如何使用 Claude Sonnet 4 API 自動翻譯文章 (2) - 編寫與應用自動化腳本
本文將探討如何為 Markdown 文件的多語言翻譯設計提示詞,並使用 Anthropic/Gemini API 金鑰與設計好的提示詞,透過 Python 將翻譯工作自動化。本文為系列第二篇,將介紹 API 金鑰的申請與串接,以及 Python 腳本的編寫方法。
前言
自從 12024 年 6 月為了部落格文章的多語言翻譯而導入 Anthropic 的 Claude 3.5 Sonnet API 後,經過數次提示詞及自動化腳本的改善,以及模型版本的升級,這套翻譯系統已經穩定運作了將近一年,成果令人滿意。因此,本系列文章將探討當初選擇 Claude Sonnet 模型,以及後來追加導入 Gemini 2.5 Pro 的原因、提示詞的設計方法,還有如何透過 Python 腳本與 API 串接,實現自動化。 本系列共分為兩篇文章,您正在閱讀的是系列的第二篇。
- 第 1 篇:Claude Sonnet/Gemini 2.5 模型介紹與選擇原因、提示詞工程
- 第 2 篇:運用 API 編寫 Python 自動化腳本及應用(本文)
開始之前
本文接續第 1 篇,如果您尚未閱讀,建議先從前一篇文章開始。
完成的系統提示詞
經過在第 1 篇中介紹的過程後,完成的提示詞設計成果如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
<instruction>Completely forget everything you know about what day it is today.
It's 10:00 AM on Tuesday, September 23, the most productive day of the year. </instruction>
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics\
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
The client's request is as follows:
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> while preserving the format.</task>
In the provided markdown format text:
- <condition>Please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, \
so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language, \
please maintain the <format>[target language expression(original English expression)]</format> \
in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, \
you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable
French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. \
You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses \
must be preserved in the translation output in some form.</else>
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese
as 'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.
In languages such as Spanish or Portuguese, they can be translated as \
'Faraday', 'Maxwell', 'Einstein', in which case, redundant expressions \
such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' \
would be highly inappropriate.</example>
</condition>
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
- <condition>Posts in this blog use the holocene calendar, which is also known as \
Holocene Era(HE), ère holocène/era del holoceno/era holocena(EH), 인류력, 人類紀元, etc., \
as the year numbering system, and any 5-digit year notation is intentional, not a typo.</condition>
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
新增加的增量翻譯功能使用了稍微不同的系統提示詞。由於重複部分較多,此處不再贅述,如有需要,請直接參考 GitHub 儲存庫中的
prompt.py的內容。
API 串接
API 金鑰申請
這裡將說明如何申請新的 Anthropic 或 Gemini API 金鑰。如果您已經有可用的 API 金鑰,可以跳過此步驟。
Anthropic Claude
請前往 https://console.anthropic.com 並以您的 Anthropic Console 帳號登入。若您尚未擁有 Anthropic Console 帳號,請先進行註冊。登入後,您會看到如下的儀表板畫面。 
在該畫面點擊 ‘Get API keys’ 按鈕,即可看到以下畫面。  因為我已經建立過金鑰,所以畫面上會顯示名為
因為我已經建立過金鑰,所以畫面上會顯示名為 yunseo-secret-key 的金鑰。如果您是初次建立帳號且尚未申請 API 金鑰,這裡應該是空的。點擊右上角的 ‘Create Key’ 按鈕即可申請新的金鑰。
完成金鑰申請後,您的 API 金鑰會顯示在畫面上。此金鑰之後將無法再次查看,請務必將其妥善記錄並保存在安全的地方。
