How to Auto-Translate Posts with the Claude Sonnet 4 API (1) - Prompt Design
Learn how to design effective prompts for multilingual translation of Markdown files and automate the workflow using Python with the Anthropic/Gemini API. This first part of the series details the prompt design process.
Introduction
Since introducing Anthropic’s Claude 3.5 Sonnet API in June 12024 for multilingual translation of my blog posts, I have been successfully operating the translation system for nearly a year, following several improvements to the prompts and automation scripts, as well as model version upgrades. In this series, I will discuss why I chose the Claude Sonnet model and later added Gemini 2.5 Pro, how I designed the prompts, and how I implemented API integration and automation using a Python script.
The series consists of two posts, and you are currently reading the first one.
- Part 1: Introduction to Claude Sonnet/Gemini 2.5 Models, Reasons for Selection, and Prompt Engineering (This Post)
- Part 2: Writing and Applying Python Automation Scripts Using the API
About Claude Sonnet
The Claude series models are offered in Haiku, Sonnet, and Opus versions, depending on the model size.
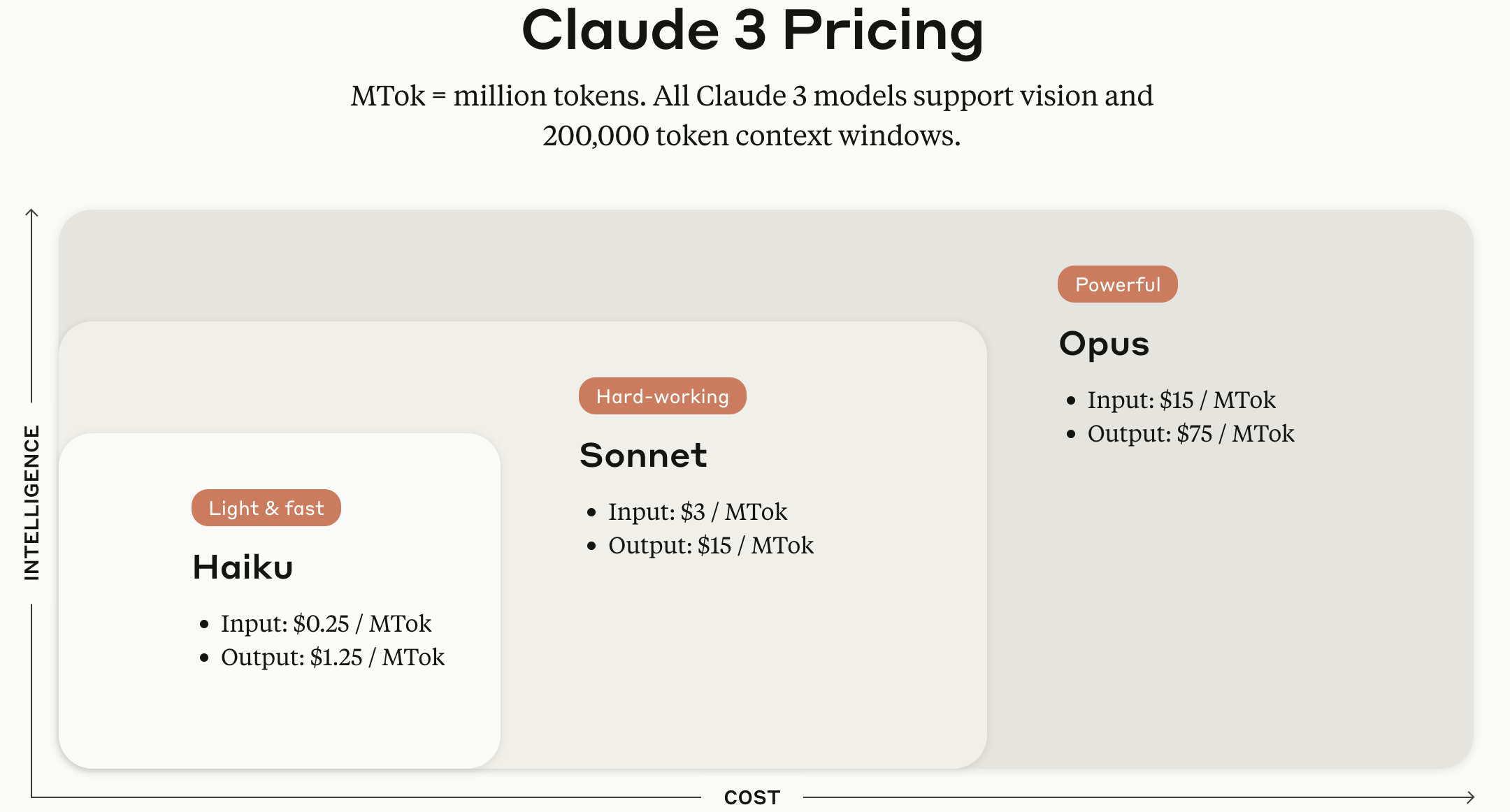
Image source: Official Anthropic Claude API webpage
(Added on 12025.05.29.)
Since this image was captured a year ago, the per-token pricing is based on the older Claude 3 version. However, the Haiku, Sonnet, and Opus tiers based on model size are still valid. As of late May 12025, the pricing for each model provided by Anthropic is as follows.
