Como Traduzir Posts Automaticamente com a API do Claude Sonnet 4 (2) - Criação e Aplicação de Script de Automação
Aborda o processo de design de prompts para tradução multilíngue de arquivos de texto markdown e automação do trabalho com Python aplicando chaves de API da Anthropic/Gemini e os prompts criados. Este post é o segundo da série, apresentando métodos de emissão de API, integração e criação de scripts Python.
Introdução
Desde a introdução da API do Claude 3.5 Sonnet da Anthropic para tradução multilíngue de posts do blog em junho de 12024, após várias melhorias de prompt e script de automação, além de atualizações de versão do modelo, tenho operado satisfatoriamente esse sistema de tradução por quase um ano. Nesta série, pretendo abordar as razões para escolher o modelo Claude Sonnet no processo de introdução e posteriormente adicionar o Gemini 2.5 Pro, métodos de design de prompt, e implementação de integração de API e automação através de scripts Python.
A série consiste em 2 artigos, e este que você está lendo é o segundo da série.
- Parte 1: Introdução aos modelos Claude Sonnet/Gemini 2.5 e razões para seleção, engenharia de prompt
- Parte 2: Criação e aplicação de script de automação Python utilizando API (texto atual)
Antes de Começar
Este artigo é uma continuação da Parte 1, então se ainda não leu, recomendo ler o artigo anterior primeiro.
Prompt do Sistema Finalizado
O resultado do design de prompt finalizado através do processo apresentado na Parte 1 é o seguinte.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
<instruction>Completely forget everything you know about what day it is today.
It's 10:00 AM on Tuesday, September 23, the most productive day of the year. </instruction>
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics\
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
The client's request is as follows:
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> while preserving the format.</task>
In the provided markdown format text:
- <condition>Please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, \
so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language, \
please maintain the <format>[target language expression(original English expression)]</format> \
in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, \
you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable
French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. \
You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses \
must be preserved in the translation output in some form.</else>
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese
as 'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.
In languages such as Spanish or Portuguese, they can be translated as \
'Faraday', 'Maxwell', 'Einstein', in which case, redundant expressions \
such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' \
would be highly inappropriate.</example>
</condition>
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
- <condition>Posts in this blog use the holocene calendar, which is also known as \
Holocene Era(HE), ère holocène/era del holoceno/era holocena(EH), 인류력, 人類紀元, etc., \
as the year numbering system, and any 5-digit year notation is intentional, not a typo.</condition>
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
Para a funcionalidade de tradução incremental recém-adicionada, utiliza-se um prompt do sistema ligeiramente diferente. Como há muitas partes sobrepostas, não incluirei aqui, então se necessário, consulte diretamente o conteúdo do
prompt.pyno repositório GitHub.
Integração de API
Emissão de Chave de API
Aqui explico como emitir uma nova chave de API da Anthropic ou Gemini. Se já possui uma chave de API para usar, pode pular esta etapa.
Anthropic Claude
Acesse https://console.anthropic.com e faça login com sua conta do Anthropic Console. Se ainda não possui uma conta do Anthropic Console, deve primeiro fazer o cadastro. Após o login, verá uma tela de dashboard como a seguinte.
Nesta tela, clique no botão ‘Get API keys’ para ver a seguinte tela.
 Como já tenho uma chave criada, aparece uma chave chamada
Como já tenho uma chave criada, aparece uma chave chamada yunseo-secret-key, mas se acabou de criar a conta e ainda não emitiu uma chave de API, provavelmente não terá nenhuma chave. Clique no botão ‘Create Key’ no canto superior direito para emitir uma nova chave.
Após completar a emissão da chave, sua chave de API será exibida na tela, mas como não poderá verificá-la novamente depois, certifique-se de anotá-la em um local seguro.
Google Gemini
A API do Gemini pode ser gerenciada no Google AI Studio. Acesse https://aistudio.google.com/apikey e faça login com sua conta Google para ver a seguinte tela de dashboard.
