如何使用 Claude Sonnet 4 API 自動翻譯文章 (1) - 提示詞設計
本篇文章將探討如何為 Markdown 文件的多語言翻譯設計提示詞,並使用 Anthropic/Gemini API 金鑰與設計好的提示詞,透過 Python 將翻譯工作自動化。本文為系列第一篇,將介紹提示詞設計的方法與過程。
前言
自從 12024 年 6 月為了部落格文章的多語言翻譯而導入 Anthropic 的 Claude 3.5 Sonnet API 後,經過數次提示詞及自動化腳本的改善,以及模型版本的升級,這套翻譯系統已經穩定運作了將近一年,成果令人滿意。因此,本系列文章將探討當初選擇 Claude Sonnet 模型,以及後來追加導入 Gemini 2.5 Pro 的原因、提示詞的設計方法,還有如何透過 Python 腳本與 API 串接,實現自動化。 本系列共分為兩篇文章,您正在閱讀的是系列的第一篇。
- 第 1 篇:Claude Sonnet/Gemini 2.5 模型介紹與選擇原因、提示詞工程(本文)
- 第 2 篇:運用 API 編寫 Python 自動化腳本及應用
關於 Claude Sonnet
Claude 系列模型根據模型大小,提供 Haiku、Sonnet 和 Opus 三種版本。 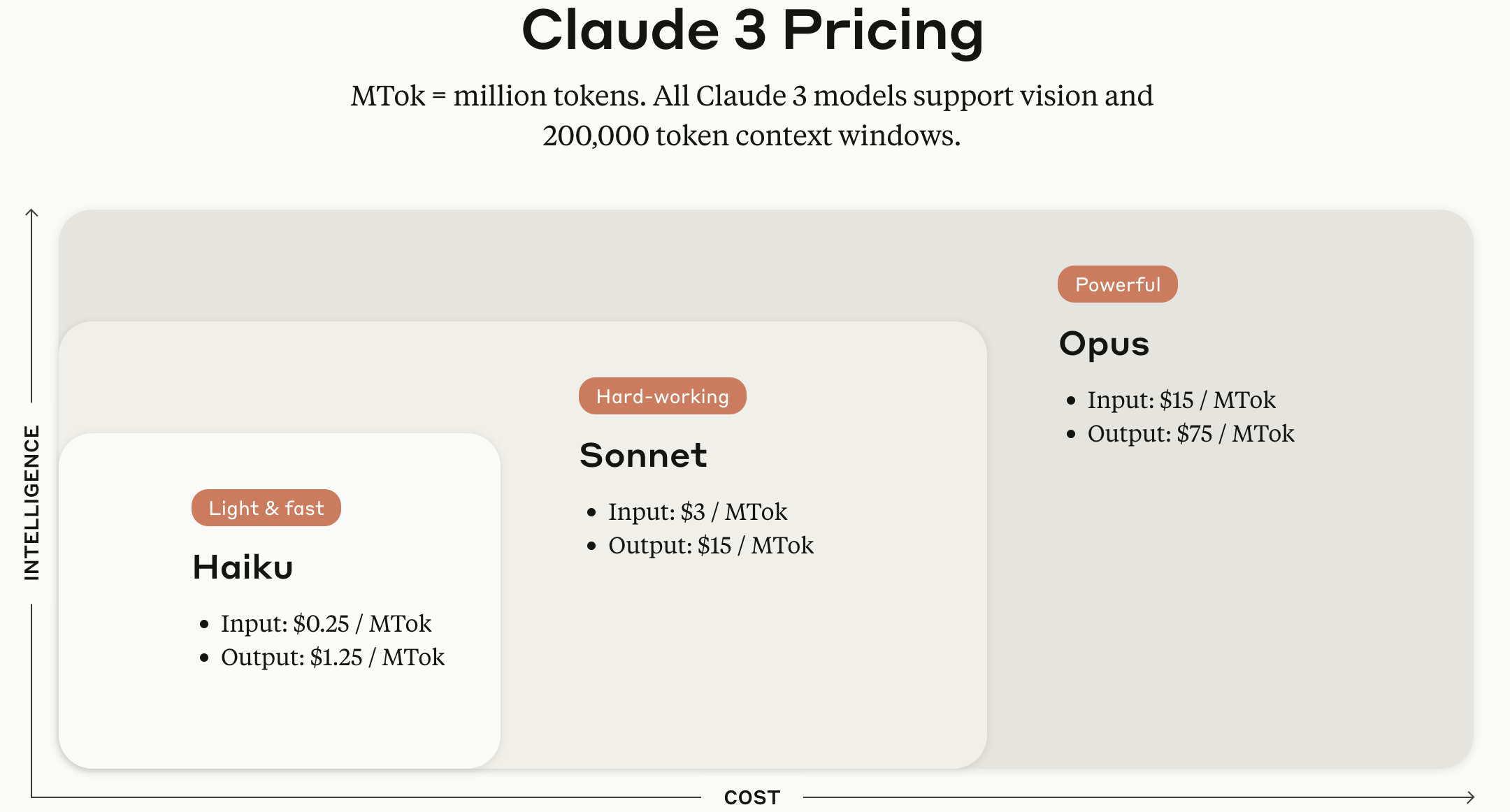
(12025.05.29. 補充) 這張圖是一年前截的,所以每 token 的費用是舊版 Claude 3 的標準,但根據模型大小劃分為 Haiku、Sonnet、Opus 的方式仍然有效。截至 12025 年 5 月底,Anthropic 提供的各模型定價如下。
Model 基本輸入
Tokens5分鐘快取
寫入1小時快取
寫入快取命中與
刷新輸出
TokensClaude Opus 4 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Sonnet 4 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.7 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.5 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Haiku 3.5 $0.80 / MTok $1 / MTok $1.6 / MTok $0.08 / MTok $4 / MTok Claude Opus 3 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Haiku 3 $0.25 / MTok $0.30 / MTok $0.50 / MTok $0.03 / MTok $1.25 / MTok
