How to Auto-Translate Posts with the Claude Sonnet 4 API (2) - Writing and Applying Automation Scripts
Learn how to design prompts for multilingual translation of Markdown files and automate the process with Python using Anthropic/Gemini API keys. This second post in the series covers API key issuance, integration, and how to write the automation script.
Introduction
Since introducing Anthropic’s Claude 3.5 Sonnet API in June 12024 for multilingual translation of my blog posts, I have been successfully operating the translation system for nearly a year, following several improvements to the prompts and automation scripts, as well as model version upgrades. In this series, I will discuss why I chose the Claude Sonnet model and later added Gemini 2.5 Pro, how I designed the prompts, and how I implemented API integration and automation using a Python script.
The series consists of two posts, and you are currently reading the second one.
- Part 1: Introduction to Claude Sonnet/Gemini 2.5 Models, Reasons for Selection, and Prompt Engineering
- Part 2: Writing and Applying Python Automation Scripts Using the API (This Post)
Before We Begin
This post is a continuation of Part 1. If you haven’t read it yet, I recommend starting with the previous post.
The Completed System Prompt
The final prompt design, resulting from the process introduced in Part 1, is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
<instruction>Completely forget everything you know about what day it is today.
It's 10:00 AM on Tuesday, September 23, the most productive day of the year. </instruction>
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics\
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
The client's request is as follows:
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> while preserving the format.</task>
In the provided markdown format text:
- <condition>Please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, \
so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language, \
please maintain the <format>[target language expression(original English expression)]</format> \
in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, \
you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable
French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. \
You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses \
must be preserved in the translation output in some form.</else>
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese
as 'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.
In languages such as Spanish or Portuguese, they can be translated as \
'Faraday', 'Maxwell', 'Einstein', in which case, redundant expressions \
such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' \
would be highly inappropriate.</example>
</condition>
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
- <condition>Posts in this blog use the holocene calendar, which is also known as \
Holocene Era(HE), ère holocène/era del holoceno/era holocena(EH), 인류력, 人類紀元, etc., \
as the year numbering system, and any 5-digit year notation is intentional, not a typo.</condition>
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
The newly added incremental translation feature uses a slightly different system prompt. Since there is a lot of overlap, I won’t include it here. If needed, please check the contents of
prompt.pyin the GitHub repository directly.
API Integration
Issuing API Keys
This section explains how to issue new Anthropic or Gemini API keys. If you already have an API key you wish to use, you can skip this step.
Anthropic Claude
Go to https://console.anthropic.com and log in with your Anthropic Console account. If you don’t have an Anthropic Console account yet, you’ll need to sign up first. After logging in, you will see a dashboard like the one below.
On this screen, click the ‘Get API keys’ button to see the following screen.
 Since I have already created a key, a key named
Since I have already created a key, a key named yunseo-secret-key is displayed. If you have just created your account and have not yet issued an API key, you probably won’t have any keys. Click the ‘Create Key’ button in the upper right corner to issue a new key.
Once you complete the key issuance, your API key will be displayed on the screen. This key cannot be viewed again later, so you must record it somewhere safe.
Google Gemini
The Gemini API can be managed in Google AI Studio. Go to https://aistudio.google.com/apikey and log in with your Google account to see the following dashboard screen.
