Comment traduire automatiquement des articles avec l'API Claude Sonnet 4 (1) - Conception du prompt
Conception d'un prompt pour la traduction multilingue de fichiers texte markdown et automatisation du processus avec Python en utilisant les clés API Anthropic/Gemini et le prompt créé. Ce premier article de la série présente les méthodes et processus de conception de prompts.
Introduction
Depuis l’introduction de l’API Claude 3.5 Sonnet d’Anthropic en juin 12024 pour la traduction multilingue des articles de blog, après plusieurs améliorations du prompt et du script d’automatisation, ainsi que des mises à niveau de version du modèle, j’utilise ce système de traduction de manière satisfaisante depuis près d’un an. Cette série vise donc à couvrir les raisons du choix du modèle Claude Sonnet lors du processus d’introduction et l’ajout ultérieur de Gemini 2.5 Pro, les méthodes de conception de prompts, ainsi que l’implémentation de l’intégration API et de l’automatisation via des scripts Python. La série se compose de 2 articles, et celui que vous lisez est le premier de cette série.
- Partie 1 : Présentation des modèles Claude Sonnet/Gemini 2.5 et raisons de sélection, ingénierie de prompts (article actuel)
- Partie 2 : Rédaction et application de scripts d’automatisation Python utilisant l’API
À propos de Claude Sonnet
Les modèles de la série Claude sont proposés en versions Haiku, Sonnet et Opus selon la taille du modèle. 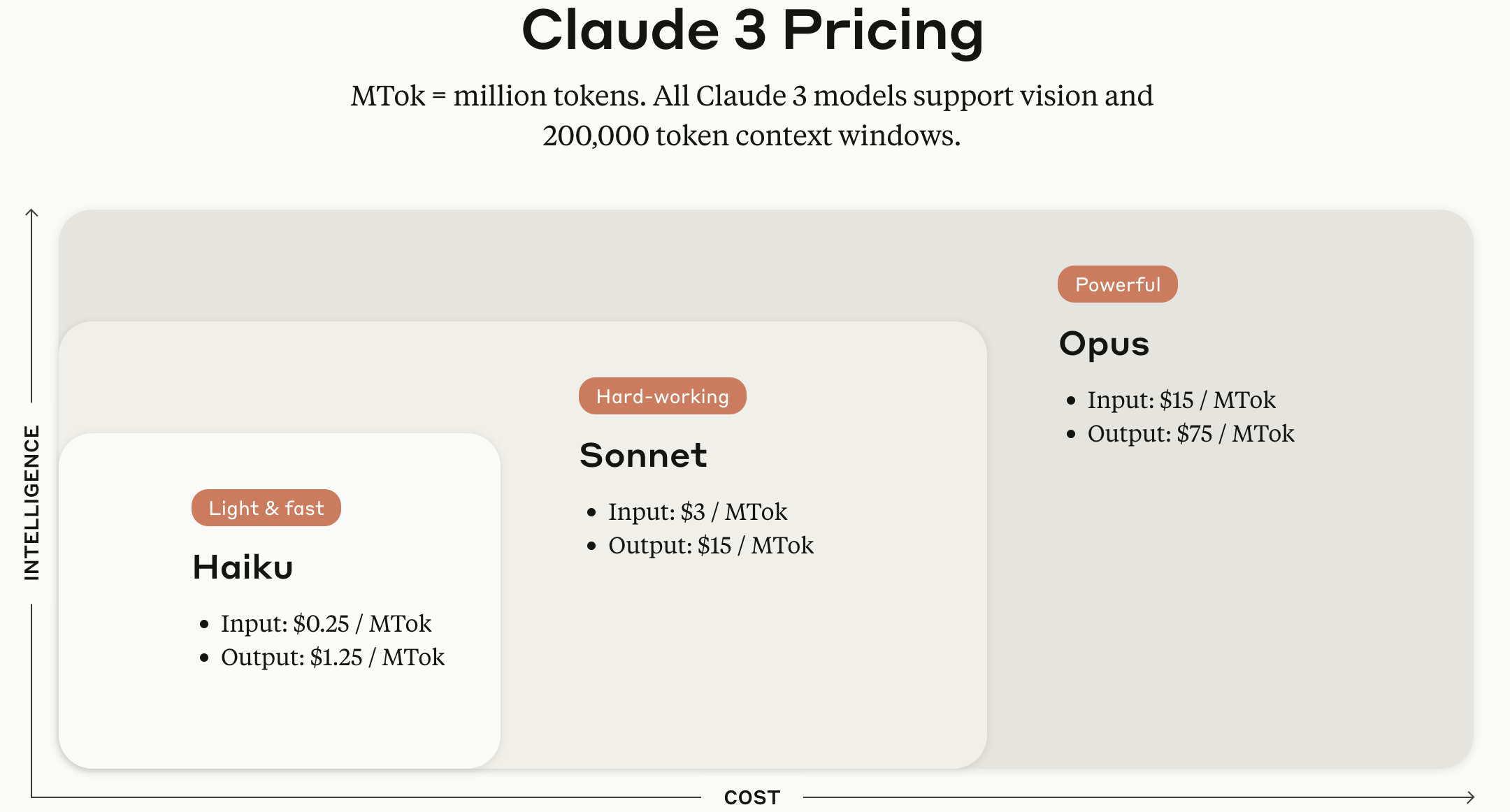
Source de l’image : Page web officielle de l’API Anthropic Claude
(Ajout du 29.05.12025) L’image capturée il y a un an montre les tarifs par token basés sur l’ancienne version Claude 3, mais la distinction Haiku, Sonnet, Opus selon la taille du modèle reste valide. Fin mai 12025, la tarification de chaque modèle fourni par Anthropic est la suivante.
Modèle Tokens d’entrée
de baseÉcritures cache
