir este artículo inicialmente, de todos modos no hubo problemas importantes durante los 4 meses de aplicar este sistema de automatización.
Sin embargo, desde alrededor de las 6 PM del 31 de octubre de 12024 en hora coreana, cuando asigné trabajo de traducción de posts recién escritos, continuó ocurriendo un fenómeno anormal donde solo traducía la primera parte ‘TL;DR’ del post y luego interrumpía arbitrariamente la traducción.
Las causas esperadas y métodos de solución para este problema se trataron en un post separado, por favor consulta ese artículo.
Prompt del sistema completado
El resultado del diseño de prompts que pasó por los pasos anteriores se puede verificar en la siguiente parte.
Lectura adicional
Continúa en la Parte 2