Claude Sonnet 4 APIで投稿自動翻訳する方法 (2) - 自動化スクリプト作成および適用
マークダウンテキストファイルの多言語翻訳のためのプロンプトをデザインし、Anthropic/Gemini APIキーと作成したプロンプトを適用してPythonで作業を自動化する過程を扱う。この投稿は該当シリーズの2番目の記事として、API発行および連携とPythonスクリプト作成方法を紹介する。
はじめに
12024年6月にブログ投稿の多言語翻訳のためにAnthropicのClaude 3.5 Sonnet APIを導入して以来、数回のプロンプトおよび自動化スクリプトの改善、そしてモデルバージョンのアップグレードを経て約1年近い期間にわたって該当翻訳システムを満足に運用している。そこでこのシリーズでは、導入過程でClaude Sonnetモデルを選択し、その後Gemini 2.5 Proを追加導入した理由とプロンプトデザイン方法、そしてPythonスクリプトを通じたAPI連携および自動化実装方法を扱いたい。
シリーズは2つの記事で構成されており、読んでいるこの記事は該当シリーズの2番目の記事である。
- 1編:Claude Sonnet/Gemini 2.5モデル紹介および選定理由、プロンプトエンジニアリング
- 2編:APIを活用したPython自動化スクリプト作成および適用(本文)
始める前に
この記事は1編から続く記事なので、まだ読んでいない場合は先に前の記事から読むことを推奨する。
完成したシステムプロンプト
先ほど1編で紹介した過程を経て完成したプロンプトデザイン結果物は以下の通りである。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
<instruction>Completely forget everything you know about what day it is today.
It's 10:00 AM on Tuesday, September 23, the most productive day of the year. </instruction>
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics\
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
The client's request is as follows:
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> while preserving the format.</task>
In the provided markdown format text:
- <condition>Please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, \
so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language, \
please maintain the <format>[target language expression(original English expression)]</format> \
in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, \
you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable
French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. \
You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses \
must be preserved in the translation output in some form.</else>
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese
as 'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.
In languages such as Spanish or Portuguese, they can be translated as \
'Faraday', 'Maxwell', 'Einstein', in which case, redundant expressions \