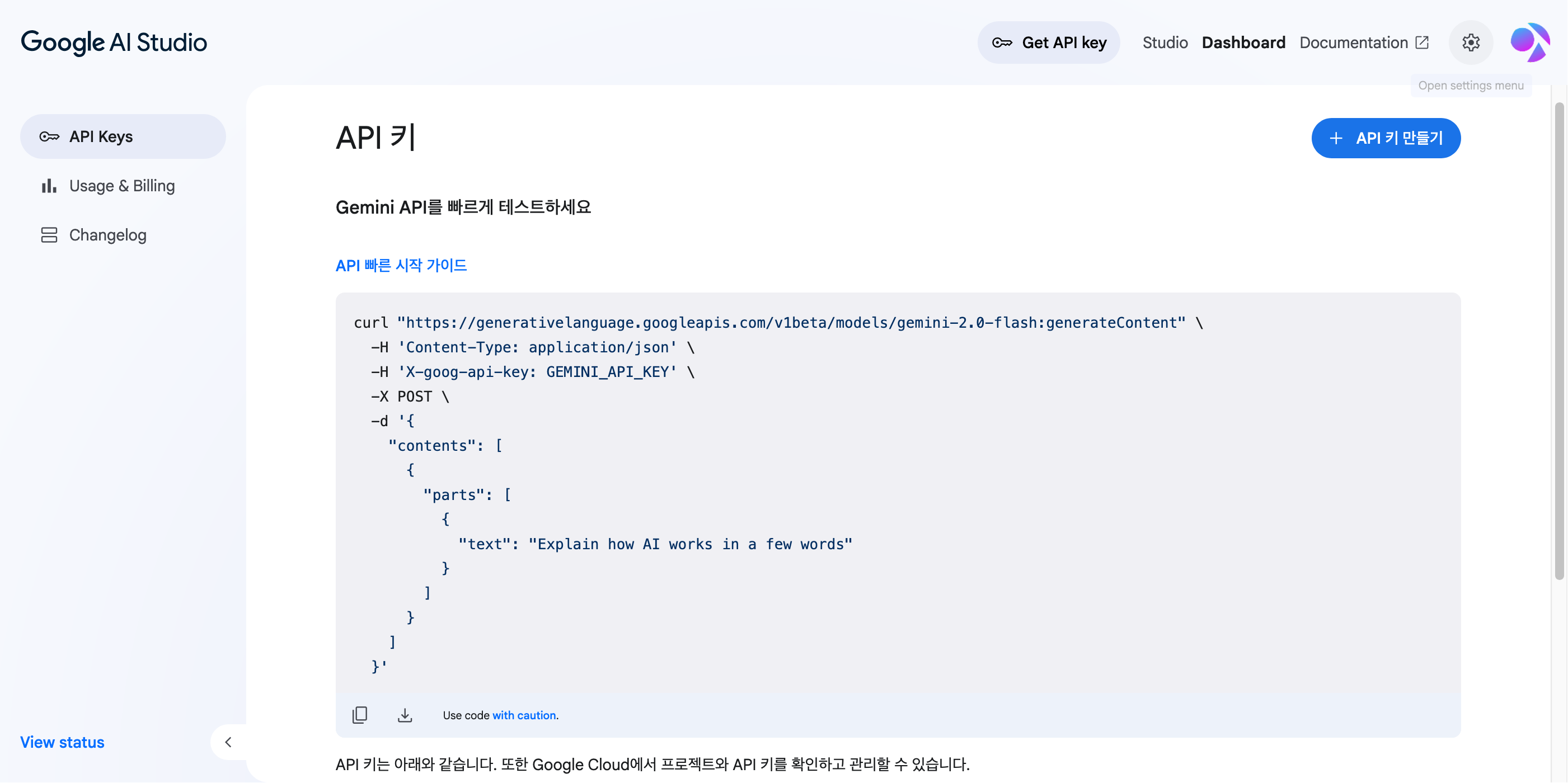
Nesta tela, clique no botão ‘Criar chave de API’ e siga as instruções. Você precisará criar um projeto do Google Cloud e conectar uma conta de cobrança para usar, então o processo é um pouco mais complexo que a API da Anthropic, mas não deve ser muito difícil.
Diferentemente do Anthropic Console, você pode verificar suas chaves de API a qualquer momento no dashboard.
Afinal, se sua conta do Anthropic Console for comprometida, você pode limitar os danos protegendo apenas a chave de API, mas se sua conta Google for comprometida, há problemas muito mais urgentes além da chave de API do Gemini
Portanto, não é necessário anotar a chave de API separadamente, mas certifique-se de manter a segurança de sua conta Google.
(Recomendado) Registrar Chave de API em Variável de Ambiente
Para usar a API do Claude em scripts Python ou Shell, você precisa carregar a chave de API. Embora seja possível codificar a chave de API diretamente no script, este método não pode ser usado se o script precisar ser carregado no GitHub ou compartilhado com outras pessoas de outras formas. Além disso, mesmo que não tenha intenção de compartilhar o arquivo de script, existe o risco de vazamento acidental do arquivo de script, e se a chave de API estiver registrada no arquivo de script, a chave de API também pode vazar junto. Portanto, recomenda-se registrar a chave de API nas variáveis de ambiente do sistema que apenas você usa e carregar essa variável de ambiente no script. Abaixo apresento como registrar a chave de API nas variáveis de ambiente do sistema baseado em sistemas UNIX. Para Windows, consulte outros artigos na web.