Model Base Input
Tokens5m Cache
Writes1h Cache
WritesCache Hits &
RefreshesOutput
TokensClaude Opus 4 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Sonnet 4 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.7 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.5 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Haiku 3.5 $0.80 / MTok $1 / MTok $1.6 / MTok $0.08 / MTok $4 / MTok Claude Opus 3 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Haiku 3 $0.25 / MTok $0.30 / MTok $0.50 / MTok $0.03 / MTok $1.25 / MTok Source: Anthropic developer docs
And the language model Claude 3.5 Sonnet, released by Anthropic on June 21, 12024, KST (Holocene calendar), demonstrates reasoning performance surpassing Claude 3 Opus at the same cost and speed as the original Claude 3 Sonnet. The prevailing view is that it generally shows strengths over its competitor, GPT-4, in areas such as writing, language reasoning, and multilingual understanding and translation.
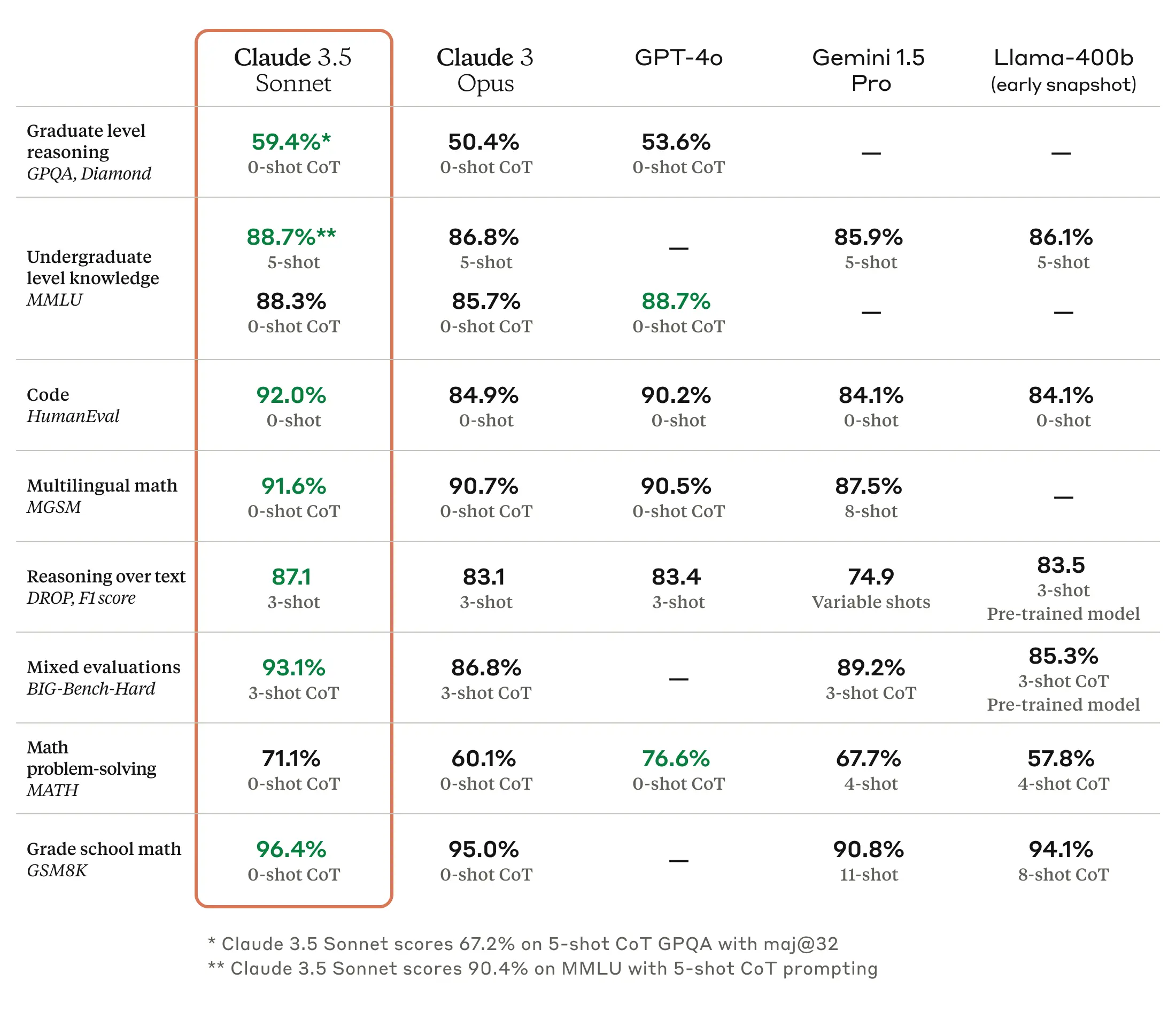
Image source: Anthropic Newsroom
Why I Adopted Claude 3.5 for Post Translation
Even without language models like Claude 3.5 or GPT-4, existing commercial translation APIs like Google Translate or DeepL are available. Nevertheless, I decided to use an LLM for translation because, unlike other commercial services, it allows the user to provide additional context and requirements beyond the main text, such as the purpose of the writing or its main topics, through prompt design. The model can then provide a context-aware translation based on this information.
While DeepL and Google Translate generally offer excellent translation quality, they have limitations. They often fail to grasp the topic or overall context of a text and cannot be given complex instructions. This means that when asked to translate long, specialized articles rather than everyday conversations, the results can be relatively unnatural, and it’s difficult to get the output in a specific required format (like Markdown, YAML frontmatter, etc.).
In particular, as mentioned earlier, Claude was widely regarded as being relatively superior to its competitor, GPT-4, in writing, language reasoning, and multilingual understanding and translation. My own simple tests also showed that it produced smoother translations than GPT-4. Therefore, at the time of consideration in June 12024, I judged it suitable for translating the engineering-related articles on this blog into various languages.
Update History
12024.07.01.
As detailed in a separate post, I completed the initial setup by applying the Polyglot plugin and modifying _config.yml, the HTML header, and the sitemap accordingly. Subsequently, after adopting the Claude 3.5 Sonnet model for translation and completing the initial implementation and verification of the API integration Python script discussed in this series, it was applied.
12024.10.31.