而在韓國時間 人類紀元 12024 年 6 月 21 日,Anthropic 公開了語言模型 Claude 3.5 Sonnet。它以與既有 Claude 3 Sonnet 相同的成本和速度,展現出超越 Claude 3 Opus 的推理性能。普遍評價認為,它在寫作、語言推理、多語言理解及翻譯等領域,相較於競爭模型 GPT-4 更具優勢。 
圖片來源:Anthropic Newsroom
為何選擇 Claude 3.5 來翻譯文章
即使不使用像 Claude 3.5 或 GPT-4 這樣的語言模型,市面上也存在如 Google 翻譯或 DeepL 等既有的商業翻譯 API。儘管如此,我決定使用 LLM 進行翻譯的原因是,與其他商業翻譯服務不同,使用者可以透過設計提示詞,向模型提供除了本文內容之外的額外脈絡資訊或要求,例如文章的寫作目的或主要主題,而模型能夠據此提供考量到上下文的翻譯。
雖然 DeepL 或 Google 翻譯通常也提供相當出色的翻譯品質,但它們的侷限在於無法很好地掌握文章的主題或整體脈絡,也無法傳達複雜的要求。因此,當要求翻譯非日常對話、主題專業的長篇文章時,翻譯結果有時會顯得不自然,並且難以精確地按照特定格式(如 Markdown、YAML frontmatter 等)輸出。
特別是 Claude,如前所述,在寫作、語言推理、多語言理解及翻譯等領域,普遍被認為比競爭模型 GPT-4 更為出色。經過我自己的簡單測試,也發現其翻譯品質比 GPT-4 更為流暢。因此,在考慮導入的 12024 年 6 月當時,我判斷它非常適合用來將本部落格上刊載的工程相關韓文文章翻譯成多種語言。
更新歷程
12024.07.01.
正如在另一篇文章中所整理的,我完成了套用 Polyglot 外掛並相應修改 _config.yml、HTML 標頭和 sitemap 的初步工作。 接著,我選擇了 Claude 3.5 Sonnet 模型進行翻譯,並在完成本系列所討論的 API 串接 Python 腳本的初步實現與驗證後,將其應用於部落格。
12024.10.31.
12024 年 10 月 22 日,Anthropic 發布了 Claude 3.5 Sonnet 的升級版 API (”claude-3-5-sonnet-20241022”)和 Claude 3.5 Haiku。但由於下文將提到的問題,本部落格目前仍沿用既有的 “claude-3-5-sonnet-20240620” API。
12025.04.02.
