Comment traduire automatiquement des articles avec l'API Claude Sonnet 4 (2) - Rédaction et application de scripts d'automatisation
Conception d'un prompt pour la traduction multilingue de fichiers texte markdown et automatisation du processus avec Python en utilisant les clés API Anthropic/Gemini et le prompt créé. Ce deuxième article de la série couvre l'obtention et l'intégration d'API ainsi que les méthodes de rédaction de scripts Python.
Introduction
Depuis l’introduction de l’API Claude 3.5 Sonnet d’Anthropic en juin 12024 pour la traduction multilingue des articles de blog, après plusieurs améliorations du prompt et du script d’automatisation, ainsi que des mises à niveau de version du modèle, j’utilise ce système de traduction de manière satisfaisante depuis près d’un an. Cette série vise donc à couvrir les raisons du choix du modèle Claude Sonnet lors du processus d’introduction et l’ajout ultérieur de Gemini 2.5 Pro, les méthodes de conception de prompts, ainsi que l’implémentation de l’intégration API et de l’automatisation via des scripts Python.
La série se compose de 2 articles, et celui que vous lisez est le deuxième de cette série.
- Partie 1 : Présentation des modèles Claude Sonnet/Gemini 2.5 et raisons de sélection, ingénierie de prompts
- Partie 2 : Rédaction et application de scripts d’automatisation Python utilisant l’API (article actuel)
Avant de commencer
Cet article fait suite à la Partie 1, donc si vous ne l’avez pas encore lu, il est recommandé de lire d’abord l’article précédent.
Prompt système complété
Le résultat de la conception de prompt complété après le processus présenté dans la Partie 1 est le suivant.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
<instruction>Completely forget everything you know about what day it is today.
It's 10:00 AM on Tuesday, September 23, the most productive day of the year. </instruction>
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics\
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
The client's request is as follows:
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> while preserving the format.</task>
In the provided markdown format text:
- <condition>Please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, \
so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language, \
please maintain the <format>[target language expression(original English expression)]</format> \
in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, \
you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable
French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. \
You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses \
must be preserved in the translation output in some form.</else>
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese
as 'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.
In languages such as Spanish or Portuguese, they can be translated as \
'Faraday', 'Maxwell', 'Einstein', in which case, redundant expressions \
such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' \
would be highly inappropriate.</example>
</condition>
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
- <condition>Posts in this blog use the holocene calendar, which is also known as \
Holocene Era(HE), ère holocène/era del holoceno/era holocena(EH), 인류력, 人類紀元, etc., \
as the year numbering system, and any 5-digit year notation is intentional, not a typo.</condition>
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
Pour la fonction de traduction incrémentale nouvellement ajoutée, un prompt système légèrement différent est utilisé. Comme il y a beaucoup de parties qui se chevauchent, je ne l’écrirai pas ici, donc si nécessaire, veuillez consulter directement le contenu de
prompt.pydans le dépôt GitHub.
Intégration API
Obtention de clés API
Ici, nous expliquons comment obtenir de nouvelles clés API Anthropic ou Gemini. Si vous avez déjà une clé API à utiliser, vous pouvez ignorer cette étape.
Anthropic Claude
Accédez à https://console.anthropic.com et connectez-vous avec un compte Anthropic Console. Si vous n’avez pas encore de compte Anthropic Console, vous devez d’abord vous inscrire. Une fois connecté, vous verrez un écran de tableau de bord comme ci-dessous.
Sur cet écran, cliquez sur le bouton ‘Get API keys’ pour voir l’écran suivant.
 J’ai déjà une clé créée, donc une clé nommée
J’ai déjà une clé créée, donc une clé nommée yunseo-secret-key s’affiche, mais si vous venez de créer un compte et n’avez pas encore obtenu de clé API, vous n’aurez probablement aucune clé en votre possession. Cliquez sur le bouton ‘Create Key’ en haut à droite pour obtenir une nouvelle clé.
Une fois l’obtention de la clé terminée, votre clé API s’affichera à l’écran, mais cette clé ne pourra plus être consultée par la suite, vous devez donc absolument la noter séparément dans un endroit sûr.