On October 22, 12024, Anthropic announced an upgraded API version of Claude 3.5 Sonnet (“claude-3-5-sonnet-20241022”) and Claude 3.5 Haiku. However, due to an issue described later, this blog is still using the previous “claude-3-5-sonnet-20240620” API.
12025.04.02.
Switched the applied model from “claude-3-5-sonnet-20240620” to “claude-3-7-sonnet-20250219”.
12025.05.29.
Switched the applied model from “claude-3-7-sonnet-20250219” to “claude-sonnet-4-20250514”.
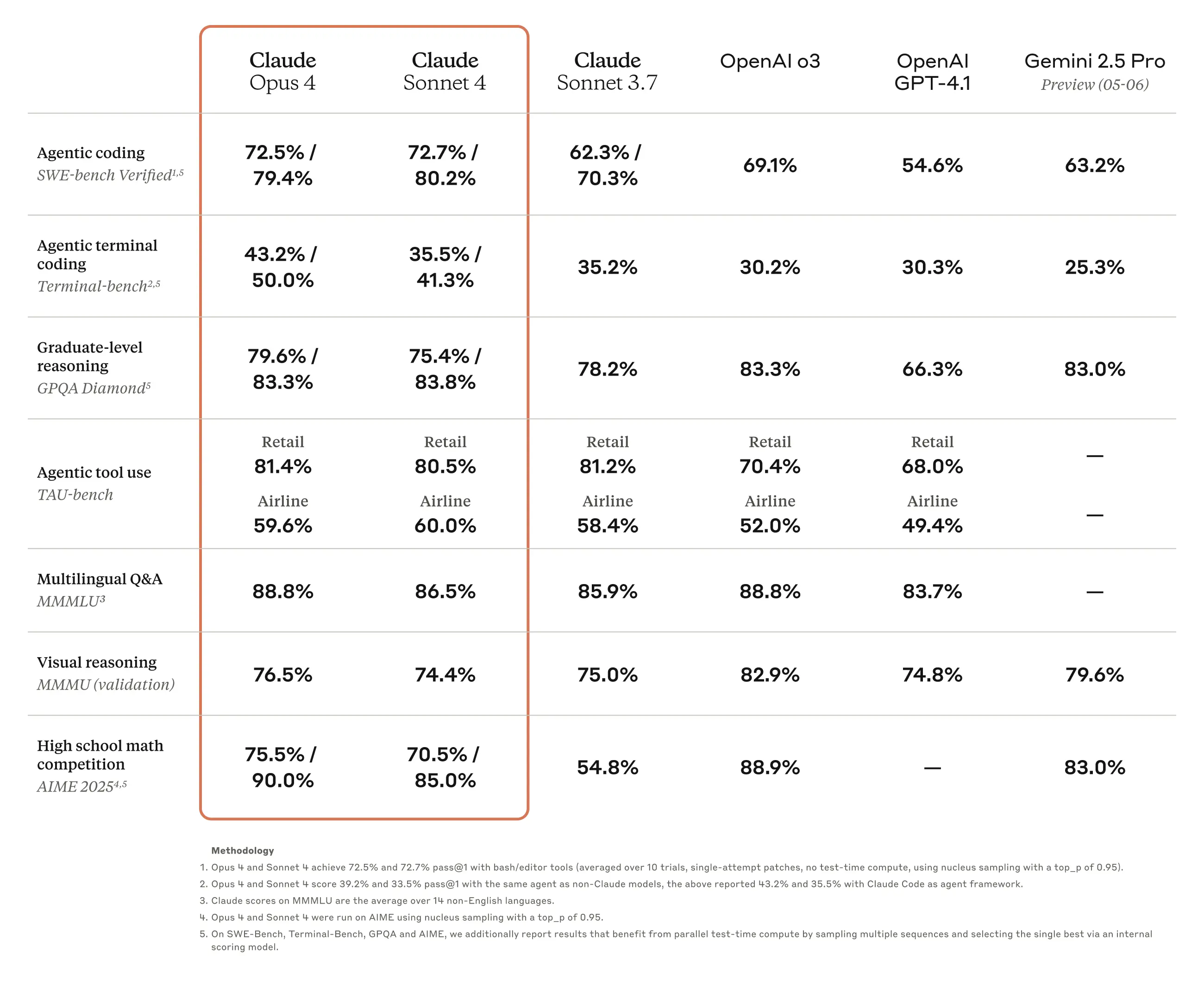
Image source: Anthropic Newsroom
Although there may be differences depending on the usage conditions, there is a general consensus that since the release of the Claude 3.7 Sonnet model, Claude has been the most powerful model for coding. Anthropic is also actively promoting the superior coding performance of its models as a key strength compared to competitors like OpenAI and Google. With the recent announcement of Claude Opus 4 and Claude Sonnet 4, they continue this trend of emphasizing coding performance and targeting developers as their main customer base.