將應用模型從 “claude-3-5-sonnet-20240620” 切換為 “claude-3-7-sonnet-20250219”。
12025.05.29.
將應用模型從 “claude-3-7-sonnet-20250219” 切換為 “claude-sonnet-4-20250514”。
圖片來源:Anthropic Newsroom
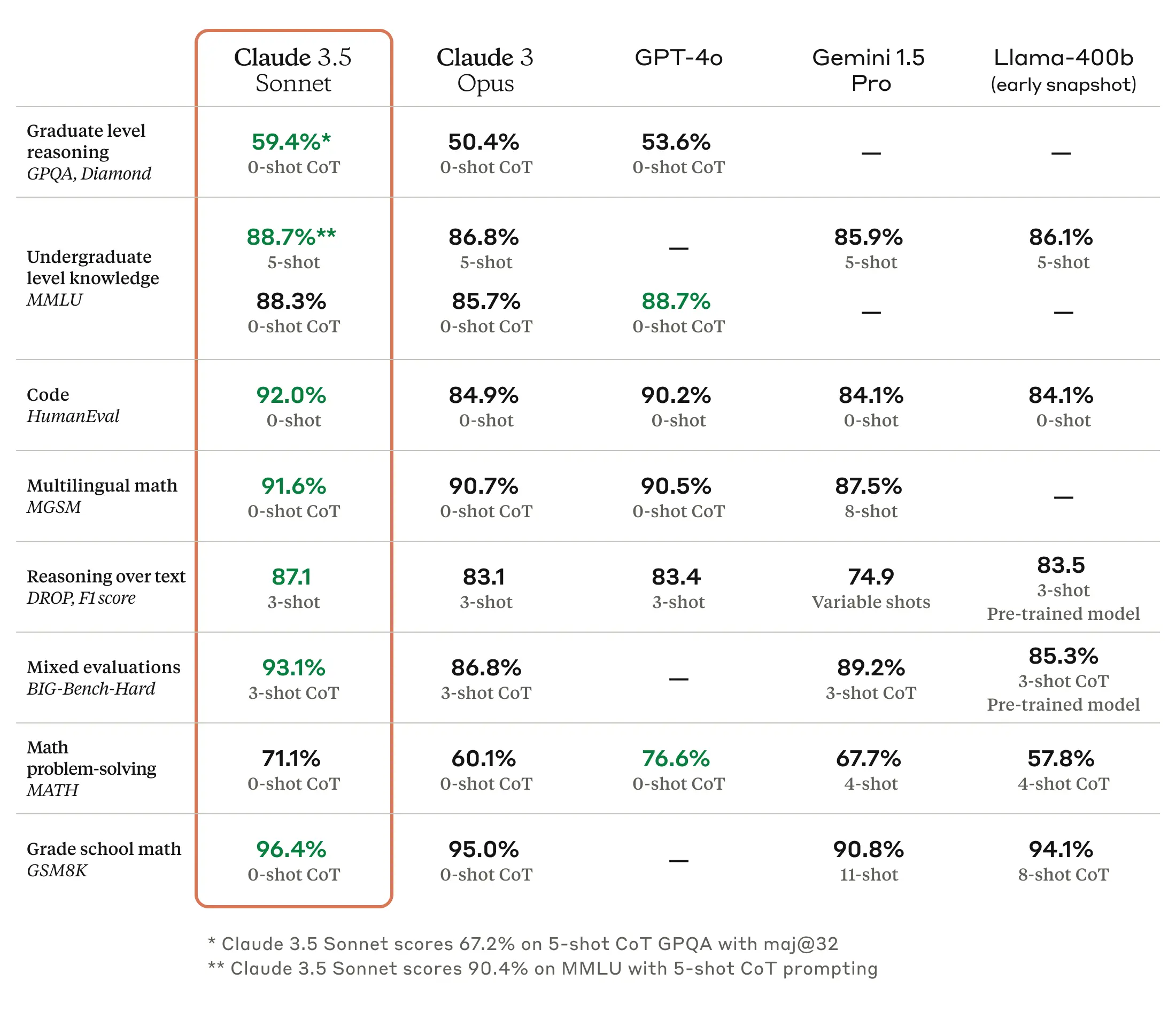
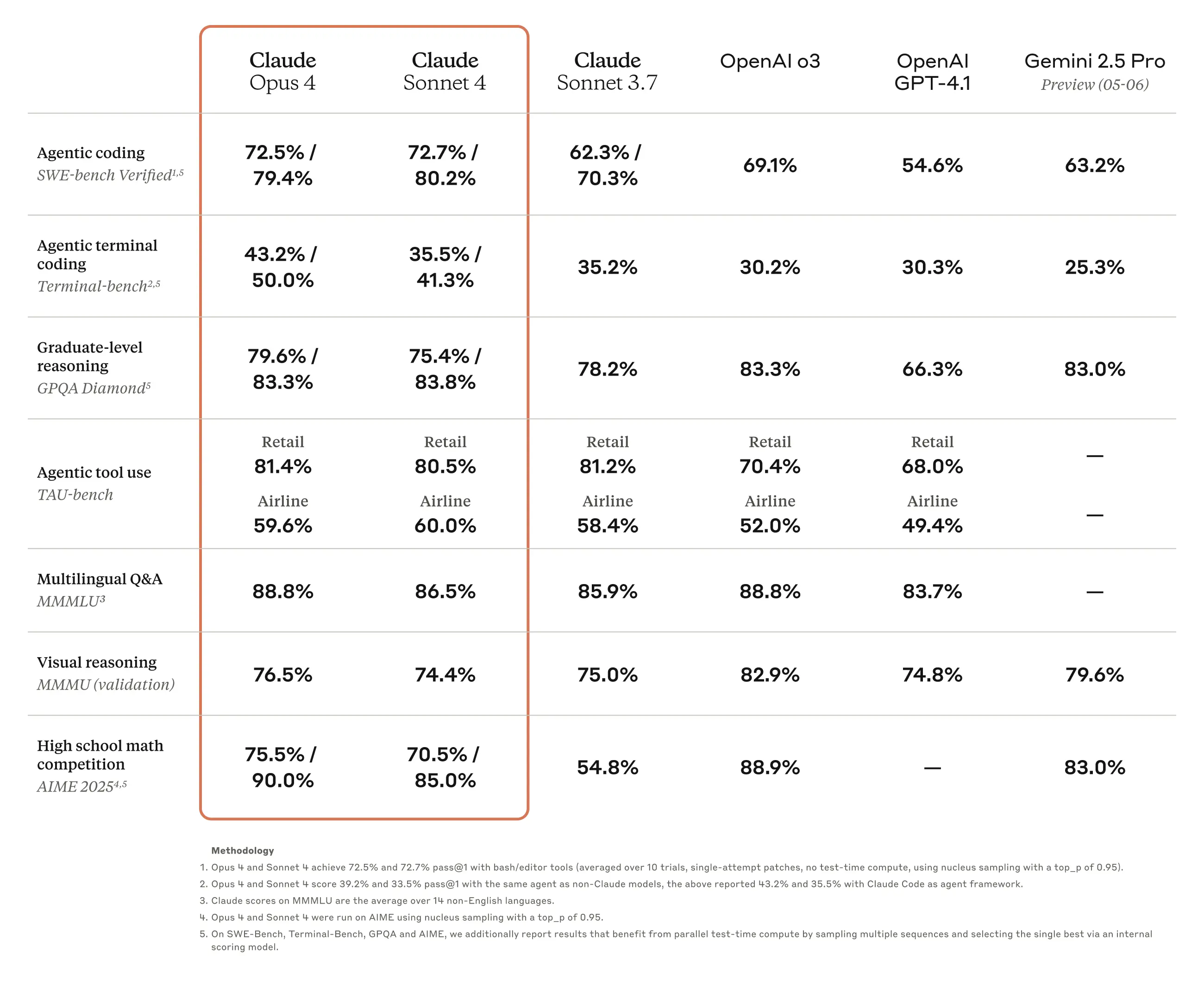
雖然根據使用條件可能會有差異,但自從 Claude 3.7 Sonnet 模型問世以來,普遍認為 Claude 在程式編寫方面是最強大的模型,這點幾乎沒有異議。Anthropic 也正積極地將優於 OpenAI 或 Google 等競爭模型的程式編寫性能,作為其模型的主要優勢來推廣。在這次 Claude Opus 4 和 Claude Sonnet 4 的發表會上,也可以看到他們持續強調程式編寫性能,將開發者視為主要客戶群的策略。
當然,從公開的基準測試結果來看,除了程式編寫之外,其他項目也都有全面的改善。對於本文所討論的翻譯工作而言,多語言問答(MMMLU)和數學解題(AIME 2025)領域的性能提升,預計將會發揮特別有效的作用。經過我自己的簡單測試,可以確認相較於前代模型 Claude 3.7 Sonnet,Claude Sonnet 4 的翻譯結果在表達的自然度、專業性以及術語使用的一致性等方面都更為出色。
在目前這個時間點,至少就本部落格所探討的這類具有技術性質的韓文文章進行多語言翻譯的工作上,我認為 Claude 模型仍然是最出色的。不過,最近 Google 的 Gemini 模型性能顯著提升,今年 5 月更推出了尚處於預覽階段的 Gemini 2.5 模型。 將 Gemini 2.0 Flash 模型與 Claude 3.7 Sonnet、Claude Sonnet 4 模型進行比較時,我判斷 Claude 的翻譯性能更優。但 Gemini 的多語言性能也相當優秀,而且儘管還在預覽階段,Gemini 2.5 Preview 05-06 在數學、物理問題的解題及論述能力上,甚至比 Claude Opus 4 更為出色,因此很難說當該模型正式發布後再做比較會是如何。 