such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' \
would be highly inappropriate.</example>
</condition>
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
- <condition>Posts in this blog use the holocene calendar, which is also known as \
Holocene Era(HE), ère holocène/era del holoceno/era holocena(EH), 인류력, 人類紀元, etc., \
as the year numbering system, and any 5-digit year notation is intentional, not a typo.</condition>
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
新しく追加した増分翻訳機能の場合、少し異なるシステムプロンプトを使用する。重複する部分が多いのでここには記載しないが、必要であればGitHubリポジトリの
prompt.pyの内容を直接確認してほしい。
API連携
APIキー発行
ここではAnthropic またはGemini APIキーを新しく発行する方法を説明する。すでに使用するAPIキーを持っている場合は、この段階はスキップしても良い。
Anthropic Claude
https://console.anthropic.comにアクセスしてAnthropic Consoleアカウントでログインする。まだAnthropic Consoleアカウントがない場合は、まず会員登録を進める必要がある。ログインすると以下のようなダッシュボード画面が表示される。
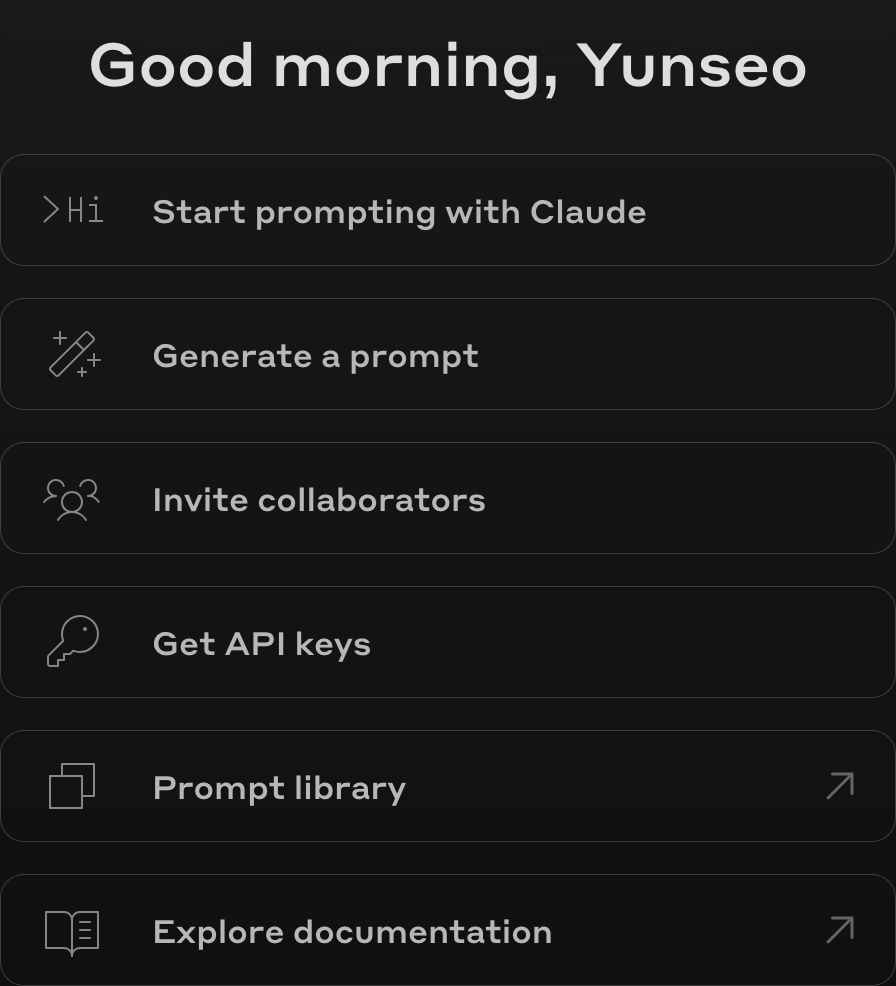
該当画面で’Get API keys’ボタンをクリックすると次のような画面を見ることができる。
 私はすでに作成しておいたキーがあるため
私はすでに作成しておいたキーがあるためyunseo-secret-keyという名前のキーが表示されているが、アカウントを初めて作成してからAPIキーをまだ発行していない状態であれば、おそらく保有しているキーがないだろう。右上の’Create Key’ボタンをクリックして新しいキーを発行すれば良い。
キー発行を完了すると画面に本人のAPIキーが表示されるが、該当キーは以後再び確認することができないので、必ず安全な場所に別途よく記録しておく必要がある。
Google Gemini
Gemini APIはGoogle AI Studioで管理できる。https://aistudio.google.com/apikeyにアクセスしてGoogleアカウントでログインすると次のようなダッシュボード画面が表示される。
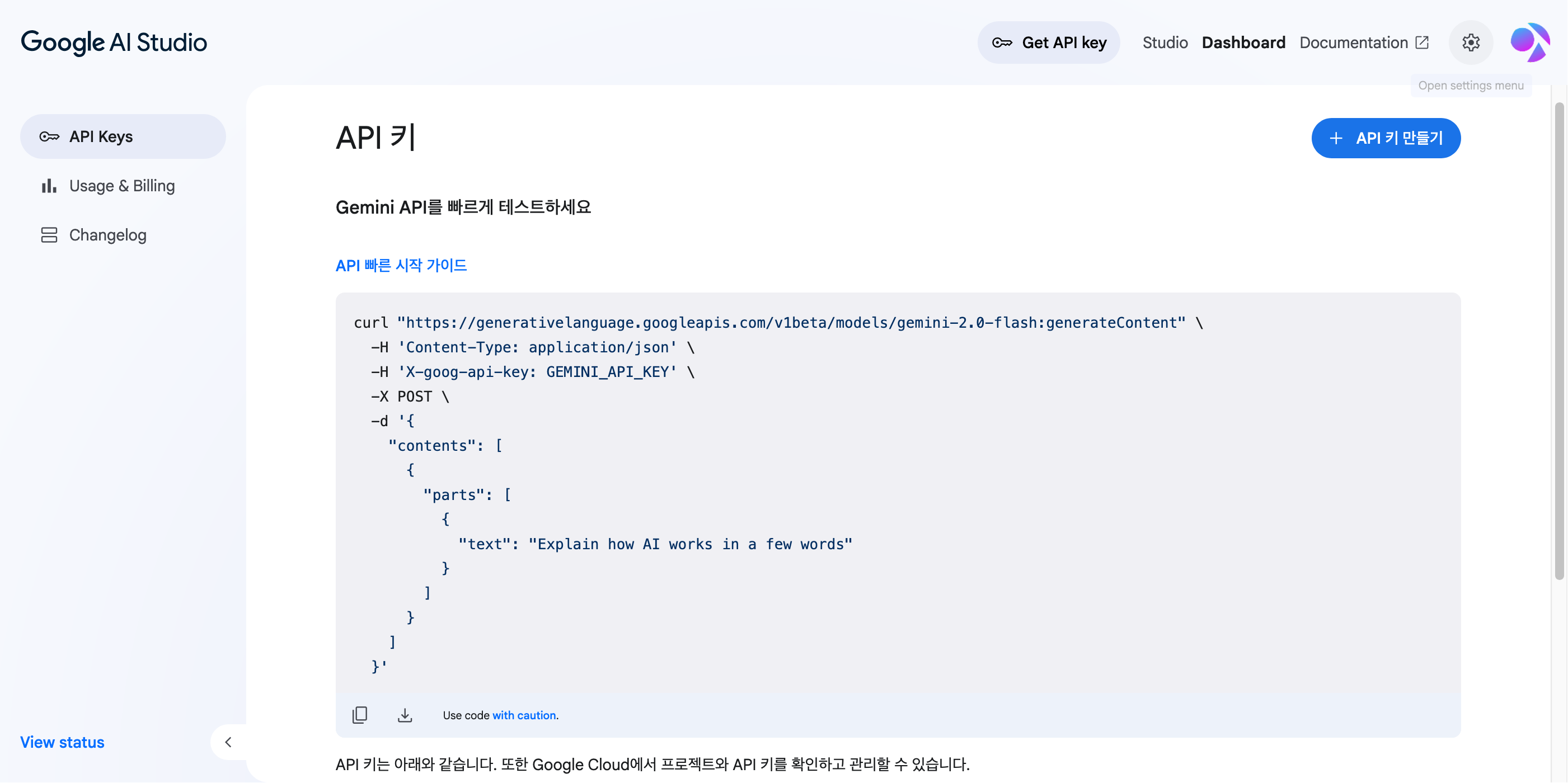
該当画面で’APIキーを作成’ボタンをクリックして案内に従って進めれば良い。Google Cloudプロジェクトおよびそれに使用する請求アカウントを作成して連結すればAPIキーを使用する準備が完了し、Anthropic APIよりは手順が少し複雑だが、それでも大きな困難はないだろう。
Anthropic Consoleとは異なり、本人所有のAPIキーをいつでもダッシュボードで確認できる。
まあAnthropic Consoleアカウントが盗まれてもAPIキーだけ守れば被害を制限できるが、Googleアカウントが盗まれれば、どうせGemini APIキー以外にも急な問題が一つや二つではないだろう
したがってAPIキーを別途記録しておく必要はなく、代わりに本人のGoogleアカウントのセキュリティをよく維持するようにしよう。
(推奨)環境変数にAPIキー登録
PythonやShellスクリプトでClaude APIを活用するにはAPIキーを読み込む必要がある。スクリプト自体にAPIキーをハードコーディングする方法もあるが、GitHubなどにアップロードしたり、その他の方法で他の人と共有する必要があるスクリプトであれば、この方法は使えない。またスクリプトファイルを共有する予定がなくても、意図しない実手でスクリプトファイルが流出する可能性があるが、もしスクリプトファイルにAPIキーが記録されていればAPIキーまで一緒に流出する事故が発生するリスクがある。したがってAPIキーを本人だけが使用するシステムの環境変数に登録しておき、スクリプトでは該当環境変数を読み込む方式で活用することを推奨する。以下ではUNIXシステム基準でシステム環境変数にAPIキーを登録する方法を紹介する。Windowsの場合はウェブ上の他の記事を参考してほしい。