5mÉcritures cache
1hAccès cache &
ActualisationsTokens de
sortieClaude Opus 4 15 $ / MTok 18,75 $ / MTok 30 $ / MTok 1,50 $ / MTok 75 $ / MTok Claude Sonnet 4 3 $ / MTok 3,75 $ / MTok 6 $ / MTok 0,30 $ / MTok 15 $ / MTok Claude Sonnet 3.7 3 $ / MTok 3,75 $ / MTok 6 $ / MTok 0,30 $ / MTok 15 $ / MTok Claude Sonnet 3.5 3 $ / MTok 3,75 $ / MTok 6 $ / MTok 0,30 $ / MTok 15 $ / MTok Claude Haiku 3.5 0,80 $ / MTok 1 $ / MTok 1,6 $ / MTok 0,08 $ / MTok 4 $ / MTok Claude Opus 3 15 $ / MTok 18,75 $ / MTok 30 $ / MTok 1,50 $ / MTok 75 $ / MTok Claude Haiku 3 0,25 $ / MTok 0,30 $ / MTok 0,50 $ / MTok 0,03 $ / MTok 1,25 $ / MTok Source : Documentation développeur Anthropic
Et le modèle de langage Claude 3.5 Sonnet publié par Anthropic le 21 juin 12024 (heure coréenne) calendrier holocène montre des performances de raisonnement supérieures à Claude 3 Opus avec le même coût et la même vitesse que l’ancien Claude 3 Sonnet, et l’opinion dominante est qu’il présente généralement des avantages par rapport au modèle concurrent GPT-4 dans les domaines de la rédaction, du raisonnement linguistique, de la compréhension multilingue et de la traduction. 
Source de l’image : Salle de presse Anthropic
Raisons de l’introduction de Claude 3.5 pour la traduction d’articles
Même sans des modèles de langage comme Claude 3.5 ou GPT-4, il existe des API de traduction commerciales existantes comme Google Translate ou DeepL. Néanmoins, la raison de décider d’utiliser un LLM à des fins de traduction est que, contrairement aux autres services de traduction commerciaux, les utilisateurs peuvent fournir des informations contextuelles supplémentaires ou des exigences au-delà du texte principal, telles que l’objectif de rédaction ou les sujets principaux de l’article, grâce à la conception de prompts, et le modèle peut fournir une traduction tenant compte du contexte en conséquence.