考量到在一定用量內可以透過免費方案(Free Tier) 使用,且付費方案(Paid Tier)的 API 費用也比 Claude 便宜,Gemini 的價格競爭力顯然更勝一籌。因此,只要能展現出相當的性能,Gemini 就可能成為一個合理的替代方案。由於 Gemini 2.5 仍處於預覽階段,我判斷現在將其應用於自動化還為時過早,所以暫不考慮,但計劃在未來正式版本發布後進行測試。
12025.07.04.
- 新增增量翻譯功能
- 根據目標翻譯語言,採用雙模型策略 (Commit 3890c82, Commit fe0fc63)
- 翻譯為英文、台灣中文、德文時,使用 “gemini-2.5-pro”
- 翻譯為日文、西班牙文、葡萄牙文、法文時,繼續使用既有的 “claude-sonnet-4-20250514”
- 曾考慮將
temperature值從0.0上調至0.2,但最終恢復原設定
12025 年 7 月 4 日,Gemini 2.5 Pro 及 Gemini 2.5 Flash 模型終於結束預覽階段,正式公開。雖然使用的例句數量有限,但根據我個人的測試,以英文翻譯為基準,光是 Gemini 2.5 Flash 在某些部分的處理就比既有的 Claude Sonnet 4 更為自然。考量到 Gemini 2.5 Pro 和 Flash 模型的輸出 token 費用,即使在付費方案下,也分別比 Claude Sonnet 4 便宜 1.5 倍和 6 倍,以英文翻譯來說,在 12025 年 7 月的當下,它可說是最具競爭力的模型。然而,Gemini 2.5 Flash 模型或許是小型模型的限制,雖然輸出結果大致上很出色,但存在一些 Markdown 文件格式或內部連結損壞等問題,因此不適合用於複雜的文件翻譯及加工工作。此外,雖然 Gemini 2.5 Pro 在英文方面表現確實優異,但在處理大部分的葡萄牙文(pt-BR)文章以及部分西班牙文文章時,似乎因為訓練資料量不足而顯得吃力。檢視發生的錯誤,大部分是混淆了 ‘í’ 和 ‘i’、’ó’ 和 ‘o’、’ç’ 和 ‘c’,以及 ‘ã’ 和 ‘a’ 等相似字母所導致的問題。另外,對於法文,雖然沒有上述問題,但句子有時過於冗長,可讀性不如 Claude Sonnet 4。