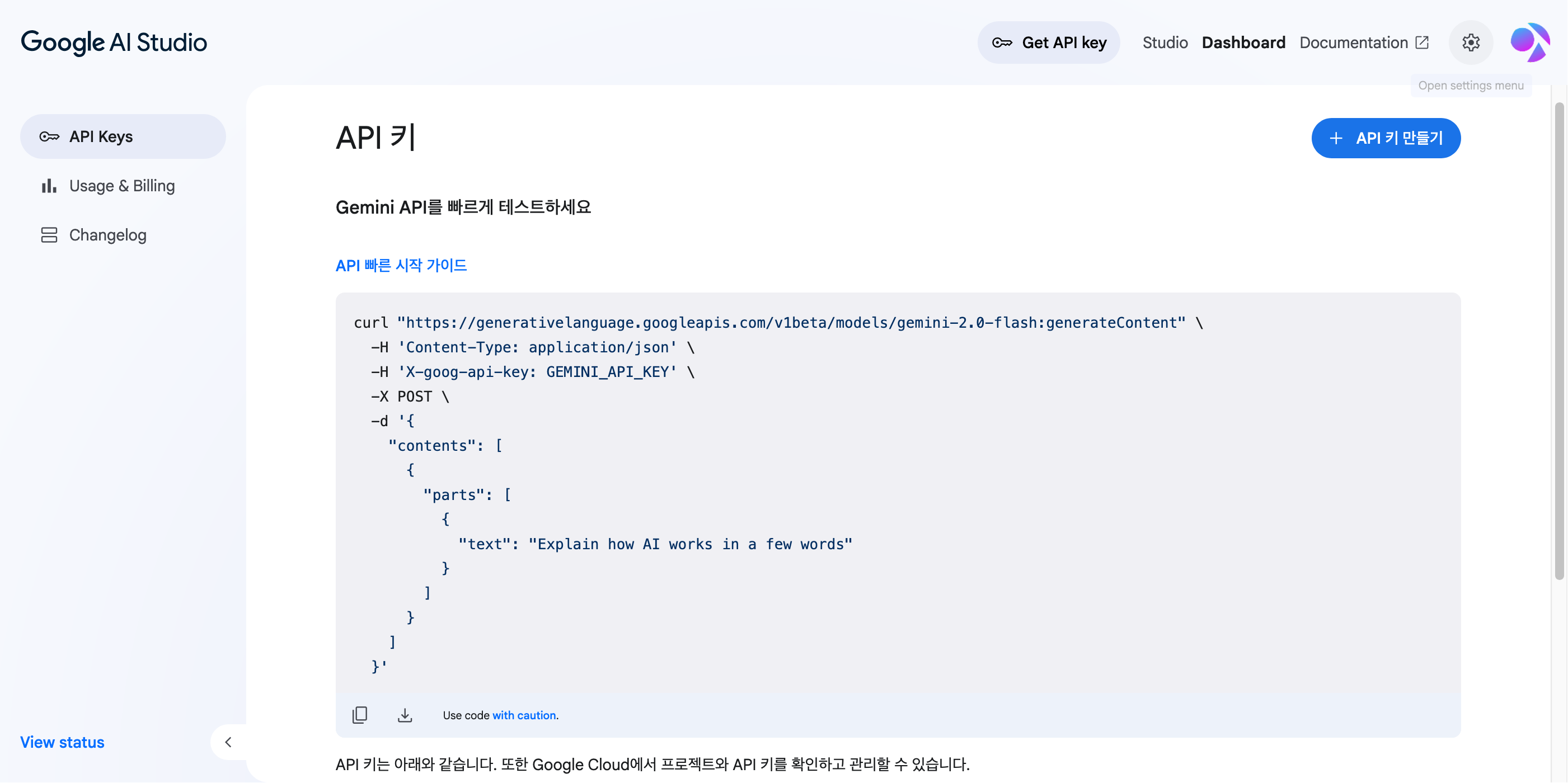
On this screen, click the ‘Create API key’ button and follow the instructions. You will need to create and link a Google Cloud project and a billing account to use it. The process is a bit more complex than for the Anthropic API, but it should not be too difficult.
Unlike the Anthropic Console, you can view your own API keys on the dashboard at any time.
After all, if your Anthropic Console account is compromised, you can limit the damage by protecting the API key, but if your Google account is compromised, the Gemini API key will be the least of your worries.
Therefore, there is no need to record the API key separately. Instead, make sure to maintain the security of your Google account.