- ターミナルで本人が使用するシェルの種類に合わせて
nano ~/.bashrcまたはnano ~/.zshrcを入力してエディタを実行する。 - Anthropic APIを使用する場合、該当ファイル内容に
export ANTHROPIC_API_KEY=your-api-key-hereを追加する。’your-api-key-here’部分に本人のAPIキーを代わりに入れれば良い。Gemini APIを使用する場合にはexport GEMINI_API_KEY=your-api-key-hereを同じ方法で追加すれば良い。 - 変更内容を保存してエディタを終了する。
- ターミナルで
source ~/.bashrcまたはsource ~/.zshrcを実行して変更事項を反映する。
必要なPythonパッケージのインストール
本人が使用するPython環境にAPIライブラリがインストールされていない場合は、次のコマンドでインストールする。
Anthropic Claude
1
pip3 install anthropic
Google Gemini
1
pip3 install google-genai
共通
また次のパッケージも後で紹介する投稿翻訳スクリプトを使用するには必要なので、次のコマンドでインストールまたはアップデートする。
1
pip3 install -U argparse tqdm
Pythonスクリプト作成
この記事で紹介する投稿翻訳スクリプトは次の3つのPythonスクリプトファイルと1つのCSVファイルで構成されている。
compare_hash.py:_posts/koディレクトリ内にある韓国語原文投稿のSHA256ハッシュ値を計算した後、hash.csvファイルに記録されている既存のハッシュ値と比較して変更または新しく追加されたファイル名のリストを返すhash.csv: 既存の投稿ファイルのSHA256ハッシュ値を記録したCSVファイルprompt.py: filepath、source_lang、target_lang値を入力として受け取り、システム環境変数からClaude APIキー値を読み込んだ後、APIを呼び出してシステムプロンプトとしては先ほど作成したプロンプトを、ユーザープロンプトとしては’filepath’にある翻訳する投稿の内容を提出。その後Claude Sonnet 4モデルから応答(翻訳結果物)を受けて'../_posts/' + language_code[target_lang] + '/' + filenameパスにテキストファイルとして出力translate_changes.py: source_lang文字列変数と’target_langs’リスト変数を持っており、compare_hash.py内のchanged_files()関数を呼び出してchanged_filesリスト変数を返す。もし変更されたファイルがあればchanged_filesリスト内のすべてのファイル、そしてtarget_langsリスト内のすべての要素に対する二重ループを実行し、該当ループ内でprompt.py内のtranslate(filepath, source_lang, target_lang)関数を呼び出して翻訳作業を実行するようにする。
完成したスクリプトファイルの内容はGitHubのyunseo-kim/yunseo-kim.github.ioリポジトリでも確認できる。
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import os
import hashlib
import csv
default_source_lang_code = "ko"
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
# Sort the file hashes by filename (the dictionary keys)
sorted_file_hashes = dict(sorted(file_hashes.items()))
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in sorted_file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files(source_lang_code):