我對英文以外的語言不是很精通,所以難以進行詳細準確的比較,但各語言的回應品質大致如下:
- 英文、德文、台灣中文:Gemini 較優
- 日文、法文、西班牙文、葡萄牙文:Claude 較優
此外,我為文章翻譯腳本新增了增量翻譯(Incremental Translation)功能。雖然在初次撰寫文章時會努力仔細校對,但有時還是會在發表後才發現錯別字等小錯誤,或是想到可以補充/修改的內容。在這種情況下,儘管整篇文章中修改的篇幅有限,但既有的腳本卻需要從頭到尾重新翻譯並輸出整篇文章,從 API 使用量的角度來看,效率有些低落。為此,我新增了與 git 連動的功能,可以對韓文原文進行版本比較,將原文的變更部分以 diff 格式提取出來,連同變更前的完整譯文一起作為提示詞輸入,然後接收譯文的 diff 補丁作為輸出,從而只選擇性地修改必要的部分。由於輸入 token 的費用遠低於輸出 token,因此可以期待顯著的成本節省效果。未來即使只修改文章的一小部分,也可以 без負擔地使用自動翻譯腳本,而無需手動修改各語言的譯文。
另一方面,temperature 是一個參數,用來調整語言模型在輸出回應時,為每個詞選擇下一個詞時所賦予的隨機性程度。它是一個非負實數(*如下文所述,通常在 $[0,1]$ 或 $[0,2]$ 的範圍內),值越接近 0,生成的回答越具決定性且一致;值越大,生成的回答則越多樣化、更具創意。 翻譯的目的是將原文的意義和語氣盡可能準確且一致地傳達給另一種語言,而不是創造性地產生新內容。因此,為了確保翻譯的準確性、一致性和可預測性,應該使用較低的 temperature 值。不過,將 temperature 設為 0.0 會使模型總是選擇機率最高的詞,有時可能會導致翻譯過於直譯,或產生不自然、生硬的句子。為了防止回應過於僵化並賦予一定的靈活性,我曾考慮將 temperature 值微調至 0.2,但發現這會導致處理包含片段識別碼(Fragment identifier)的複雜連結時,準確度急遽下降,因此決定不予採用。
* 在大多數情況下,實用上