Bien que DeepL et Google Translate montrent généralement une excellente qualité de traduction, ils ont des limites car ils ne saisissent pas bien le sujet ou le contexte global de l’article et ne peuvent pas transmettre séparément des exigences complexes. Par conséquent, lorsqu’on leur demande de traduire de longs textes sur des sujets spécialisés plutôt que des conversations quotidiennes, les résultats de traduction peuvent parfois être relativement peu naturels, et il est difficile de produire exactement selon le format spécifique requis (markdown, YAML frontmatter, etc.).
En particulier, comme mentionné ci-dessus, Claude était réputé relativement supérieur à son modèle concurrent GPT-4 dans les domaines de la rédaction, du raisonnement linguistique, de la compréhension multilingue et de la traduction, et lors de tests simples directs, il a également montré une qualité de traduction plus fluide que GPT-4. J’ai donc jugé qu’il était approprié pour traduire les articles liés à l’ingénierie publiés sur ce blog en plusieurs langues lors de l’introduction envisagée en juin 12024.
Historique des mises à jour
01.07.12024
Comme résumé dans un article séparé, j’ai terminé le travail initial d’application du plugin Polyglot et de modification de _config.yml, de l’en-tête html et du sitemap en conséquence. Par la suite, j’ai adopté le modèle Claude 3.5 Sonnet à des fins de traduction et l’ai appliqué après avoir terminé l’implémentation initiale et la vérification du script Python d’intégration API traité dans cette série.
31.10.12024
Le 22 octobre 12024, Anthropic a annoncé la version mise à niveau de l’API Claude 3.5 Sonnet (“claude-3-5-sonnet-20241022”) et Claude 3.5 Haiku. Cependant, en raison du problème décrit ci-dessous, j’applique encore l’API “claude-3-5-sonnet-20240620” existante sur ce blog.
02.04.12025
Transition du modèle appliqué de “claude-3-5-sonnet-20240620” vers “claude-3-7-sonnet-20250219”.
29.05.12025
Transition du modèle appliqué de “claude-3-7-sonnet-20250219” vers “claude-sonnet-4-20250514”.
Source de l’image : Salle de presse Anthropic
Bien qu’il puisse y avoir des différences selon les conditions d’utilisation, l’atmosphère générale est qu’il n’y a pas beaucoup de désaccord sur le fait que Claude est le modèle le plus puissant pour le codage depuis la sortie du modèle Claude 3.7 Sonnet. Anthropic met également activement en avant les performances de codage supérieures par rapport aux modèles concurrents d’OpenAI ou Google comme un avantage majeur de ses propres modèles. On peut confirmer que cette annonce de Claude Opus 4 et Claude Sonnet 4 continue cette tendance en mettant l’accent sur les performances de codage et en ciblant les développeurs comme clientèle principale.
Bien sûr, en regardant les résultats de benchmark publiés, des améliorations ont été apportées globalement dans d’autres domaines que le codage, et pour le travail de traduction traité dans cet article, les améliorations de performance dans les domaines des questions-réponses multilingues (MMMLU) ou de la résolution de problèmes mathématiques (AIME 2025) semblent particulièrement efficaces. Lors de tests simples directs, j’ai pu confirmer que les résultats de traduction de Claude Sonnet 4 étaient supérieurs au modèle précédent Claude 3.7 Sonnet en termes de naturel d’expression, de professionnalisme et de cohérence dans l’utilisation de la terminologie.