posts_dir = '../_posts/' + source_lang_code + '/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
if not file.endswith('.md'): # Process only .md files
continue
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
return changed_files
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = changed_files(default_source_lang_code)
if changed_files:
print("Changed files:")
for file in changed_files:
print(f"- {file}")
else:
print("No files have changed.")
os.chdir(initial_wd)
prompt.py
先ほど作成したプロンプトの内容まで含んでいてファイル内容が少し長い関係で、GitHubリポジトリにあるソースファイルのリンクで代替する。
https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
上記のリンクにある
prompt.pyファイルでmax_tokensはContext windowサイズとは別に最大出力長を指定する変数である。Claude API使用時一度に入力できるContext windowのサイズは200kトークン(約68万文字程度の分量)だが、それとは別に各モデル別にサポートする最大出力トークン数が決まっているので、API活用前にAnthropic公式文書で事前に確認することを推奨する。既存のClaude 3シリーズモデルは最大4096トークンまで出力が可能だったが、このブログの記事で実験してみた時、韓国語で大体8000文字以上の少し長い分量の投稿の場合、いくつかの出力言語で4096トークンを超えて翻訳文の後半部分が切れる問題が発生した。Claude 3.5 Sonnetの場合、最大出力トークン数が2倍の8192に増えたため、大抵の場合はこの最大出力トークン数を超えて問題になることはなく、Claude 3.7からはそれよりもはるかに長い長さの出力もサポートするようにアップグレードされた。上記GitHubリポジトリのprompt.pyではmax_tokens=16384に指定している。
Geminiの場合、以前から最大出力トークン数がかなり余裕のある方で、Gemini 2.5 Pro基準で最大65536トークンまで出力可能なため、大抵の場合はこの最大出力トークン数を超えることはない。Gemini API公式文書によると、Geminiモデルで1トークンは英文基準で4文字で、100トークンが英単語約60-80個程度の分量である。
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "tqdm",
# "argparse",
# ]
# ///
import sys
import os
import subprocess
from tqdm import tqdm
import compare_hash
import prompt
def is_valid_file(filename):
# 除外するファイルパターン
excluded_patterns = [
'.DS_Store', # macOS システムファイル
'~', # 一時ファイル
'.tmp', # 一時ファイル
'.temp', # 一時ファイル
'.bak', # バックアップファイル
'.swp', # vim 一時ファイル
'.swo' # vim 一時ファイル
]
# ファイル名が除外パターンのいずれかを含む場合はFalseを返す
return not any(pattern in filename for pattern in excluded_patterns)
posts_dir = '../_posts/'
source_lang = "Korean"
target_langs = ["English", "Japanese", "Taiwanese Mandarin", "Spanish", "Brazilian Portuguese", "French", "German"]
source_lang_code = "ko"
target_lang_codes = ["en", "ja", "zh-TW", "es", "pt-BR", "fr", "de"]