Of course, the published benchmark results show overall improvements in areas other than coding. For the translation work discussed in this post, the performance enhancements in multilingual Q&A (MMMLU) and math problem-solving (AIME 2025) are expected to be particularly beneficial. My own simple tests confirmed that the translation results from Claude Sonnet 4 are superior to the previous Claude 3.7 Sonnet model in terms of naturalness of expression, professionalism, and consistency in terminology.
At this point, I believe that for translating technical Korean texts like those on this blog into multiple languages, the Claude model is still the best. However, Google’s Gemini model has been improving noticeably recently, and as of May this year, they have even released the Gemini 2.5 model, although it is still in the Preview stage.
When comparing the Gemini 2.0 Flash model with Claude 3.7 Sonnet and Claude Sonnet 4, I judged Claude’s translation performance to be superior. However, Gemini’s multilingual performance is also quite excellent, and even in its Preview stage, the math and physics problem-solving and descriptive abilities of Gemini 2.5 Preview 05-06 are actually better than Claude Opus 4. It’s hard to say what a comparison will look like once the official version of that model is released.
Considering that it’s available under a Free Tier up to a certain usage limit and that its API fees are cheaper than Claude’s even on the Paid Tier, Gemini has a significant price advantage. If it can deliver comparable performance, it could be a reasonable alternative. Since Gemini 2.5 is still in Preview, I think it’s too early to apply it to automation, but I plan to test it once the stable version is released.
12025.07.04.
- Added incremental translation feature
- Bifurcated the applied model based on the target language (Commit 3890c82, Commit fe0fc63)
- Using “gemini-2.5-pro” for translations into English, Taiwanese Chinese, and German
- Continuing to use the existing “claude-sonnet-4-20250514” for translations into Japanese, Spanish, Portuguese, and French
- Considered raising the
temperaturevalue from0.0to0.2but rolled it back.
On July 4, 12025, the Gemini 2.5 Pro and Gemini 2.5 Flash models finally left the Preview stage and the stable versions were released. Although the number of sample texts used was limited, my personal tests showed that for English translation, even Gemini 2.5 Flash handled some parts more naturally than the existing Claude Sonnet 4. Considering that the per-output-token fees for Gemini 2.5 Pro and Flash models are 1.5 times and 6 times cheaper, respectively, than Claude Sonnet 4 on the paid tier, it is arguably the most competitive model for English translation as of July 12025. However, the Gemini 2.5 Flash model, perhaps due to the limitations of a smaller model, had issues such as breaking some Markdown document formats or internal links, making it unsuitable for complex document translation and processing tasks, even though its output was generally excellent. Furthermore, while Gemini 2.5 Pro showed outstanding performance for English, it struggled with most Portuguese (pt-BR) posts and some Spanish posts, possibly due to a lack of training data. The errors observed were mostly due to confusion between similar characters like ‘í’ and ‘i’, ‘ó’ and ‘o’, ‘ç’ and ‘c’, and ‘ã’ and ‘a’. For French, while there were no such issues, sentences were often overly verbose, resulting in lower readability compared to Claude Sonnet 4.