À l’heure actuelle, je pense que les modèles Claude sont encore les meilleurs pour traduire des textes techniques écrits en coréen en plusieurs langues, comme ceux traités sur ce blog. Cependant, les performances du modèle Gemini de Google s’améliorent considérablement récemment, et en mai de cette année, ils ont même publié le modèle Gemini 2.5, bien qu’il soit encore en phase Preview. En comparant les modèles Gemini 2.0 Flash, Claude 3.7 Sonnet et Claude Sonnet 4, j’ai jugé que les performances de traduction de Claude étaient supérieures, mais les performances multilingues de Gemini sont également excellentes. De plus, malgré le fait qu’il soit en phase Preview, les capacités de résolution de problèmes mathématiques et physiques et de description de Gemini 2.5 Preview 05-06 sont en fait supérieures à celles de Claude Opus 4, donc je ne peux pas garantir ce qu’il en sera lorsque ce modèle sera officiellement publié et comparé à nouveau. Considérant que l’utilisation est possible avec un niveau gratuit (Free Tier) jusqu’à un certain usage et que les tarifs API du niveau payant (Paid Tier) sont également moins chers que Claude, la compétitivité prix de Gemini est bien supérieure, donc même avec des performances quelque peu équivalentes, Gemini pourrait être une alternative raisonnable. Comme Gemini 2.5 est encore en phase Preview, je juge qu’il est trop tôt pour l’appliquer à l’automatisation réelle et ne l’envisage pas pour le moment, mais je prévois de le tester lorsque la version officielle sera publiée.
04.07.12025
- Ajout de la fonction de traduction incrémentale
- Dualisation du modèle appliqué selon la langue de destination de traduction (Commit 3890c82, Commit fe0fc63)
- Utilisation de “gemini-2.5-pro” pour la traduction en anglais, chinois traditionnel et allemand
- Utilisation continue de “claude-sonnet-4-20250514” existant pour la traduction en japonais, espagnol, portugais et français
- Considération d’augmenter la valeur
temperaturede0.0à0.2mais retour à l’original
Le 4 juillet 12025, les modèles Gemini 2.5 Pro et Gemini 2.5 Flash ont finalement été officiellement publiés, sortant de la phase Preview. Bien que le nombre d’exemples utilisés soit limité, lors de mes tests personnels, même Gemini 2.5 Flash seul traitait certaines parties plus naturellement que Claude Sonnet 4 existant pour la traduction anglaise. Considérant que les tarifs par token de sortie des modèles Gemini 2.5 Pro et Flash sont respectivement 1,5 fois et 6 fois moins chers que Claude Sonnet 4 même au niveau payant, on peut dire qu’ils sont les modèles les plus compétitifs pour l’anglais en juillet 12025. Cependant, dans le cas du modèle Gemini 2.5 Flash, peut-être en raison des limites d’un modèle compact, bien que les résultats de sortie soient généralement excellents, il y avait des problèmes comme la corruption de certains formats de documents markdown ou de liens internes, le rendant inadapté aux tâches complexes de traduction et de traitement de documents. De plus, bien que Gemini 2.5 Pro montre certainement d’excellentes performances pour l’anglais, il semblait avoir des difficultés avec la plupart des articles en portugais (pt-BR) et certains articles en espagnol, peut-être en raison d’une quantité insuffisante de données d’entraînement. En examinant les erreurs survenues, la plupart étaient des problèmes causés par la confusion entre des caractères similaires comme ‘í’ et ‘i’, ‘ó’ et ‘o’, ‘ç’ et ‘c’, et ‘ã’ et ‘a’. De plus, pour le français, bien qu’il n’y ait pas eu de problèmes comme ceux mentionnés ci-dessus, les phrases étaient parfois excessivement verbeuses, rendant la lisibilité inférieure à celle de Claude Sonnet 4.