temperature的值域為 0 到 1 之間,Anthropic API 的允許範圍也是 $[0,1]$。雖然 OpenAI API 或 Gemini API 允許更寬的 $[0,2]$ 範圍,但temperature範圍擴展到 $[0,2]$ 並不意味著尺度也變為兩倍,$T=1$ 的意義與使用 $[0,1]$ 範圍的模型是相同的。語言模型在生成輸出時,內部運作上是將提示詞及先前已輸出的 token 作為輸入,並以一個機率分佈作為回應,輸出下一個 token 的機率。根據該機率分佈進行抽樣的結果,便決定了下一個輸出的 token。使用該機率分佈的基準值為 $T=1$。當 $T<1$ 時,機率分佈會變得更窄更尖銳,使模型更傾向於選擇機率最高的詞,從而產生更一致的選擇;反之,當 $T>1$ 時,則會將機率分佈平坦化,人為地提高那些原本出現機率較低、幾乎不會被選中的詞的選擇機率。
在 $T>1$ 的區域,回應中可能會包含脫離上下文的 token,或生成語法錯誤、不合邏輯的句子,導致輸出品質下降且難以預測。在大多數任務中,尤其是在生產環境中,最好將
temperature值設定在 $[0,1]$ 範圍內。大於 1 的值,可以在需要多樣化輸出,例如腦力激盪、創意輔助(如生成劇本草稿)等目的下實驗性地使用,但同時也會增加幻覺(hallucination)或語法、邏輯錯誤的風險,因此最好是在有人為介入和審核的前提下使用。關於語言模型的
temperature,更詳細的內容可以參考以下文章:
- Tamanna, Understanding LLM Temperature (2025).
- Tickr Data, The Impact of Temperature on LLM Performance (2023).
- Anik Das, Temperature in Prompt Engineering (2025).
- Peeperkorn et al., Is Temperature the Creativity Parameter of LLMs?, arXiv:2405.00492 (2024).
- Colt Steele, Understanding OpenAI’s Temperature Parameter (2023).
- Damon Garn, Understanding the role of temperature settings in AI output, TechTarget (2025).