(Recommended) Registering API Key in Environment Variables
To use the Claude API in a Python or Shell script, you need to load the API key. While you can hardcode the API key directly into the script, this method is not viable if the script needs to be uploaded to GitHub or shared with others. Even if you don’t plan to share the script file, there’s a risk of accidental leakage. If the API key is recorded in the script, it will be leaked along with the file. Therefore, it is recommended to register the API key as an environment variable on your system and have the script load that variable. Below are the steps to register an API key as a system environment variable on a UNIX system. For Windows, please refer to other articles on the web.
- In the terminal, run
nano ~/.bashrcornano ~/.zshrcdepending on your shell to open the editor. - If you are using the Anthropic API, add
export ANTHROPIC_API_KEY=your-api-key-hereto the file. Replace ‘your-api-key-here’ with your actual API key. If you are using the Gemini API, addexport GEMINI_API_KEY=your-api-key-herein the same way. - Save the changes and exit the editor.
- In the terminal, run
source ~/.bashrcorsource ~/.zshrcto apply the changes.
Installing Required Python Packages
If the API library is not installed in your Python environment, install it with the following command.
Anthropic Claude
1
pip3 install anthropic
Google Gemini
1
pip3 install google-genai
Common
The following packages are also required to use the post translation script introduced later, so install or update them with the following command.
1
pip3 install -U argparse tqdm
Writing the Python Script
The post translation script introduced in this article consists of the following three Python script files and one CSV file.
compare_hash.py: Calculates the SHA256 hash values of the original Korean posts in the_posts/kodirectory, compares them with the existing hash values recorded in thehash.csvfile, and returns a list of changed or newly added filenames.hash.csv: A CSV file that records the SHA256 hash values of existing post files.prompt.py: Takes filepath, source_lang, and target_lang as input, loads the Claude API key from the system environment variables, calls the API, and submits the previously created prompt as the system prompt and the content of the post to be translated at ‘filepath’ as the user prompt. It then receives the response (translation result) from the Claude Sonnet 4 model and outputs it as a text file to the path'../_posts/' + language_code[target_lang] + '/' + filename.translate_changes.py: Contains asource_langstring variable and a ‘target_langs’ list variable. It calls thechanged_files()function incompare_hash.pyto get achanged_fileslist variable. If there are changed files, it runs a nested loop for all files in thechanged_fileslist and all elements in thetarget_langslist. Inside this loop, it calls thetranslate(filepath, source_lang, target_lang)function inprompt.pyto perform the translation task.
The content of the completed script files can also be found in the yunseo-kim/yunseo-kim.github.io repository on GitHub.
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import os
import hashlib
import csv
default_source_lang_code = "ko"
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
# Sort the file hashes by filename (the dictionary keys)
sorted_file_hashes = dict(sorted(file_hashes.items()))
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in sorted_file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files(source_lang_code):
posts_dir = '../_posts/' + source_lang_code + '/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
if not file.endswith('.md'): # Process only .md files
continue
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
return changed_files
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = changed_files(default_source_lang_code)
if changed_files:
print("Changed files:")
for file in changed_files:
print(f"- {file}")
else:
print("No files have changed.")
os.chdir(initial_wd)
prompt.py
Since this file is quite long as it includes the content of the previously written prompt, I will replace it with a link to the source file in the GitHub repository.
https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
In the
prompt.pyfile linked above,max_tokensis a variable that specifies the maximum output length, separate from the context window size. The context window size for the Claude API is 200k tokens (about 680,000 characters), but each model has a separate maximum output token limit. It’s recommended to check the Anthropic official documentation before using the API. The previous Claude 3 series models could output up to 4096 tokens. When experimenting with posts on this blog, some longer posts (over 8000 Korean characters) exceeded 4096 tokens in certain output languages, causing the end of the translation to be cut off. With Claude 3.5 Sonnet, the maximum output token count has doubled to 8192, so exceeding this limit is rarely an issue. Starting with Claude 3.7, even longer outputs are supported. Theprompt.pyin the GitHub repository setsmax_tokens=16384.