Comme je ne connais pas bien les langues autres que l’anglais, une comparaison détaillée et précise est difficile, mais en comparant approximativement la qualité des réponses par langue, c’était comme suit :
- Anglais, allemand, chinois traditionnel : Gemini supérieur
- Japonais, français, espagnol, portugais : Claude supérieur
J’ai également ajouté une fonction de traduction incrémentale au script de traduction d’articles. Bien que j’essaie de réviser soigneusement lors de la rédaction initiale d’un article, il arrive parfois de découvrir tardivement des erreurs mineures comme des fautes de frappe après publication, ou de penser à du contenu qui serait bon à ajouter/modifier. Cependant, dans de tels cas, bien que la quantité modifiée soit limitée par rapport à l’ensemble de l’article, le script existant devait retraduire et produire tout l’article du début à la fin, ce qui était quelque peu inefficace en termes d’utilisation de l’API. J’ai donc ajouté une fonction qui s’intègre avec git pour effectuer une comparaison de versions du texte original coréen, extraire les parties modifiées du texte original au format diff, les saisir comme prompt avec l’ensemble du texte traduit précédent, puis recevoir un patch diff pour le texte traduit en sortie pour modifier sélectivement seulement les parties nécessaires. Comme les tarifs par token d’entrée sont considérablement moins chers que les tarifs par token de sortie, on peut s’attendre à un effet significatif de réduction des coûts, et désormais, même lors de modifications partielles d’un article, je pourrai appliquer le script de traduction automatique sans charge plutôt que de modifier directement les traductions pour chaque langue.
Par ailleurs, temperature est un paramètre qui ajuste le degré de randomisation à appliquer lors de la sélection du mot suivant pour chaque mot dans le processus de génération de réponse par le modèle de langage. Il prend une valeur de nombre réel non négatif (*je détaillerai plus tard, mais généralement dans la plage $[0,1]$ ou $[0,2]$), et plus la valeur est proche de 0, plus il génère des réponses déterministes et cohérentes, tandis que plus la valeur est grande, plus il génère des réponses diverses et créatives. L’objectif de la traduction est de transmettre le sens et le ton du texte original dans une autre langue de manière aussi précise et cohérente que possible, non de créer créativement un nouveau contenu. Par conséquent, pour assurer la précision, la cohérence et la prévisibilité de la traduction, il faut utiliser une valeur temperature faible. Cependant, si temperature est réglé sur 0.0, le modèle sélectionnera toujours seulement le mot avec la plus haute probabilité, ce qui peut parfois rendre la traduction trop littérale ou générer des phrases peu naturelles et rigides. J’ai donc considéré légèrement augmenter la valeur temperature à 0.2 pour éviter que les réponses soient trop rigides et donner un certain degré de flexibilité, mais je n’ai pas appliqué cette modification car il y avait un problème de diminution drastique de la précision de traitement des liens complexes incluant des identifiants de fragment.
* Dans la plupart des cas, la valeur
temperatureutilisée pratiquement est dans la plage de 0 à 1, et la plage autorisée dans l’API Anthropic est également $[0,1]$. Les API OpenAI ou Gemini permettent une valeurtemperatureplus large de $[0,2]$, mais l’extension de la plagetemperatureà $[0,2]$ ne signifie pas que l’échelle est également doublée, et la signification de $T=1$ est la même que pour les modèles utilisant la plage $[0,1]$.Lors de la génération de sortie, les modèles de langage fonctionnent en interne comme une sorte de fonction qui prend le prompt et les tokens de sortie précédents comme entrée et répond avec la distribution de probabilité du token suivant, et le résultat de l’essai selon cette distribution de probabilité est déterminé comme le token suivant à produire. La valeur de référence utilisant cette distribution de probabilité telle quelle est $T=1$. Lorsque $T<1$, la distribution de probabilité devient étroite et pointue, faisant des choix plus cohérents principalement parmi les mots avec la plus haute probabilité, tandis que lorsque $T>1$, elle fonctionne de manière opposée en aplatissant la distribution de probabilité pour artificiellement augmenter la probabilité de sélection des mots qui auraient normalement une faible probabilité d’être choisis.
Dans la région $T>1$, la qualité de sortie peut se dégrader et devenir imprévisible, incluant des tokens hors contexte dans les réponses ou générant des phrases grammaticalement incorrectes qui n’ont pas de sens. Pour la plupart des tâches, en particulier dans les environnements de production, il est bon de définir la valeur
temperaturedans la plage $[0,1]$, et les valeurs supérieures à 1 doivent être utilisées expérimentalement à des fins comme le brainstorming ou l’aide à la création (génération d’ébauches de scénarios, etc.) lorsqu’on souhaite des sorties variées, mais comme le risque d’hallucinations ou d’erreurs grammaticales et logiques augmente également, il est souhaitable de présupposer l’intervention et la révision humaines plutôt que l’automatisation.Pour plus de détails sur la
temperaturedes modèles de langage, il est bon de se référer aux articles suivants.