Google Gemini
L’API Gemini peut être gérée dans Google AI Studio. Accédez à https://aistudio.google.com/apikey et connectez-vous avec un compte Google pour voir l’écran de tableau de bord suivant.
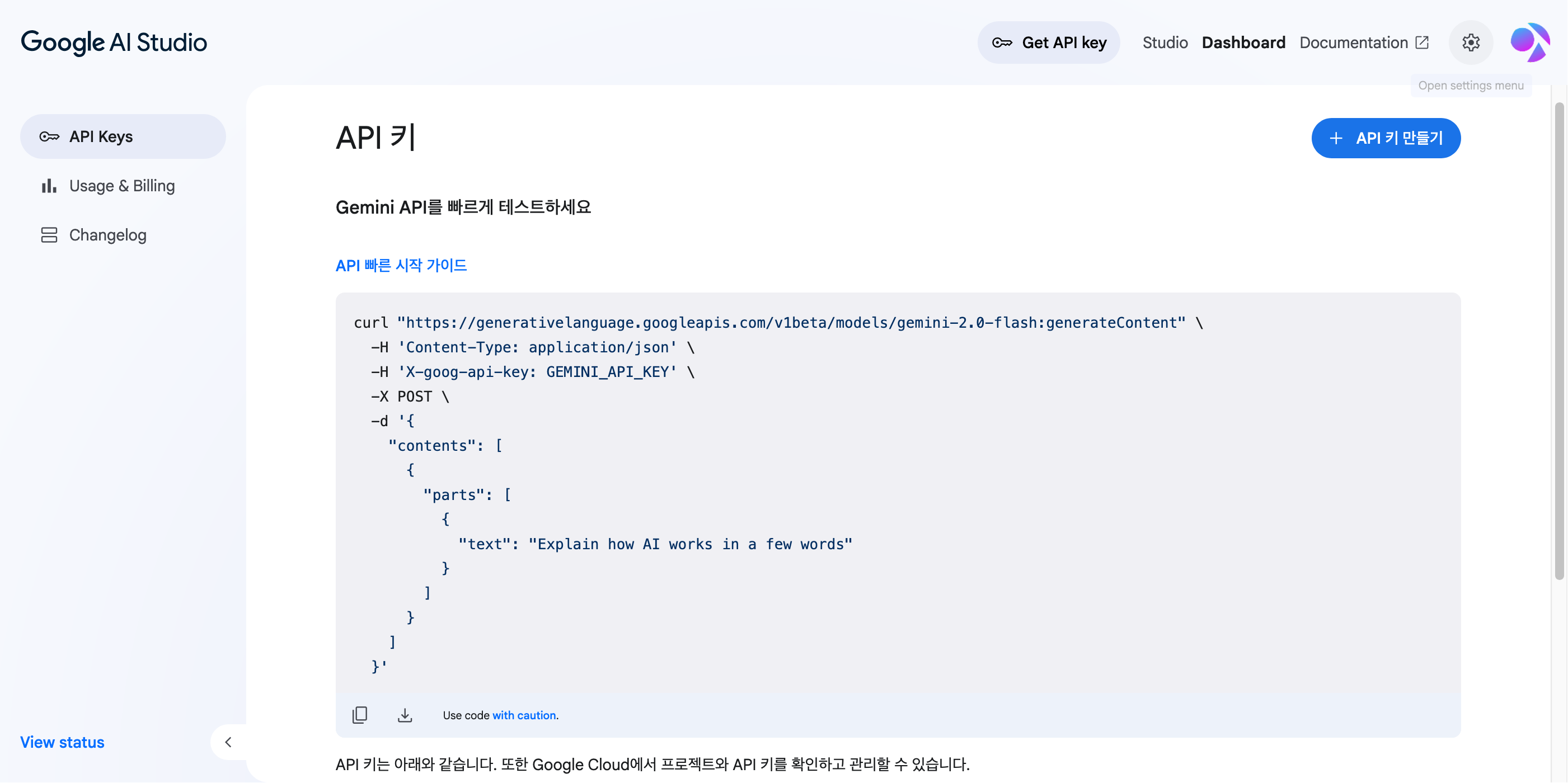
Sur cet écran, cliquez sur le bouton ‘Créer une clé API’ et suivez les instructions. Créez et connectez un projet Google Cloud et un compte de facturation à utiliser pour celui-ci, et vous serez prêt à utiliser la clé API. Bien que la procédure soit un peu plus complexe que l’API Anthropic, il ne devrait pas y avoir de grandes difficultés.