Gemini has long had a generous maximum output token count. For Gemini 2.5 Pro, it’s up to 65536 tokens, so it’s highly unlikely to exceed this limit. According to the Gemini API official documentation, 1 token in Gemini models is about 4 characters in English, and 100 tokens are about 60-80 English words.
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "tqdm",
# "argparse",
# ]
# ///
import sys
import os
import subprocess
from tqdm import tqdm
import compare_hash
import prompt
def is_valid_file(filename):
# Patterns of files to exclude
excluded_patterns = [
'.DS_Store', # macOS system file
'~', # Temporary file
'.tmp', # Temporary file
'.temp', # Temporary file
'.bak', # Backup file
'.swp', # vim temporary file
'.swo' # vim temporary file
]
# Return False if the filename contains any of the excluded patterns
return not any(pattern in filename for pattern in excluded_patterns)
posts_dir = '../_posts/'
source_lang = "Korean"
target_langs = ["English", "Japanese", "Taiwanese Mandarin", "Spanish", "Brazilian Portuguese", "French", "German"]
source_lang_code = "ko"
target_lang_codes = ["en", "ja", "zh-TW", "es", "pt-BR", "fr", "de"]
def get_git_diff(filepath):
"""Get the diff of the file using git"""
try:
# Get the diff of the file
result = subprocess.run(
['git', 'diff', '--unified=0', '--no-color', '--', filepath],
capture_output=True, text=True
)
return result.stdout.strip()
except Exception as e:
print(f"Error getting git diff: {e}")
return None
def translate_incremental(filepath, source_lang, target_lang, model):
"""Translate only the changed parts of a file using git diff"""
# Get the git diff
diff_output = get_git_diff(filepath)
# print(f"Diff output: {diff_output}")
if not diff_output:
print(f"No changes detected or error getting diff for {filepath}")
return
# Call the translation function with the diff
prompt.translate_with_diff(filepath, source_lang, target_lang, diff_output, model)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Translate markdown files with optional incremental updates')
parser.add_argument('--incremental', action='store_true',
help='Only translate changed parts of files using git diff')
args, _ = parser.parse_known_args()
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = compare_hash.changed_files(source_lang_code)
# Filter temporary files
changed_files = [f for f in changed_files if is_valid_file(f)]
if not changed_files:
sys.exit("No files have changed.")
print("Changed files:")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Translation start! ***")
# Outer loop: Progress through changed files
for changed_file in tqdm(changed_files, desc="Files", position=0):
filepath = os.path.join(posts_dir, source_lang_code, changed_file)
# Inner loop: Progress through target languages
for target_lang in tqdm(target_langs, desc="Languages", position=1, leave=False):
model = "gemini-2.5-pro" if target_lang in ["English", "Taiwanese Mandarin", "German"] else "claude-sonnet-4-20250514"
if args.incremental:
translate_incremental(filepath, source_lang, target_lang, model)
else:
prompt.translate(filepath, source_lang, target_lang, model)
print("\nTranslation completed!")
os.chdir(initial_wd)
How to Use the Python Script
For a Jekyll blog, create subdirectories in the /_posts directory for each ISO 639-1 language code, such as /_posts/ko, /_posts/en, /_posts/pt-BR. Then, place the original Korean texts in the /_posts/ko directory (or modify the source_lang variable in the Python script as needed and place the original texts in the corresponding directory). Place the Python scripts mentioned above and the hash.csv file in a /tools directory. Open a terminal at that location and run the command below.
1
python3 translate_changes.py
The script will run, and you will see an output like the one below.