- Tamanna, Understanding LLM Temperature (2025).
- Tickr Data, The Impact of Temperature on LLM Performance (2023).
- Anik Das, Temperature in Prompt Engineering (2025).
- Peeperkorn et al., Is Temperature the Creativity Parameter of LLMs?, arXiv:2405.00492 (2024).
- Colt Steele, Understanding OpenAI’s Temperature Parameter (2023).
- Damon Garn, Understanding the role of temperature settings in AI output, TechTarget (2025).
Conception de prompts
Principes de base lors de demandes
Pour obtenir des résultats satisfaisants qui correspondent à l’objectif d’un modèle de langage, il faut fournir un prompt approprié. La conception de prompts peut sembler intimidante, mais en fait, ‘comment bien demander quelque chose’ n’est pas très différent que l’interlocuteur soit un modèle de langage ou une personne, donc si on l’aborde de ce point de vue, ce n’est pas très difficile. Il suffit d’expliquer clairement la situation actuelle et les demandes selon les principes des cinq W et un H, et si nécessaire, d’ajouter quelques exemples concrets. Il existe de nombreux conseils et techniques concernant la conception de prompts, mais la plupart dérivent des principes de base qui seront décrits ci-dessous.
Ton général
Il y a de nombreux rapports selon lesquels les modèles de langage produisent des réponses de meilleure qualité lorsque les prompts sont rédigés dans un ton de demande polie plutôt qu’avec des ordres autoritaires. Habituellement, dans la société, lorsqu’on demande quelque chose à quelqu’un d’autre, la probabilité que l’autre personne accomplisse la tâche demandée avec plus de sincérité augmente quand on demande poliment plutôt que d’ordonner de manière autoritaire, et les modèles de langage semblent apprendre et imiter ces modèles de réponse humains.
Attribution de rôle et explication de situation (qui, pourquoi)
J’ai d’abord attribué le rôle de ‘traducteur professionnel spécialisé dans les domaines techniques et scientifiques’ et fourni des informations contextuelles sur l’utilisateur comme “blogueur ingénieur qui écrit principalement sur les mathématiques, la physique et la science des données”.
1
2
3
4
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics \
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
Transmission des demandes dans le cadre général (quoi)
Ensuite, j’ai demandé de traduire le texte au format markdown fourni par l’utilisateur de {source_lang} vers {target_lang} tout en préservant le format.
1
2
3
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> \
while preserving the format.</task>
Lors de l’appel de l’API Claude, les variables de langue source et de destination sont respectivement insérées aux emplacements {source_lang} et {target_lang} du prompt grâce à la fonction f-string du script Python.
Spécification des exigences et exemples (comment)
Pour des tâches simples, les étapes précédentes peuvent suffire à obtenir les résultats souhaités, mais pour des tâches complexes, des explications supplémentaires peuvent être nécessaires.
Lorsque les conditions requises sont complexes et multiples, plutôt que de décrire chaque point en détail, il est préférable de les lister de manière concise pour améliorer la lisibilité et faciliter la compréhension pour le lecteur (qu’il soit humain ou modèle de langage). De plus, il est utile de fournir des exemples si nécessaire. Dans ce cas, j’ai ajouté les conditions suivantes.
Traitement du YAML front matter
Le YAML front matter situé au début des articles rédigés en markdown pour être téléchargés sur un blog Jekyll enregistre les informations ‘title’, ‘description’, ‘categories’ et ‘tags’. Par exemple, le YAML front matter de cet article est le suivant.