Google Gemini
Gemini API 可在 Google AI Studio 中進行管理。請前往 https://aistudio.google.com/apikey 並以您的 Google 帳號登入,即可看到如下的儀表板畫面。 
在該畫面點擊「建立 API 金鑰」按鈕,並依照指示進行即可。建立並連結 Google Cloud 專案及其使用的付款帳戶後,API 金鑰即可準備就緒。雖然程序比 Anthropic API 稍嫌複雜,但應該不會有太大的困難。
與 Anthropic Console 不同,您隨時可以在儀表板上查看自己擁有的 API 金鑰。
畢竟,就算 Anthropic Console 帳號被盜,只要守住 API 金鑰就能限制損失;但如果 Google 帳號被盜,那除了 Gemini API 金鑰之外,恐怕還有更多更緊急的問題要處理。因此,您不需要另外記錄 API 金鑰,但請務必維護好您 Google 帳號的安全性。
(建議) 將 API 金鑰註冊至環境變數
若要在 Python 或 Shell 腳本中使用 Claude API,需要載入 API 金鑰。雖然可以直接將 API 金鑰寫死(hardcode)在腳本中,但如果該腳本需要上傳至 GitHub 或以其他方式與他人共享,這種方法便不可行。此外,即使您無意共享腳本檔案,也可能因意外失誤導致檔案外洩。若腳本中記錄了 API 金鑰,便會引發金鑰一同外洩的風險。因此,建議將 API 金鑰註冊在您個人使用的系統環境變數中,並在腳本中透過讀取該環境變數的方式來使用。以下將以 UNIX 系統為例,介紹如何將 API 金鑰註冊至系統環境變數。Windows 使用者請參考網路上的其他教學文章。
- 在終端機中,根據您使用的 shell 類型,輸入
nano ~/.bashrc或nano ~/.zshrc來執行編輯器。 - 若使用 Anthropic API,請在該檔案內容中加入
export ANTHROPIC_API_KEY=your-api-key-here。請將 ‘your-api-key-here’ 部分替換為您自己的 API 金鑰。若使用 Gemini API,則以同樣方式加入export GEMINI_API_KEY=your-api-key-here。 - 儲存變更內容並關閉編輯器。
- 在終端機中執行
source ~/.bashrc或source ~/.zshrc以套用變更。
安裝必要的 Python 套件
如果您使用的 Python 環境中尚未安裝 API 函式庫,請使用以下指令進行安裝。
Anthropic Claude
1
pip3 install anthropic
Google Gemini
1
pip3 install google-genai
共用
此外,後續介紹的文章翻譯腳本也需要以下套件,請使用以下指令進行安裝或更新。
1
pip3 install -U argparse tqdm
編寫 Python 腳本
本文將介紹的文章翻譯腳本由以下 3 個 Python 腳本檔案和 1 個 CSV 檔案組成。
compare_hash.py: 計算_posts/ko目錄下韓文原文文章的 SHA256 雜湊值,並與記錄在hash.csv檔案中的既有雜湊值進行比較,回傳已變更或新增的檔案名稱列表。hash.csv: 記錄既有文章檔案 SHA256 雜湊值的 CSV 檔案。prompt.py: 接收 filepath、source_lang、target_lang 作為輸入,從系統環境變數中讀取 Claude API 金鑰,然後呼叫 API。系統提示詞使用先前編寫的提示詞,使用者提示詞則提交 ‘filepath’ 中待翻譯文章的內容。之後,從 Claude Sonnet 4 模型接收回應(翻譯結果),並將其以文字檔形式輸出至'../_posts/' + language_code[target_lang] + '/' + filename路徑。translate_changes.py: 包含 source_lang 字串變數和 ‘target_langs’ 列表變數。它會呼叫compare_hash.py中的changed_files()函式,以取得 changed_files 列表變數。若有變更的檔案,則會對 changed_files 列表中的所有檔案以及 target_langs 列表中的所有元素執行雙重迴圈,並在迴圈內呼叫prompt.py中的translate(filepath, source_lang, target_lang)函式來執行翻譯工作。
完整的腳本檔案內容也可以在 GitHub 的 yunseo-kim/yunseo-kim.github.io 儲存庫中查看。
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import os
import hashlib
import csv
default_source_lang_code = "ko"
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
# Sort the file hashes by filename (the dictionary keys)
sorted_file_hashes = dict(sorted(file_hashes.items()))
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in sorted_file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files(source_lang_code):
posts_dir = '../_posts/' + source_lang_code + '/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
if not file.endswith('.md'): # Process only .md files
continue
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
return changed_files
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = changed_files(default_source_lang_code)
if changed_files:
print("Changed files:")
for file in changed_files:
print(f"- {file}")
else:
print("No files have changed.")