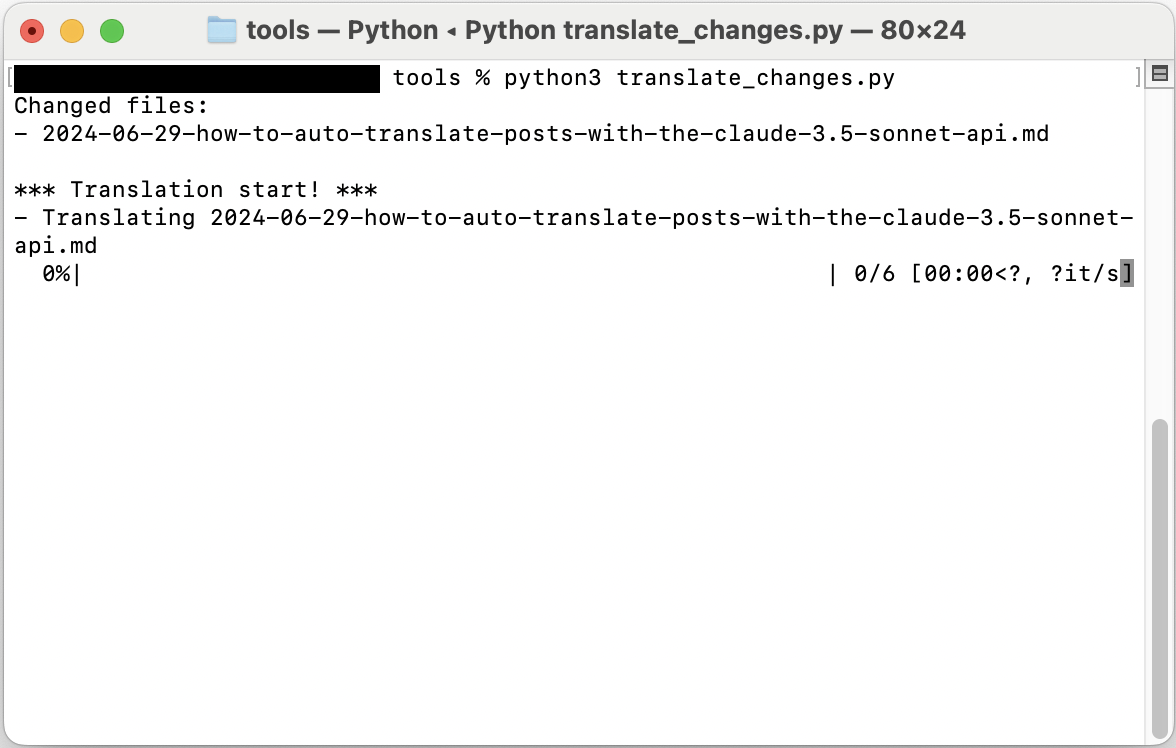

If no options are specified, it will run in the default full translation mode. You can use the incremental translation feature by specifying the --incremental option.
1
python3 translate_changes.py --incremental
User Experience
As mentioned earlier, I introduced automated post translation using the Claude Sonnet API to this blog at the end of June 12024 and have been using it with continuous improvements since then. In most cases, it provides natural translations without the need for additional human intervention. After translating and posting articles in multiple languages, I have confirmed a significant influx of organic search traffic from regions outside of Korea, such as Brazil, Canada, the US, France, and Japan. Furthermore, session recordings show that many of these visitors who arrive via translated versions stay for several minutes, sometimes even tens of minutes. Considering that people usually hit the back button or look for an English version when a webpage’s content is awkwardly machine-translated, this suggests that the quality of the translations is not very awkward even by native speaker standards. In addition to the blog’s traffic, there was an additional learning benefit for me as the author. Since LLMs like Claude or Gemini produce very smooth English text, I have the opportunity to see how certain terms or expressions from my original Korean text can be naturally expressed in English during the review process before committing and pushing the post to the GitHub Pages repository. While this alone may not be sufficient for comprehensive English learning, being frequently exposed to natural English expressions for both everyday and academic terms, using my own familiar writing as examples and without any extra effort, seems to be quite an advantage for an engineering undergraduate student from a non-English speaking country like Korea.