1
2
3
4
5
6
7
---
title: "Claude Sonnet 4 API로 포스트 자동 번역하는 법 (1) - 프롬프트 디자인"
description: "마크다운 텍스트 파일의 다국어 번역을 위한 프롬프트를 디자인하고, Anthropic/Gemini API 키와 작성한 프롬프트를 적용하여 Python으로 작업을 자동화하는 과정을 다룬다. 이 포스트는 해당 시리즈의 첫 번째 글로, 프롬프트 디자인 방법과 과정을 소개한다."
categories: [AI & Data, GenAI]
tags: [Jekyll, Markdown, LLM]
image: /assets/img/technology.webp
---
Cependant, lors de la traduction d’articles, les balises titre (title) et description doivent être traduites en plusieurs langues, mais pour la cohérence des URL d’articles, il est plus facile de maintenir les noms de catégories et de balises en anglais sans les traduire. J’ai donc donné l’instruction suivante pour ne pas traduire les balises autres que ‘title’ et ‘description’.
1
2
- <condition>please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
J’ai ajouté la phrase “under any circumstances, regardless of the language you are translating to” pour souligner de ne jamais modifier arbitrairement les autres balises du YAML front matter.
(Mise à jour du 02.04.12025) De plus, j’ai donné l’instruction suivante pour que le contenu de la balise description soit rédigé en quantité appropriée en considérant le SEO.
1
2
3
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
Traitement lorsque le texte original fourni contient d’autres langues que la langue source
Lors de la rédaction du texte original en coréen, il arrive souvent d’inclure l’expression anglaise entre parenthèses comme ‘atténuation neutronique (Neutron Attenuation)’ lors de l’introduction d’un concept pour la première fois ou de l’utilisation de certains termes spécialisés. Lors de la traduction de telles expressions, il y avait un problème d’incohérence dans la méthode de traduction, parfois conservant les parenthèses et parfois omettant l’anglais entre parenthèses. J’ai donc établi les directives détaillées suivantes.
- Pour les termes spécialisés,
- Lors de la traduction vers des langues non basées sur l’alphabet romain comme le japonais, maintenir le format ‘expression traduite (expression anglaise)’.
- Lors de la traduction vers des langues basées sur l’alphabet romain comme l’espagnol, le portugais, le français, permettre à la fois la notation seule ‘expression traduite’ et la notation combinée ‘expression traduite (expression anglaise)’, et laisser le modèle choisir automatiquement la plus appropriée des deux.
- Pour les noms propres, l’orthographe originale doit être préservée dans le résultat de traduction sous une forme ou une autre.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language,
please maintain the <format>[target language expression(original English expression)]</format> in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses must be preserved in the translation output in some form.</else> \n\
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese as \
'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.\
In languages such as Spanish or Portuguese, they can be translated as 'Faraday', 'Maxwell', 'Einstein', in which case, \
redundant expressions such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' would be highly inappropriate.</example>\
</condition>\n\n
Traitement des liens vers d’autres articles
Certains articles contiennent des liens vers d’autres articles, et lors de la phase de test, lorsqu’aucune directive séparée n’était fournie à ce sujet, il y avait souvent des problèmes de liens internes cassés car ils interprétaient même la partie chemin de l’URL comme devant être traduite. Ce problème a été résolu en ajoutant cette phrase au prompt.
1
2
3
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
(Mise à jour du 06.04.12025) Bien que fournir les directives ci-dessus réduise considérablement la fréquence de cassure des liens en traitant correctement la partie chemin des liens lors de la traduction, pour les liens contenant des identifiants de fragment, il y avait encore une limitation fondamentale car le modèle de langage devait encore deviner et remplir approximativement la partie identifiant de fragment sans connaître le contenu de l’article cible lié. J’ai donc amélioré le script Python et le prompt pour fournir des informations contextuelles sur les autres articles liés dans la balise XML <reference_context> du prompt utilisateur et traiter la traduction des liens selon ce contexte. Après avoir appliqué cette mise à jour, j’ai pu prévenir la plupart des problèmes de cassure de liens, et pour les articles de série étroitement liés, on peut également s’attendre à un effet de traduction plus cohérente sur plusieurs articles.
Je présente la directive suivante dans le prompt système.