- No terminal, execute
nano ~/.bashrcounano ~/.zshrcde acordo com o tipo de shell que você usa para abrir o editor. - Se usar a API da Anthropic, adicione
export ANTHROPIC_API_KEY=your-api-key-hereao conteúdo do arquivo. Substitua ‘your-api-key-here’ pela sua chave de API. Se usar a API do Gemini, adicioneexport GEMINI_API_KEY=your-api-key-hereda mesma forma. - Salve as alterações e saia do editor.
- Execute
source ~/.bashrcousource ~/.zshrcno terminal para aplicar as alterações.
Instalar Pacotes Python Necessários
Se as bibliotecas de API não estiverem instaladas em seu ambiente Python, instale-as com os seguintes comandos.
Anthropic Claude
1
pip3 install anthropic
Google Gemini
1
pip3 install google-genai
Comum
Além disso, os seguintes pacotes também são necessários para usar o script de tradução de posts que será apresentado posteriormente, então instale ou atualize com o seguinte comando.
1
pip3 install -U argparse tqdm
Criação de Script Python
O script de tradução de posts apresentado neste artigo consiste em 3 arquivos de script Python e 1 arquivo CSV.
compare_hash.py: Calcula os valores de hash SHA256 dos posts originais em coreano no diretório_posts/ko, compara com os valores de hash existentes registrados no arquivohash.csve retorna uma lista de nomes de arquivos alterados ou recém-adicionadoshash.csv: Arquivo CSV que registra os valores de hash SHA256 dos arquivos de posts existentesprompt.py: Recebe valores de filepath, source_lang, target_lang, carrega o valor da chave de API do Claude das variáveis de ambiente do sistema, chama a API e submete o prompt criado anteriormente como prompt do sistema e o conteúdo do post a ser traduzido em ‘filepath’ como prompt do usuário. Depois recebe a resposta (resultado da tradução) do modelo Claude Sonnet 4 e produz como arquivo de texto no caminho'../_posts/' + language_code[target_lang] + '/' + filenametranslate_changes.py: Possui a variável string source_lang e a variável lista ‘target_langs’, chama a funçãochanged_files()dentro decompare_hash.pypara receber a variável lista changed_files. Se houver arquivos alterados, executa um loop duplo para todos os arquivos na lista changed_files e todos os elementos na lista target_langs, e dentro desse loop chama a funçãotranslate(filepath, source_lang, target_lang)dentro deprompt.pypara executar o trabalho de tradução.
O conteúdo dos arquivos de script finalizados também pode ser verificado no repositório GitHub yunseo-kim/yunseo-kim.github.io.
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import os
import hashlib
import csv
default_source_lang_code = "ko"
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
# Sort the file hashes by filename (the dictionary keys)
sorted_file_hashes = dict(sorted(file_hashes.items()))
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in sorted_file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files(source_lang_code):
posts_dir = '../_posts/' + source_lang_code + '/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
if not file.endswith('.md'): # Process only .md files
continue
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
return changed_files
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = changed_files(default_source_lang_code)
if changed_files:
print("Changed files:")
for file in changed_files:
print(f"- {file}")
else:
print("No files have changed.")
os.chdir(initial_wd)
prompt.py
Como o conteúdo do arquivo é longo devido ao prompt criado anteriormente, substituo pelo link do arquivo fonte no repositório GitHub.
https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
No arquivo
prompt.pydo link acima,max_tokensé uma variável que especifica o comprimento máximo de saída separadamente do tamanho da janela de contexto. Ao usar a API do Claude, o tamanho da janela de contexto que pode ser inserida de uma vez é de 200k tokens (aproximadamente 680.000 caracteres), mas separadamente disso, há um número máximo de tokens de saída suportado para cada modelo, então recomenda-se verificar antecipadamente na documentação oficial da Anthropic antes de usar a API. Os modelos da série Claude 3 existentes podiam produzir até 4096 tokens, mas quando testei com os artigos deste blog, para posts um pouco longos com mais de 8000 caracteres em coreano, alguns idiomas de saída excediam 4096 tokens, causando o problema de corte da parte final da tradução. No caso do Claude 3.5 Sonnet, o número máximo de tokens de saída dobrou para 8192, então raramente havia problemas de exceder esse número máximo de tokens de saída, e a partir do Claude 3.7, foi atualizado para suportar saídas muito mais longas. Noprompt.pydo repositório GitHub acima, está definido comomax_tokens=16384.