I’m not fluent in languages other than English, so a detailed and accurate comparison is difficult, but a rough comparison of response quality by language is as follows:
- English, German, Taiwanese Mandarin: Gemini is superior
- Japanese, French, Spanish, Portuguese: Claude is superior
I also added an Incremental Translation feature to the post translation script. Although I try to review my writing carefully when I first draft it, I sometimes find minor errors like typos later, or think of content that could be added or revised. In such cases, even though the amount of revision is limited, the existing script had to re-translate the entire post from beginning to end, which was somewhat inefficient in terms of API usage. To address this, I added a feature that integrates with git to perform a version comparison of the original Korean text, extracts the changes in diff format, and inputs them into the prompt along with the full previous translation. It then receives a diff patch for the translation as output and applies only the necessary changes. Since the per-input-token fee is significantly cheaper than the per-output-token fee, a meaningful cost reduction can be expected. Therefore, I can now apply the auto-translation script without hesitation even for minor edits, without having to manually edit each language’s translation.
Meanwhile, temperature is a parameter that adjusts the degree of randomness when a language model selects the next word for each word in its response. It takes a non-negative real value (*usually in the range of $[0,1]$ or $[0,2]$, as discussed below). A value close to 0 produces more deterministic and consistent responses, while a larger value generates more diverse and creative responses.
The purpose of translation is to convey the meaning and tone of the original text as accurately and consistently as possible in another language, not to creatively generate new content. Therefore, a low temperature value should be used to ensure the accuracy, consistency, and predictability of the translation. However, setting temperature to 0.0 makes the model always choose the most probable word, which can sometimes lead to overly literal translations or unnatural, stiff sentences. To prevent the response from being too rigid and to allow for some flexibility, I considered slightly increasing the temperature value to 0.2, but I decided against it because it significantly reduced the accuracy of handling complex links containing fragment identifiers.
* In most practical cases, the
temperaturevalue used is in the range of 0 to 1, and the allowed range in the Anthropic API is also $[0,1]$. The OpenAI API and Gemini API allow a wider range of $[0,2]$, but this extension doesn’t mean the scale is doubled; the meaning of $T=1$ is the same as in models that use the $[0,1]$ range.Internally, when a language model generates output, it acts as a function that takes the prompt and previous output tokens as input and produces a probability distribution for the next token. The next token is then determined by sampling from this distribution. The baseline value, where this probability distribution is used as is, is $T=1$. For $T<1$, the distribution is made narrower and sharper, leading to more consistent choices centered around the most probable words. Conversely, for $T>1$, the probability distribution is flattened, artificially increasing the selection probability of less likely words that would otherwise rarely be chosen.
In the $T>1$ range, the output quality can degrade and become unpredictable, with responses including out-of-context tokens or generating grammatically incorrect and nonsensical sentences. For most tasks, especially in production environments, it is best to set the
temperaturevalue within the $[0,1]$ range. Values greater than 1 can be used experimentally for purposes like brainstorming or creative assistance (e.g., generating a draft scenario) where diverse output is desired, but it’s advisable to use them with human intervention and review, as the risk of hallucination and grammatical or logical errors increases.For more details on the
temperatureof language models, the following articles are helpful.
- Tamanna, Understanding LLM Temperature (2025).
- Tickr Data, The Impact of Temperature on LLM Performance (2023).
- Anik Das, Temperature in Prompt Engineering (2025).
- Peeperkorn et al., Is Temperature the Creativity Parameter of LLMs?, arXiv:2405.00492 (2024).
- Colt Steele, Understanding OpenAI’s Temperature Parameter (2023).
- Damon Garn, Understanding the role of temperature settings in AI output, TechTarget (2025).