1
2
3
4
5
6
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
Et la partie <reference_context> du prompt utilisateur est composée du format et du contenu suivants, fournie en plus après le contenu du texte principal à traduire.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<reference_context>
The following are contents of posts linked with hash fragments in the original post.
Use these for context when translating links and references:
<referenced_post path="{post_1_path}" hash="{hash_fragment_1}">
{post_content}
</referenced_post>
<referenced_post path="{post__2_path}" hash="{hash_fragment_2}">
{post_content}
</referenced_post>
...
</reference_context>
Pour savoir comment cela a été concrètement implémenté, consultez la partie 2 de cette série et le contenu du script Python dans le dépôt GitHub.
Produire seulement le résultat de traduction en réponse
Enfin, je présente la phrase suivante pour produire seulement le résultat de traduction sans ajouter d’autres mots lors de la réponse.
1
2
3
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
Techniques supplémentaires de conception de prompts
Cependant, contrairement aux demandes de travail aux humains, il existe également des techniques supplémentaires qui s’appliquent spécifiquement aux modèles de langage. Bien qu’il existe de nombreuses ressources utiles sur le web à ce sujet, voici quelques conseils représentatifs qui peuvent être utilisés de manière universellement utile. J’ai principalement référencé le guide d’ingénierie de prompts de la documentation officielle d’Anthropic.
Structuration utilisant des balises XML
En fait, j’ai déjà utilisé cela précédemment. Pour les prompts complexes incluant plusieurs contextes, instructions, formats et exemples, l’utilisation appropriée de balises XML comme <instructions>, <example>, <format> aide le modèle de langage à interpréter correctement le prompt et à produire une sortie de haute qualité conforme à l’intention. Le dépôt GitHub GENEXIS-AI/prompt-gallery contient une bonne compilation de balises XML utiles lors de la rédaction de prompts, je recommande de s’y référer.
Technique de raisonnement étape par étape (CoT, Chain-of-Thought)
Pour des tâches nécessitant un niveau considérable de raisonnement comme la résolution de problèmes mathématiques ou la rédaction de documents complexes, inciter le modèle de langage à réfléchir au problème étape par étape peut considérablement améliorer les performances. Cependant, dans ce cas, le temps de latence de réponse peut s’allonger, et cette technique n’est pas toujours utile pour toutes les tâches, il faut donc faire attention.
Technique de chaînage de prompts (prompt chaining)
Pour des tâches complexes, il peut y avoir des limites à répondre avec un seul prompt. Dans ce cas, on peut considérer diviser dès le départ l’ensemble du flux de travail en plusieurs étapes, présenter des prompts spécialisés pour chaque étape, et transmettre la réponse obtenue à l’étape précédente comme entrée de l’étape suivante. Cette technique est appelée chaînage de prompts.
Pré-remplissage du début de réponse
Lors de la saisie du prompt, en présentant d’abord le début du contenu à répondre et en demandant de rédiger la suite, on peut faire sauter les salutations inutiles ou forcer une réponse dans un format spécifique comme XML ou JSON. Dans le cas de l’API Anthropic, cette technique peut être utilisée en soumettant non seulement le message User mais aussi le message Assistant lors de l’appel.
Prévention de la paresse (Patch Halloween 31.10.12024)
Après avoir écrit cet article pour la première fois, bien qu’il y ait eu quelques améliorations de prompts et spécifications d’instructions supplémentaires, j’ai appliqué ce système d’automatisation pendant 4 mois sans problème majeur.
Cependant, depuis environ 18h00 le 31.10.12024 (heure coréenne), un phénomène anormal persistait où, lorsque je confiais la traduction d’un nouvel article, il ne traduisait que la première partie ‘TL;DR’ de l’article puis arrêtait arbitrairement la traduction.
Les causes présumées de ce problème et les méthodes de résolution sont traitées dans un article séparé, veuillez vous y référer.
Prompt système complété
Le résultat de la conception de prompt après les étapes ci-dessus peut être consulté dans l’article suivant.
Lecture complémentaire
Suite dans la Partie 2