提示詞設計
提出請求時的基本原則
為了從語言模型獲得符合目的且令人滿意的結果,必須提供適當的提示詞。雖然「提示詞設計」聽起來可能讓人感到茫然,但其實「如何有效地提出請求」這件事,無論對方是語言模型還是人類,都沒有太大差別。從這個角度切入,就不會覺得太困難了。遵循六何法 (5W1H),清晰地說明當前狀況及請求事項,必要時也可以附上一些具體的範例。關於提示詞設計的眾多技巧和方法,大多都是從下述的基本原則衍生而來的。
整體語氣
許多報告指出,使用禮貌請求的語氣撰寫並輸入提示詞,語言模型會輸出品質更高的回應。這就像在社會上向他人提出請求時,用禮貌的態度通常比用高壓的命令,更能讓對方有誠意地完成請託。語言模型似乎也學習並模仿了人類的這種回應模式。
賦予角色及說明情境(誰、為何)
首先,我賦予模型一個「技術領域的專業譯者(professional technical translator)」的角色,並提供了關於使用者的脈絡資訊,即「主要撰寫數學、物理學和資料科學相關文章的工程部落客」。
1
2
3
4
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics \
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
傳達大方向的請求事項(做什麼)
接著,我請求模型將使用者提供的 Markdown 格式文章,從 {source_lang} 翻譯成 {target_lang},並保持格式不變。
1
2
3
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> \
while preserving the format.</task>
呼叫 Claude API 時,提示詞中的 {source_lang} 和 {target_lang} 位置會透過 Python 腳本的 f-string 功能,分別代入來源語言和目標語言的變數。
具體化要求及範例(如何做)
如果是簡單的任務,到上一步可能就足以獲得想要的結果。但若要求的是複雜的任務,可能就需要額外的說明。
當要求條件複雜且多樣時,比起逐一描述,將各事項條列化更能提升可讀性,讓閱讀方(無論是人或語言模型)更容易理解。此外,必要時提供範例也會有所幫助。 在這種情況下,我增加了以下條件。
YAML front matter 的處理
為了上傳到 Jekyll 部落格,用 Markdown 撰寫的文章開頭會放置 YAML front matter,記錄 ‘title’、’description’、’categories’ 和 ‘tags’ 等資訊。例如,這篇文章的 YAML front matter 如下:
1
2
3
4
5
6
7
---
title: "如何使用 Claude Sonnet 4 API 自動翻譯文章 (1) - 提示詞設計"
description: "本篇文章將探討如何為 Markdown 文件的多語言翻譯設計提示詞,並使用 Anthropic/Gemini API 金鑰與設計好的提示詞,透過 Python 將翻譯工作自動化。本文為系列第一篇,將介紹提示詞設計的方法與過程。"
categories: [AI & Data, GenAI]
tags: [Jekyll, Markdown, LLM]
image: /assets/img/technology.webp
---
然而,在翻譯文章時,標題(title)和描述(description)標籤需要翻譯成多國語言,但為了保持文章 URL 的一致性,分類(categories)和標籤(tags)的名稱最好保留英文原文,這樣更便於維護。因此,我下了以下指令,要求模型不要翻譯 ‘title’ 和 ‘description’ 以外的標籤。由於模型應該已經學習並了解 YAML front matter 的相關資訊,這樣的說明在大多數情況下就足夠了。
1
2
- <condition>please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
加上 “under any circumstances, regardless of the language you are translating to” 這段話,是為了強調在任何情況下都不能隨意修改 YAML front matter 中的其他標籤。
(12025.04.02. 更新) 此外,我指示 description 標籤的內容要考慮到 SEO,撰寫適當的長度。
1
2
3
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
處理原文包含非來源語言的情況
在用韓文撰寫原文時,當初次介紹某個概念的定義或使用某些專業術語時,常常會像「중성자 감쇠 (Neutron Attenuation)」這樣,在括號中附上英文表達。在翻譯這類表達時,有時會保留括號,有時又會遺漏括號中的英文,導致翻譯方式不一致。為了解決這個問題,我訂定了以下細則:
- 專業術語的情況:
- 翻譯成日文等非羅馬字母系的語言時,維持「翻譯表達(英文表達)」的格式。
- 翻譯成西班牙文、葡萄牙文、法文等羅馬字母系的語言時,允許單獨使用「翻譯表達」或並用「翻譯表達(英文表達)」,由模型自行選擇更合適的方式。
- 專有名詞的情況,原文的拼寫必須以某種形式保留在翻譯結果中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language,
please maintain the <format>[target language expression(original English expression)]</format> in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses must be preserved in the translation output in some form.</else> \n\