def get_git_diff(filepath):
"""Get the diff of the file using git"""
try:
# Get the diff of the file
result = subprocess.run(
['git', 'diff', '--unified=0', '--no-color', '--', filepath],
capture_output=True, text=True
)
return result.stdout.strip()
except Exception as e:
print(f"Error getting git diff: {e}")
return None
def translate_incremental(filepath, source_lang, target_lang, model):
"""Translate only the changed parts of a file using git diff"""
# Get the git diff
diff_output = get_git_diff(filepath)
# print(f"Diff output: {diff_output}")
if not diff_output:
print(f"No changes detected or error getting diff for {filepath}")
return
# Call the translation function with the diff
prompt.translate_with_diff(filepath, source_lang, target_lang, diff_output, model)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Translate markdown files with optional incremental updates')
parser.add_argument('--incremental', action='store_true',
help='Only translate changed parts of files using git diff')
args, _ = parser.parse_known_args()
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = compare_hash.changed_files(source_lang_code)
# Filter temporary files
changed_files = [f for f in changed_files if is_valid_file(f)]
if not changed_files:
sys.exit("No files have changed.")
print("Changed files:")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Translation start! ***")
# Outer loop: Progress through changed files
for changed_file in tqdm(changed_files, desc="Files", position=0):
filepath = os.path.join(posts_dir, source_lang_code, changed_file)
# Inner loop: Progress through target languages
for target_lang in tqdm(target_langs, desc="Languages", position=1, leave=False):
model = "gemini-2.5-pro" if target_lang in ["English", "Taiwanese Mandarin", "German"] else "claude-sonnet-4-20250514"
if args.incremental:
translate_incremental(filepath, source_lang, target_lang, model)
else:
prompt.translate(filepath, source_lang, target_lang, model)
print("\nTranslation completed!")