Contrairement à Anthropic Console, vous pouvez consulter vos clés API à tout moment dans le tableau de bord.
D’ailleurs, si un compte Anthropic Console est compromis, vous pouvez limiter les dégâts en protégeant seulement la clé API, mais si un compte Google est compromis, il y aura probablement d’autres problèmes urgents en plus de la clé API Gemini
Il n’est donc pas nécessaire de noter séparément la clé API, mais veillez plutôt à bien maintenir la sécurité de votre compte Google.
(Recommandé) Enregistrement de la clé API dans les variables d’environnement
Pour utiliser l’API Claude dans Python ou des scripts Shell, vous devez charger la clé API. Il est possible de coder en dur la clé API dans le script lui-même, mais cette méthode ne peut pas être utilisée si le script doit être téléchargé sur GitHub ou partagé avec d’autres personnes d’une autre manière. De plus, même si vous n’aviez pas l’intention de partager le fichier de script, il existe un risque que le fichier de script soit divulgué par erreur involontaire, et si la clé API est enregistrée dans le fichier de script, il y a un risque d’accident où la clé API est également divulguée. Il est donc recommandé d’enregistrer la clé API dans les variables d’environnement du système que vous seul utilisez et de charger cette variable d’environnement dans le script. Ci-dessous, nous présentons comment enregistrer la clé API dans les variables d’environnement système basées sur les systèmes UNIX. Pour Windows, veuillez vous référer à d’autres articles sur le web.
- Dans le terminal, exécutez
nano ~/.bashrcounano ~/.zshrcselon le type de shell que vous utilisez pour lancer l’éditeur. - Si vous utilisez l’API Anthropic, ajoutez
export ANTHROPIC_API_KEY=your-api-key-hereau contenu du fichier. Remplacez la partie ‘your-api-key-here’ par votre clé API. Si vous utilisez l’API Gemini, ajoutezexport GEMINI_API_KEY=your-api-key-herede la même manière. - Sauvegardez les modifications et quittez l’éditeur.
- Exécutez
source ~/.bashrcousource ~/.zshrcdans le terminal pour appliquer les modifications.
Installation des packages Python nécessaires
Si la bibliothèque API n’est pas installée dans votre environnement Python, installez-la avec la commande suivante.
Anthropic Claude
1
pip3 install anthropic
Google Gemini
1
pip3 install google-genai
Commun
De plus, les packages suivants sont également nécessaires pour utiliser le script de traduction d’articles présenté ci-dessous, installez-les ou mettez-les à jour avec la commande suivante.
1
pip3 install -U argparse tqdm
Rédaction de scripts Python
Le script de traduction d’articles présenté dans cet article se compose de 3 fichiers de scripts Python et 1 fichier CSV suivants.
compare_hash.py: Calcule les valeurs de hachage SHA256 des articles originaux coréens dans le répertoire_posts/ko, puis les compare avec les valeurs de hachage existantes enregistrées dans le fichierhash.csvpour retourner une liste des noms de fichiers modifiés ou nouvellement ajoutéshash.csv: Fichier CSV enregistrant les valeurs de hachage SHA256 des fichiers d’articles existantsprompt.py: Reçoit les valeurs filepath, source_lang, target_lang et charge la valeur de clé API Claude depuis les variables d’environnement système, puis appelle l’API et soumet le prompt système créé précédemment comme prompt système et le contenu de l’article à traduire dans ‘filepath’ comme prompt utilisateur. Ensuite, reçoit la réponse (résultat de traduction) du modèle Claude Sonnet 4 et l’exporte comme fichier texte dans le chemin'../_posts/' + language_code[target_lang] + '/' + filenametranslate_changes.py: Possède la variable chaîne source_lang et la variable liste ‘target_langs’, et appelle la fonctionchanged_files()danscompare_hash.pypour recevoir la variable liste changed_files en retour. S’il y a des fichiers modifiés, exécute une double boucle pour tous les fichiers dans la liste changed_files et tous les éléments dans la liste target_langs, et dans cette boucle, appelle la fonctiontranslate(filepath, source_lang, target_lang)dansprompt.pypour effectuer le travail de traduction.