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese as \
'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.\
In languages such as Spanish or Portuguese, they can be translated as 'Faraday', 'Maxwell', 'Einstein', in which case, \
redundant expressions such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' would be highly inappropriate.</example>\
</condition>\n\n
處理連至其他文章的連結
有些文章包含連至其他文章的連結。在測試階段,如果沒有特別指示,模型常會將 URL 的路徑部分也當作翻譯對象而修改,導致內部連結失效。這個問題透過在提示詞中加入以下這段話解決了。
1
2
3
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
(12025.04.06. 更新)
提供上述指令後,翻譯時能正確處理連結的路徑部分,連結失效的頻率確實降低了不少。但對於包含片段識別碼(Fragment identifier)的連結,由於模型不知道連結目標文章的內容,片段識別碼部分仍然只能靠模型推測填補,無法從根本上解決問題。為此,我改善了 Python 腳本和提示詞,將連結到的其他文章的脈絡資訊,放在使用者提示詞的 <reference_context> XML 標籤內一併提供,並指示模型根據該脈絡處理連結的翻譯。套用此更新後,大部分的連結失效問題都得以預防,對於緊密相連的系列文章,也能期待在多篇文章中提供更一致的翻譯效果。
在系統提示詞中,提出以下指令。
1
2
3
4
5
6
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
而使用者提示詞的 <reference_context> 部分,則由以下格式和內容構成,並附加在欲翻譯的本文內容之後。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<reference_context>
The following are contents of posts linked with hash fragments in the original post.
Use these for context when translating links and references:
<referenced_post path="{post_1_path}" hash="{hash_fragment_1}">
{post_content}
</referenced_post>
<referenced_post path="{post__2_path}" hash="{hash_fragment_2}">
{post_content}
</referenced_post>
...
</reference_context>
回應只輸出翻譯結果
最後,提出以下句子,要求回應時不要附加任何其他話語,只輸出翻譯結果。
1
2
3
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
其他的提示詞設計技巧
不過,與向人類請求工作不同,有些額外的技巧是專門適用於語言模型的。 關於這點,網路上有許多有用的資料,這裡整理幾個普遍有用的代表性技巧。 主要參考了 Anthropic 官方文件的提示詞工程指南。
運用 XML 標籤進行結構化
其實這點在前面已經一直在使用了。對於包含多種脈絡、指令、格式和範例的複雜提示詞,適當運用 <instructions>、<example>、<format> 等 XML 標籤,有助於語言模型準確解析提示詞,並產出符合意圖的高品質輸出。推薦參考 GENEXIS-AI/prompt-gallery GitHub 儲存庫,裡面整理了撰寫提示詞時有用的 XML 標籤。
逐步推理(CoT, Chain-of-Thought)技巧
對於需要相當程度推理的任務,如解數學題或撰寫複雜文件,引導語言模型分步驟思考,可以大幅提升其性能。但要注意,這種情況下回應延遲時間可能會變長,且並非所有任務都適用此技巧。
提示詞鏈(prompt chaining)技巧
當需要執行複雜任務時,單一提示詞可能難以應對。在這種情況下,可以考慮從一開始就將整個工作流程分成多個階段,為每個階段提供專門的提示詞,並將前一階段得到的應答作為下一階段的輸入。這種技巧稱為提示詞鏈(prompt chaining)。
預先填寫回應的開頭
在輸入提示詞時,預先給出回應內容的開頭,並讓模型接續撰寫後面的答案,可以跳過不必要的問候語等開場白,或強制模型以 XML、JSON 等特定格式回應。使用 Anthropic API 時,可以在呼叫時同時提交 User 訊息和 Assistant 訊息來使用此技巧。
防止AI偷懶(12024.10.31. 萬聖節更新)
這篇文章初次撰寫後,中間雖然經過一兩次小幅的提示詞改善和指令具體化,但總體來說,這套自動化系統運作了四個月,沒有出現什麼大問題。
然而,在韓國時間 12024.10.31. 傍晚 6 點左右開始,當我委託翻譯新寫的文章時,持續發生異常現象:模型只翻譯了文章開頭的「TL;DR」部分後,就任意中斷了翻譯。
關於該問題的可能原因及解決方法,我已在另一篇文章中進行了探討,請參考該文。
完成的系統提示詞
經過上述步驟設計出的提示詞成品,可以在下一篇中確認。
Further Reading
續見第 2 篇