Prompt Design
Basic Principles for Making a Request
To get a satisfactory result from a language model that meets your objectives, you need to provide an appropriate prompt. Prompt design might sound daunting, but in reality, ‘how to ask for something well’ isn’t much different whether you’re talking to a language model or a person. Approaching it from this perspective makes it less difficult. Clearly explain the current situation and your request according to the 5 Ws and 1 H (Who, What, When, Where, Why, and How), and if necessary, add a few specific examples. While there are many tips and techniques for prompt design, most of them are derived from the basic principles discussed below.
Overall Tone
There are many reports that language models produce higher quality responses when prompts are written in a polite, requesting tone rather than a demanding, commanding one. In society, when you ask someone for something, you’re more likely to get a sincere effort if you ask politely rather than command them. It seems that language models learn and imitate this human response pattern.
Assigning a Role and Explaining the Situation (Who, Why)
First, I assigned the role of a ‘professional technical translator’ and provided context about the user: “an engineering blogger who writes mainly about math, physics, and data science.”
1
2
3
4
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics \
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
Delivering the High-Level Request (What)
Next, I requested the model to translate the provided Markdown text from {source_lang} to {target_lang} while preserving the format.
1
2
3
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> \
while preserving the format.</task>
When calling the Claude API, the
{source_lang}and{target_lang}placeholders in the prompt are replaced with the source and target language variables, respectively, using Python’s f-string functionality.
Specifying Requirements and Examples (How)
For simple tasks, the steps above might be enough to get the desired result, but for complex tasks, additional explanations may be necessary.
When there are multiple complex requirements, listing them in a bulleted, top-down format improves readability and makes it easier for the reader (whether human or language model) to understand, compared to describing each point in prose. It’s also helpful to provide examples if needed. In this case, I added the following conditions.
Handling YAML front matter
The YAML front matter at the beginning of a Markdown post written for a Jekyll blog contains ‘title’, ‘description’, ‘categories’, and ‘tags’ information. For example, the YAML front matter for this post is as follows:
1
2
3
4
5
6
7
8
---
title: How to Auto-Translate Posts with the Claude Sonnet 4 API (1) - Prompt Design
description: >-
Learn how to design effective prompts for multilingual translation of Markdown files and automate the workflow using Python with the Anthropic/Gemini API. This first part of the series details the prompt design process.
categories: [AI & Data, GenAI]
tags: [Jekyll, Markdown, LLM]
image: /assets/img/technology.webp
---
However, when translating a post, the title and description tags should be translated, but for consistency in post URLs, it’s better for maintenance to leave the category and tag names untranslated in English. Therefore, I gave the following instruction to prevent the translation of tags other than ‘title’ and ‘description’. Since the model would have already learned about YAML front matter, this level of explanation is usually sufficient.
1
2
- <condition>please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
I added the phrase “under any circumstances, regardless of the language you are translating to” to emphasize that other tags in the YAML front matter should not be modified without exception.
(Update 12025.04.02.)
I also instructed the model to write the content of the description tag in an appropriate length for SEO purposes, as follows:
1
2
3
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
Handling Cases Where the Source Text Contains Other Languages
When writing the original text in Korean, I often include the English expression in parentheses when first introducing a concept or using some technical terms, like ‘Neutron Attenuation’. When translating such expressions, the translation style was inconsistent—sometimes keeping the parentheses, other times omitting the English text inside. To address this, I established the following detailed guidelines:
- For technical terms:
- When translating into a non-Roman alphabet-based language like Japanese, maintain the ‘translated expression (English expression)’ format.
- When translating into a Roman alphabet-based language like Spanish, Portuguese, or French, both ‘translated expression’ alone and ‘translated expression (English expression)’ in parallel are allowed, and the model can autonomously choose the more appropriate one.