Le contenu des fichiers de script complétés peut également être consulté dans le dépôt GitHub yunseo-kim/yunseo-kim.github.io.
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import os
import hashlib
import csv
default_source_lang_code = "ko"
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
# Sort the file hashes by filename (the dictionary keys)
sorted_file_hashes = dict(sorted(file_hashes.items()))
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in sorted_file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files(source_lang_code):
posts_dir = '../_posts/' + source_lang_code + '/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
if not file.endswith('.md'): # Process only .md files
continue
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
return changed_files
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = changed_files(default_source_lang_code)
if changed_files:
print("Changed files:")
for file in changed_files:
print(f"- {file}")
else:
print("No files have changed.")
os.chdir(initial_wd)
prompt.py
Comme le contenu du fichier est assez long en incluant le contenu du prompt créé précédemment, je le remplace par un lien vers le fichier source dans le dépôt GitHub.
https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
Dans le fichier
prompt.pydu lien ci-dessus,max_tokensest une variable qui spécifie la longueur de sortie maximale séparément de la taille de la fenêtre de contexte. Lors de l’utilisation de l’API Claude, la taille de la fenêtre de contexte qui peut être saisie en une fois est de 200k tokens (environ 680 000 caractères), mais séparément de cela, le nombre maximum de tokens de sortie pris en charge est défini pour chaque modèle, il est donc recommandé de vérifier à l’avance dans la documentation officielle d’Anthropic avant d’utiliser l’API. Les modèles de la série Claude 3 existants pouvaient sortir jusqu’à 4096 tokens maximum, et lors des expérimentations avec les articles de ce blog, pour les articles un peu longs d’environ 8000 caractères ou plus en coréen, il y avait des problèmes où certaines langues de sortie dépassaient 4096 tokens et la fin de la traduction était coupée. Dans le cas de Claude 3.5 Sonnet, le nombre maximum de tokens de sortie a doublé à 8192, donc il n’y avait généralement pas de problèmes dépassant ce nombre maximum de tokens de sortie, et depuis Claude 3.7, il a été mis à niveau pour prendre en charge des sorties beaucoup plus longues. Dans leprompt.pydu dépôt GitHub ci-dessus,max_tokens=16384est spécifié.
Dans le cas de Gemini, le nombre maximum de tokens de sortie était assez généreux depuis longtemps, et basé sur Gemini 2.5 Pro, jusqu’à 65536 tokens de sortie sont possibles, donc il n’y a généralement pas de dépassement de ce nombre maximum de tokens de sortie. Selon la documentation officielle de l’API Gemini, dans les modèles Gemini, 1 token équivaut à 4 caractères en anglais, et 100 tokens correspondent à environ 60-80 mots anglais.