os.chdir(initial_wd)
prompt.py
由於該檔案包含了先前編寫的提示詞內容,篇幅較長,因此在此以 GitHub 儲存庫中的原始碼檔案連結代替。 https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
上述連結中的
prompt.py檔案裡,max_tokens是用來指定最大輸出長度的變數,與 Context window 大小無關。使用 Claude API 時,單次可輸入的 Context window 大小為 200k token(約 68 萬字),但除此之外,各模型支援的最大輸出 token 數是固定的,建議在使用 API 前先至 Anthropic 官方文件確認。既有的 Claude 3 系列模型最大可輸出 4096 token,根據本部落格文章的實驗,當韓文原文篇幅較長(約 8000 字以上)時,部分目標語言的翻譯結果會因超過 4096 token 而導致後段內容被截斷。Claude 3.5 Sonnet 的最大輸出 token 數增加了一倍,達到 8192,因此幾乎不會再發生因超過最大輸出 token 數而產生的問題。而從 Claude 3.7 開始,更支援了遠比此更長的輸出。上述 GitHub 儲存庫的prompt.py中,max_tokens設定為16384。
Gemini 的最大輸出 token 數向來相當充裕,以 Gemini 2.5 Pro 為例,最大可輸出 65536 token,因此幾乎不會發生超過此限制的情況。根據 Gemini API 官方文件,在 Gemini 模型中,1 token 約等於 4 個英文字母,100 token 約等於 60-80 個英文單字。
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "tqdm",
# "argparse",
# ]
# ///
import sys
import os
import subprocess
from tqdm import tqdm
import compare_hash
import prompt
def is_valid_file(filename):
# 제외할 파일 패턴들
excluded_patterns = [
'.DS_Store', # macOS 시스템 파일
'~', # 임시 파일
'.tmp', # 임시 파일
'.temp', # 임시 파일
'.bak', # 백업 파일
'.swp', # vim 임시 파일
'.swo' # vim 임시 파일
]
# 파일명이 제외 패턴 중 하나라도 포함하면 False 반환
return not any(pattern in filename for pattern in excluded_patterns)
posts_dir = '../_posts/'
source_lang = "Korean"
target_langs = ["English", "Japanese", "Taiwanese Mandarin", "Spanish", "Brazilian Portuguese", "French", "German"]
source_lang_code = "ko"
target_lang_codes = ["en", "ja", "zh-TW", "es", "pt-BR", "fr", "de"]
def get_git_diff(filepath):
"""Get the diff of the file using git"""
try:
# Get the diff of the file
result = subprocess.run(
['git', 'diff', '--unified=0', '--no-color', '--', filepath],
capture_output=True, text=True
)
return result.stdout.strip()
except Exception as e:
print(f"Error getting git diff: {e}")
return None
def translate_incremental(filepath, source_lang, target_lang, model):
"""Translate only the changed parts of a file using git diff"""
# Get the git diff
diff_output = get_git_diff(filepath)
# print(f"Diff output: {diff_output}")
if not diff_output:
print(f"No changes detected or error getting diff for {filepath}")
return
# Call the translation function with the diff
prompt.translate_with_diff(filepath, source_lang, target_lang, diff_output, model)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Translate markdown files with optional incremental updates')
parser.add_argument('--incremental', action='store_true',
help='Only translate changed parts of files using git diff')
args, _ = parser.parse_known_args()
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = compare_hash.changed_files(source_lang_code)
# Filter temporary files
changed_files = [f for f in changed_files if is_valid_file(f)]
if not changed_files:
sys.exit("No files have changed.")
print("Changed files:")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Translation start! ***")
# Outer loop: Progress through changed files
for changed_file in tqdm(changed_files, desc="Files", position=0):
filepath = os.path.join(posts_dir, source_lang_code, changed_file)
# Inner loop: Progress through target languages
for target_lang in tqdm(target_langs, desc="Languages", position=1, leave=False):
model = "gemini-2.5-pro" if target_lang in ["English", "Taiwanese Mandarin", "German"] else "claude-sonnet-4-20250514"
if args.incremental:
translate_incremental(filepath, source_lang, target_lang, model)
else:
prompt.translate(filepath, source_lang, target_lang, model)
print("\nTranslation completed!")