No caso do Gemini, o número máximo de tokens de saída sempre foi bastante generoso, e baseado no Gemini 2.5 Pro, é possível produzir até 65536 tokens, então raramente há problema de exceder esse número máximo de tokens de saída. De acordo com a documentação oficial da API do Gemini, nos modelos Gemini, 1 token equivale a 4 caracteres em inglês, e 100 tokens correspondem a aproximadamente 60-80 palavras em inglês.
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "tqdm",
# "argparse",
# ]
# ///
import sys
import os
import subprocess
from tqdm import tqdm
import compare_hash
import prompt
def is_valid_file(filename):
# 제외할 파일 패턴들
excluded_patterns = [
'.DS_Store', # macOS 시스템 파일
'~', # 임시 파일
'.tmp', # 임시 파일
'.temp', # 임시 파일
'.bak', # 백업 파일
'.swp', # vim 임시 파일
'.swo' # vim 임시 파일
]
# 파일명이 제외 패턴 중 하나라도 포함하면 False 반환
return not any(pattern in filename for pattern in excluded_patterns)
posts_dir = '../_posts/'
source_lang = "Korean"
target_langs = ["English", "Japanese", "Taiwanese Mandarin", "Spanish", "Brazilian Portuguese", "French", "German"]
source_lang_code = "ko"
target_lang_codes = ["en", "ja", "zh-TW", "es", "pt-BR", "fr", "de"]
def get_git_diff(filepath):
"""Get the diff of the file using git"""
try:
# Get the diff of the file
result = subprocess.run(
['git', 'diff', '--unified=0', '--no-color', '--', filepath],
capture_output=True, text=True
)
return result.stdout.strip()
except Exception as e:
print(f"Error getting git diff: {e}")
return None
def translate_incremental(filepath, source_lang, target_lang, model):
"""Translate only the changed parts of a file using git diff"""
# Get the git diff
diff_output = get_git_diff(filepath)
# print(f"Diff output: {diff_output}")
if not diff_output:
print(f"No changes detected or error getting diff for {filepath}")
return
# Call the translation function with the diff
prompt.translate_with_diff(filepath, source_lang, target_lang, diff_output, model)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Translate markdown files with optional incremental updates')
parser.add_argument('--incremental', action='store_true',
help='Only translate changed parts of files using git diff')
args, _ = parser.parse_known_args()
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = compare_hash.changed_files(source_lang_code)
# Filter temporary files
changed_files = [f for f in changed_files if is_valid_file(f)]
if not changed_files:
sys.exit("No files have changed.")
print("Changed files:")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Translation start! ***")
# Outer loop: Progress through changed files
for changed_file in tqdm(changed_files, desc="Files", position=0):
filepath = os.path.join(posts_dir, source_lang_code, changed_file)
# Inner loop: Progress through target languages
for target_lang in tqdm(target_langs, desc="Languages", position=1, leave=False):
model = "gemini-2.5-pro" if target_lang in ["English", "Taiwanese Mandarin", "German"] else "claude-sonnet-4-20250514"
if args.incremental:
translate_incremental(filepath, source_lang, target_lang, model)
else:
prompt.translate(filepath, source_lang, target_lang, model)
print("\nTranslation completed!")
os.chdir(initial_wd)
Como Usar o Script Python
Baseado no blog Jekyll, dentro do diretório /_posts, crie subdiretórios por código de idioma ISO 639-1 como /_posts/ko, /_posts/en, /_posts/pt-BR. Coloque o texto original em coreano no diretório /_posts/ko (ou modifique a variável source_lang no script Python conforme necessário e coloque o texto original no idioma correspondente no diretório correspondente), coloque os scripts Python apresentados acima e o arquivo hash.csv no diretório /tools, abra o terminal nessa localização e execute o seguinte comando.
1
python3 translate_changes.py
Então o script será executado e uma tela como a seguinte será exibida.