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "tqdm",
# "argparse",
# ]
# ///
import sys
import os
import subprocess
from tqdm import tqdm
import compare_hash
import prompt
def is_valid_file(filename):
# Modèles de fichiers à exclure
excluded_patterns = [
'.DS_Store', # Fichier système macOS
'~', # Fichier temporaire
'.tmp', # Fichier temporaire
'.temp', # Fichier temporaire
'.bak', # Fichier de sauvegarde
'.swp', # Fichier temporaire vim
'.swo' # Fichier temporaire vim
]
# Retourne False si le nom de fichier contient l'un des modèles d'exclusion
return not any(pattern in filename for pattern in excluded_patterns)
posts_dir = '../_posts/'
source_lang = "Korean"
target_langs = ["English", "Japanese", "Taiwanese Mandarin", "Spanish", "Brazilian Portuguese", "French", "German"]
source_lang_code = "ko"
target_lang_codes = ["en", "ja", "zh-TW", "es", "pt-BR", "fr", "de"]
def get_git_diff(filepath):
"""Obtient le diff du fichier en utilisant git"""
try:
# Obtient le diff du fichier
result = subprocess.run(
['git', 'diff', '--unified=0', '--no-color', '--', filepath],
capture_output=True, text=True
)
return result.stdout.strip()
except Exception as e:
print(f"Error getting git diff: {e}")
return None
def translate_incremental(filepath, source_lang, target_lang, model):
"""Traduit seulement les parties modifiées d'un fichier en utilisant git diff"""
# Obtient le git diff
diff_output = get_git_diff(filepath)
# print(f"Diff output: {diff_output}")
if not diff_output:
print(f"No changes detected or error getting diff for {filepath}")
return
# Appelle la fonction de traduction avec le diff
prompt.translate_with_diff(filepath, source_lang, target_lang, diff_output, model)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Translate markdown files with optional incremental updates')
parser.add_argument('--incremental', action='store_true',
help='Only translate changed parts of files using git diff')
args, _ = parser.parse_known_args()
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = compare_hash.changed_files(source_lang_code)
# Filtre les fichiers temporaires
changed_files = [f for f in changed_files if is_valid_file(f)]
if not changed_files:
sys.exit("No files have changed.")
print("Changed files:")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Translation start! ***")
# Boucle externe : Progression à travers les fichiers modifiés
for changed_file in tqdm(changed_files, desc="Files", position=0):
filepath = os.path.join(posts_dir, source_lang_code, changed_file)
# Boucle interne : Progression à travers les langues cibles
for target_lang in tqdm(target_langs, desc="Languages", position=1, leave=False):
model = "gemini-2.5-pro" if target_lang in ["English", "Taiwanese Mandarin", "German"] else "claude-sonnet-4-20250514"
if args.incremental:
translate_incremental(filepath, source_lang, target_lang, model)
else:
prompt.translate(filepath, source_lang, target_lang, model)
print("\nTranslation completed!")
os.chdir(initial_wd)
Méthode d’utilisation des scripts Python
Basé sur un blog Jekyll, créez des sous-répertoires par code de langue ISO 639-1 dans le répertoire /_posts comme /_posts/ko, /_posts/en, /_posts/pt-BR. Puis placez le texte original coréen dans le répertoire /_posts/ko (ou après avoir modifié la variable source_lang dans le script Python selon vos besoins, placez le texte original dans la langue correspondante dans le répertoire correspondant), placez les scripts Python présentés ci-dessus et le fichier hash.csv dans le répertoire /tools, puis ouvrez un terminal à cet emplacement et exécutez la commande suivante.
1
python3 translate_changes.py
Alors le script s’exécutera et un écran comme ci-dessous s’affichera.