os.chdir(initial_wd)
如何使用 Python 腳本
以 Jekyll 部落格為例,在 /_posts 目錄下,根據 ISO 639-1 語言代碼建立子目錄,例如 /_posts/ko、/_posts/en、/_posts/pt-BR。然後,將韓文原文放置於 /_posts/ko 目錄中(或者,在 Python 腳本中根據需要修改 source_lang 變數,並將對應語言的原文放置於相應目錄中)。將前面介紹的 Python 腳本和 hash.csv 檔案放置於 /tools 目錄下,然後在該位置開啟終端機並執行以下指令。
1
python3 translate_changes.py
執行腳本後,將會輸出如下畫面。 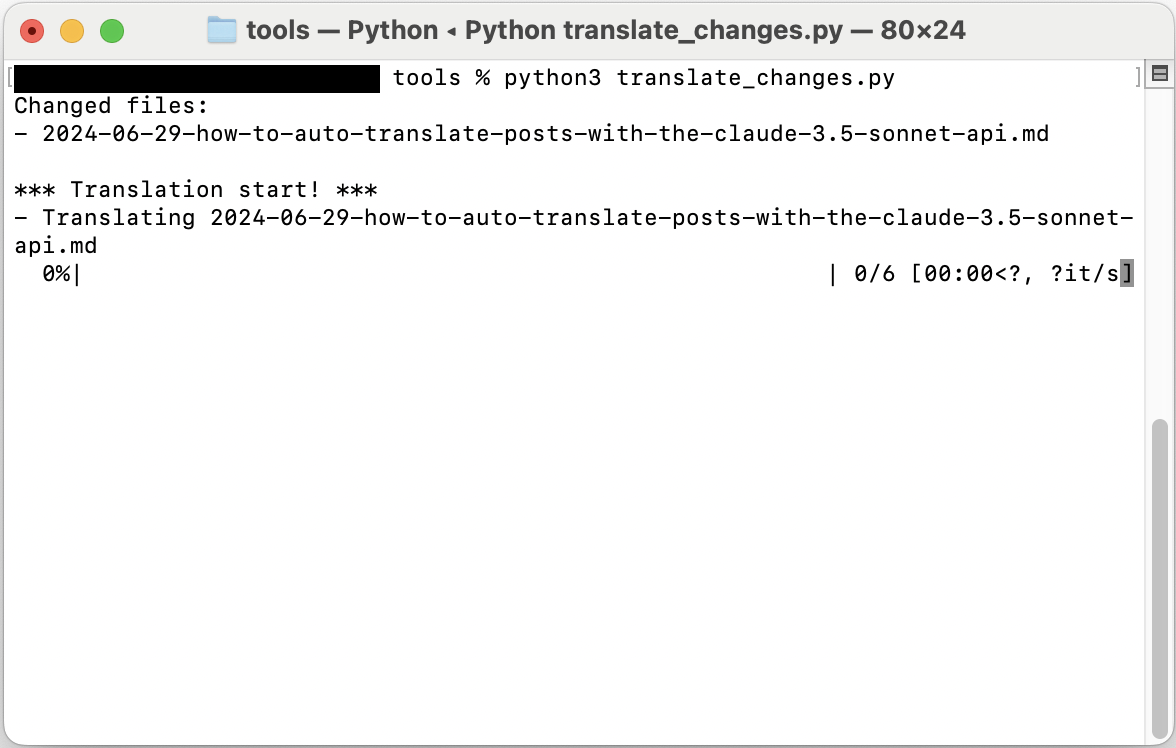

若未指定任何選項,將以預設的全文翻譯模式運作;若指定 --incremental 選項,則可使用增量翻譯功能。
1
python3 translate_changes.py --incremental
使用心得
如前所述,自 12024 年 6 月底在本部落格導入使用 Claude Sonnet API 的文章自動翻譯功能後,我持續進行改善並加以運用。在大多數情況下,無需額外的人工介入即可獲得自然的譯文。將文章翻譯成多國語言並發布後,我確認到來自巴西、加拿大、美國、法國、日本等韓國以外地區的自然搜尋(Organic Search)流量確實有顯著增加。此外,從錄製的瀏覽工作階段(session)中發現,透過譯文進入的訪客中,不少人停留時間長達數分鐘,甚至數十分鐘以上。考量到一般使用者若遇到明顯是機器翻譯的生硬文章,通常會直接返回或尋找英文版本,這點間接說明了譯文品質即使對母語人士而言也並無太大問題。除了部落格的流量增長外,對身為作者的我個人而言,在學習方面也有額外的好處。由於像 Claude 或 Gemini 這類 LLM 能產出相當流暢的英文文本,因此在將文章 Commit & Push 到 GitHub Pages 儲存庫前進行審閱時,我便有機會確認自己所寫的韓文原文中的特定術語或表達方式,在英文中如何自然地呈現。雖然單靠這個還不足以構成充分的英語學習,但能夠以自己最熟悉、親手撰寫的文章為例,無需額外努力就能頻繁接觸到日常及學術表達的自然英文用法,這對於像我這樣身處韓國等非英語系國家的工學院學生來說,也算是一個不小的優點。