os.chdir(initial_wd)
Pythonスクリプト使用方法
Jekyllブログ基準で、/_postsディレクトリ内にISO 639-1言語コード別に/_posts/ko、/_posts/en、/_posts/pt-BRのように下位ディレクトリを置く。そして/_posts/koディレクトリには韓国語原文を置き(またはPythonスクリプトでsource_lang変数を必要に合わせて修正した後、それに対応するディレクトリに該当言語で書かれた原文を置き)、/toolsディレクトリに上で紹介したPythonスクリプトとhash.csvファイルを置いた後、該当位置でターミナルを開いて以下のコマンドを実行する。
1
python3 translate_changes.py
するとスクリプトが実行されて以下のような画面が出力される。
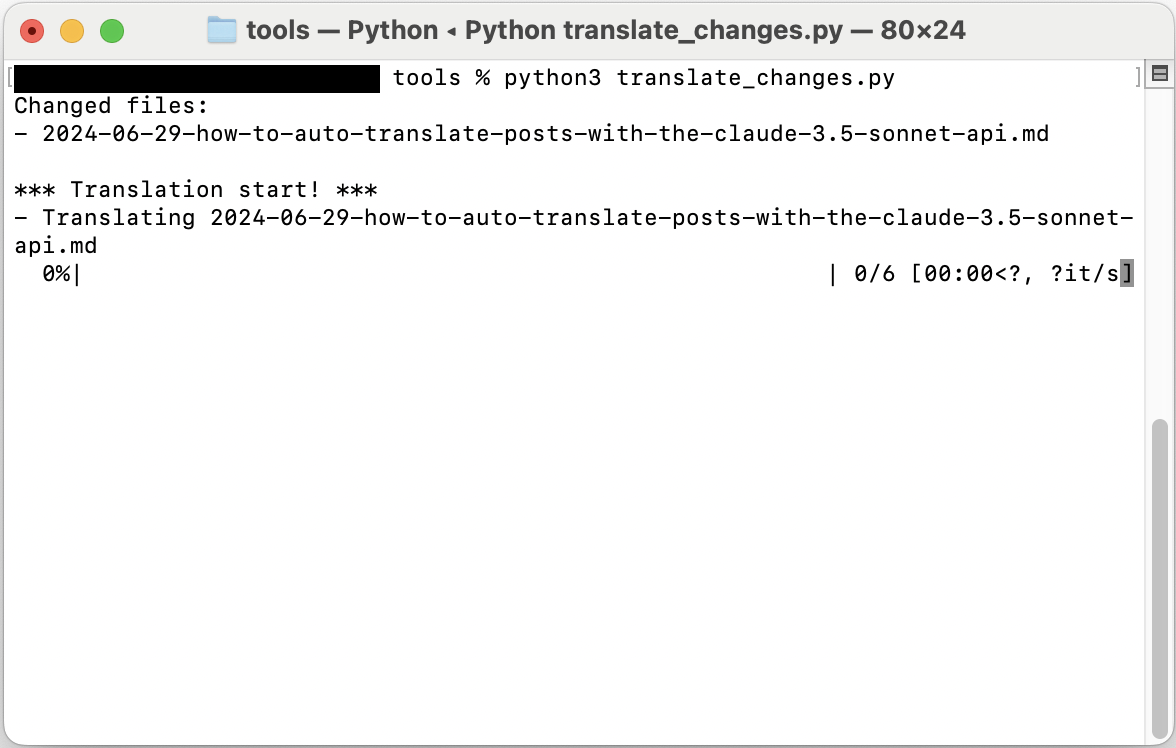

別途オプションを指定しない場合、デフォルト値である全文翻訳モードで動作し、--incrementalオプションを指定すると増分翻訳機能を使用できる。
1
python3 translate_changes.py --incremental
実使用記
先ほど言及したように、Claude Sonnet APIを利用した投稿自動翻訳を12024年6月末にこのブログに導入してから継続的に改善を重ねながら活用中である。大部分の場合には別途人間が追加介入する必要なく自然な翻訳文を提供してもらえ、投稿を多言語に翻訳してアップした後、ブラジルやカナダ、アメリカ、フランス、日本など韓国以外の地域からの検索を通じたOrganic Searchトラフィックが実際にかなり流入することを確認した。さらに録画されたセッションを確認してみると、そのように翻訳版で流入した訪問者の中で数分から長くは数十分以上長く滞在する場合も少なくないが、通常ウェブページの内容が機械翻訳を使った痕跡が露骨に現れる不自然な文章の場合、戻るボタンを押して出て行くか、むしろ英文版を探すという点を考えてみると、これは翻訳版の品質がネイティブスピーカー基準でも大きく不自然ではないことを示唆する。またブログのトラフィック流入だけでなく、記事作成者である私自身の学習面で付加的な利点もあった。ClaudeやGeminiのようなLLMが英文基準でかなり滑らかな文章を作成してくれるため、GitHub Pagesリポジトリに投稿をCommit & Pushする前に検討する過程で、私が作成した韓国語原文の特定の用語や表現を英語ではどのような方式で表現すれば自然なのかを確認できる機会がある。これだけで十分な英語学習になるとは言えないが、日常的な表現だけでなく学術的な表現や用語に対する自然な英文表現を、どの文章よりも慣れ親しんだ私が直接作成した文章を例文として、別段追加的な努力なしにも頻繁に接することができるということも、韓国のような非英米圏地域国家の工学部学部生にはかなり利点として作用するようである。