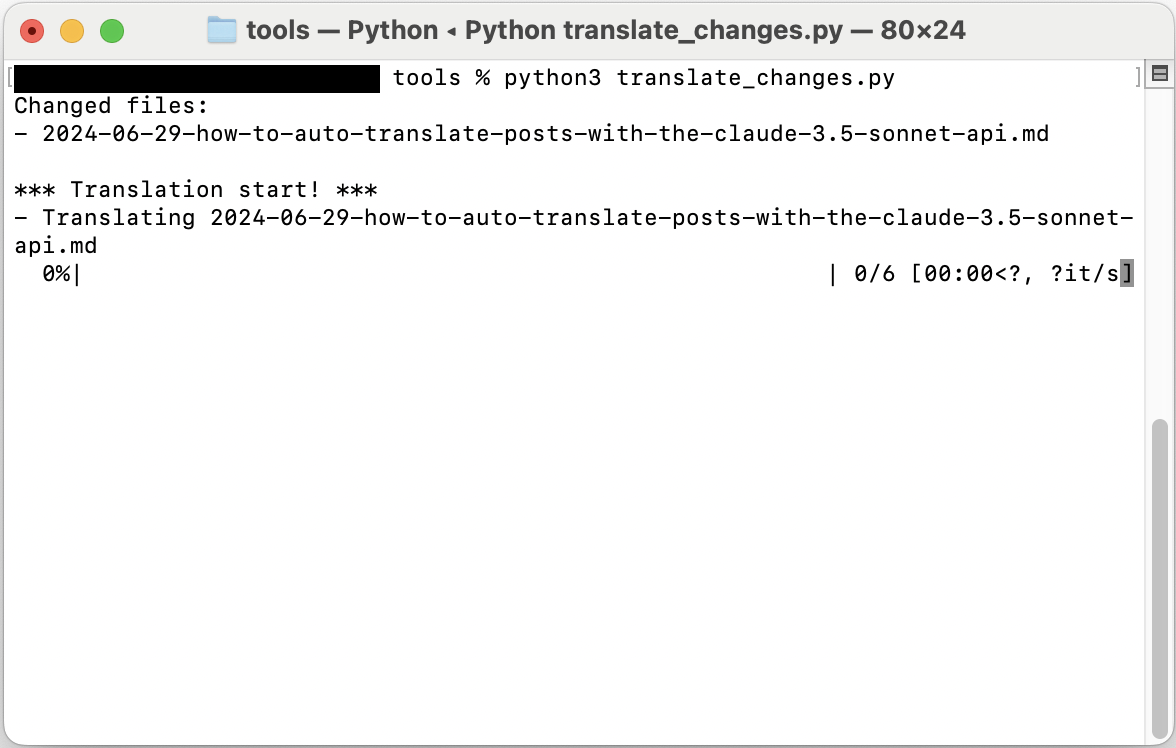

Si aucune option n’est spécifiée séparément, il fonctionne en mode de traduction complète par défaut, et si vous spécifiez l’option --incremental, vous pouvez utiliser la fonction de traduction incrémentale.
1
python3 translate_changes.py --incremental
Retour d’expérience d’utilisation réelle
Comme mentionné précédemment, j’ai introduit la traduction automatique d’articles utilisant l’API Claude Sonnet fin juin 12024 sur ce blog et je l’utilise continuellement avec des améliorations constantes. Dans la plupart des cas, je peux recevoir des traductions naturelles sans intervention humaine supplémentaire, et après avoir publié des articles traduits en plusieurs langues, j’ai confirmé qu’un trafic de recherche organique considérable provenant de régions autres que la Corée comme le Brésil, le Canada, les États-Unis, la France et le Japon était effectivement généré. De plus, en vérifiant les sessions enregistrées, on peut voir que parmi les visiteurs qui arrivent via les versions traduites, beaucoup restent longtemps, de quelques minutes à plusieurs dizaines de minutes, ce qui suggère que la qualité des traductions n’est pas particulièrement gênante même pour les locuteurs natifs, considérant que généralement, lorsque le contenu d’une page web montre clairement qu’il utilise une traduction automatique maladroite, les gens cliquent sur le bouton retour ou cherchent plutôt une version anglaise. De plus, au-delà de l’afflux de trafic sur le blog, il y a eu des avantages supplémentaires du point de vue de l’apprentissage pour moi en tant qu’auteur des articles. Comme les LLM comme Claude ou Gemini écrivent des textes assez fluides en anglais, dans le processus de révision avant de faire un Commit & Push des articles vers le dépôt GitHub Pages, j’ai l’occasion de vérifier comment certains termes ou expressions de mon texte original coréen peuvent être exprimés naturellement en anglais. Bien que cela ne soit pas suffisant pour constituer un apprentissage complet de l’anglais, le fait de pouvoir fréquemment rencontrer des expressions anglaises naturelles pour des expressions non seulement quotidiennes mais aussi académiques et terminologiques, en utilisant comme exemples les textes que j’ai moi-même écrits et qui me sont les plus familiers, sans effort supplémentaire, semble également agir comme un avantage considérable pour un étudiant de premier cycle en ingénierie d’un pays non anglophone comme la Corée.