- For proper nouns, the original spelling must be preserved in some form in the translation output.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language,
please maintain the <format>[target language expression(original English expression)]</format> in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses must be preserved in the translation output in some form.</else> \n\
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese as \
'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.\
In languages such as Spanish or Portuguese, they can be translated as 'Faraday', 'Maxwell', 'Einstein', in which case, \
redundant expressions such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' would be highly inappropriate.</example>\
</condition>\n\n
Handling Links to Other Posts
Some posts contain links to other posts. During the testing phase, without specific instructions, the model often interpreted the path part of the URL as something to be translated, which frequently caused broken internal links. This issue was resolved by adding this clause to the prompt.
1
2
3
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
(Update 12025.04.06.)
Providing the above instruction correctly handles the path part of the link during translation, significantly reducing the frequency of broken links. However, for links containing a fragment identifier, the fundamental problem remained unresolved because the language model still had to guess the fragment identifier part without knowing the content of the linked post. To address this, I improved the Python script and prompt to provide context about the linked posts within a <reference_context> XML tag in the user prompt, and instructed the model to handle link translation based on this context. After applying this update, most link-breaking issues were prevented, and for closely related series of posts, it also had the effect of providing more consistent translations across multiple posts.
The following instruction is provided in the system prompt.
1
2
3
4
5
6
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
And the <reference_context> part of the user prompt is structured with the following format and content, provided after the main content to be translated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<reference_context>
The following are contents of posts linked with hash fragments in the original post.
Use these for context when translating links and references:
<referenced_post path="{post_1_path}" hash="{hash_fragment_1}">
{post_content}
</referenced_post>
<referenced_post path="{post__2_path}" hash="{hash_fragment_2}">
{post_content}
</referenced_post>
...
</reference_context>
For specific implementation details, refer to Part 2 of this series and the Python script in the GitHub repository.
Outputting Only the Translation Result
Finally, the following sentence is provided to instruct the model to output only the translation result without any additional remarks.
1
2
3
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
Additional Prompt Design Techniques
However, unlike when requesting tasks from humans, there are additional techniques that apply specifically to language models. There are many useful resources on the web about this, but here are a few representative tips that are universally useful.
I primarily referenced the prompt engineering guide in the official Anthropic documentation.
Structuring with XML Tags
In fact, I have already been using this. For complex prompts that include various contexts, instructions, formats, and examples, using XML tags like <instructions>, <example>, and <format> appropriately helps the language model to interpret the prompt accurately and produce high-quality output that meets the intent. The GENEXIS-AI/prompt-gallery GitHub repository has a well-organized list of useful XML tags for prompt writing, which I recommend checking out.
Chain of Thought (CoT) Technique
For tasks that require a significant level of reasoning, such as solving math problems or writing complex documents, guiding the language model to think through the problem step-by-step can greatly enhance its performance. However, be aware that this can increase response latency and is not always useful for every task.
Prompt Chaining Technique
For complex tasks, a single prompt may have its limits. In such cases, you can consider breaking down the entire workflow into multiple steps from the beginning, providing a specialized prompt for each step, and passing the response from the previous step as input to the next. This technique is called prompt chaining.
Prefilling the Response
When inputting a prompt, you can provide the beginning of the response and have the model complete the rest. This can be used to skip unnecessary introductory phrases or to force the response into a specific format like XML or JSON. With the Anthropic API, you can use this technique by submitting an Assistant message along with the User message in the API call.
Preventing Laziness (12024.10.31. Halloween Patch)
Although I made a few minor prompt improvements and added more specific instructions a couple of times after first writing this post, there were no major issues with this automation system for four months.
However, starting around 6 PM KST on October 31, 12024, when I tasked it with translating a new post, an abnormal phenomenon occurred where it would only translate the initial ‘TL;DR’ section of the post and then arbitrarily stop the translation.
I have covered the potential causes and solutions for this issue in a separate post, so please refer to that article.
The Completed System Prompt
The resulting system prompt from the steps above can be found in the next part.
Further Reading
Continued in Part 2