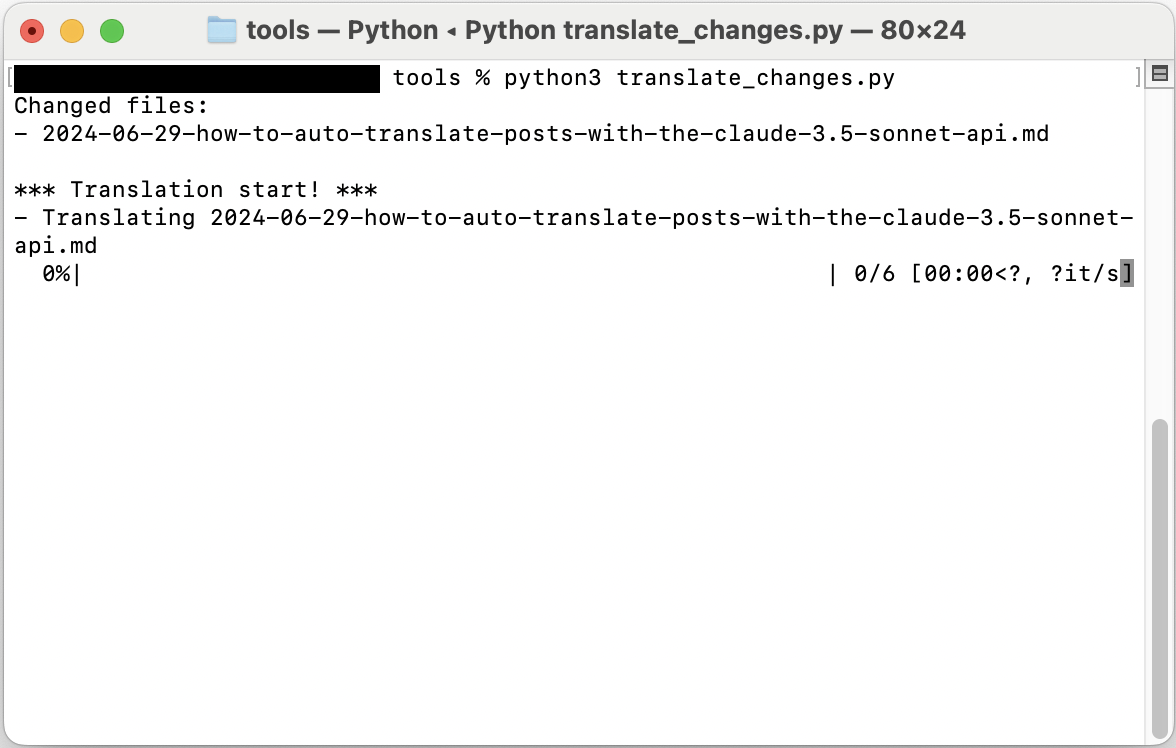

Se não especificar opções separadamente, funciona no modo de tradução completa padrão, e se especificar a opção --incremental, pode usar a funcionalidade de tradução incremental.
1
python3 translate_changes.py --incremental
Experiência de Uso Real
Como mencionado anteriormente, introduzi a tradução automática de posts usando a API do Claude Sonnet no final de junho de 12024 neste blog e tenho usado continuamente com melhorias. Na maioria dos casos, posso receber traduções naturais sem necessidade de intervenção humana adicional, e após publicar posts traduzidos em múltiplos idiomas, confirmei que há um influxo considerável de tráfego de Busca Orgânica através de pesquisas de regiões fora da Coreia, como Brasil, Canadá, Estados Unidos, França e Japão. Além disso, ao verificar as sessões gravadas, muitos visitantes que chegaram através das traduções permanecem por vários minutos ou até dezenas de minutos, o que sugere que a qualidade das traduções não é muito estranha mesmo para falantes nativos, considerando que normalmente as pessoas voltam ou procuram a versão em inglês quando o conteúdo da página web mostra sinais óbvios de tradução automática. Além do influxo de tráfego do blog, também houve vantagens adicionais do ponto de vista de aprendizado para mim como autor dos artigos. Como LLMs como Claude ou Gemini escrevem textos bastante fluidos em inglês, no processo de revisão antes de fazer Commit & Push dos posts no repositório do GitHub Pages, tenho a oportunidade de verificar como certas terminologias ou expressões do meu texto original em coreano podem ser expressas naturalmente em inglês. Embora isso sozinho não seja suficiente para um aprendizado completo de inglês, poder ter contato frequente com expressões naturais em inglês não apenas cotidianas, mas também acadêmicas e terminológicas, usando como exemplo os artigos que eu mesmo escrevi e que são mais familiares que qualquer outro texto, sem esforço adicional, parece ser uma vantagem considerável para um estudante de engenharia de graduação em um país não anglófono como a Coreia.