Wie man Beiträge mit der Claude Sonnet 4 API automatisch übersetzt (1) – Prompt-Design
Ein Leitfaden zum Entwerfen von Prompts für die mehrsprachige Übersetzung von Markdown-Dateien und zur Automatisierung des Prozesses mit Python unter Verwendung von Anthropic/Gemini-API-Schlüsseln. Dieser erste Teil der Serie stellt die Methode und den Prozess des Prompt-Designs vor.
Einführung
Seit der Einführung der Claude 3.5 Sonnet API von Anthropic im Juni 12024 für die mehrsprachige Übersetzung von Blogbeiträgen habe ich das Übersetzungssystem nach mehreren Verbesserungen der Prompts und Automatisierungsskripte sowie nach Modell-Upgrades fast ein Jahr lang zufriedenstellend betrieben. In dieser Serie möchte ich die Gründe für die Wahl des Claude-Sonnet-Modells und die spätere zusätzliche Einführung von Gemini 2.5 Pro, die Methode des Prompt-Designs und die Implementierung der API-Anbindung und Automatisierung mittels eines Python-Skripts erläutern. Die Serie besteht aus zwei Beiträgen, und dieser, den Sie gerade lesen, ist der erste Teil der Serie.
- Teil 1: Vorstellung und Auswahlgründe für die Modelle Claude Sonnet/Gemini 2.5, Prompt-Engineering (Dieser Beitrag)
- Teil 2: Erstellung und Anwendung eines Python-Automatisierungsskripts mithilfe der API
Über Claude Sonnet
Die Claude-Modellreihe wird je nach Modellgröße in den Versionen Haiku, Sonnet und Opus angeboten. 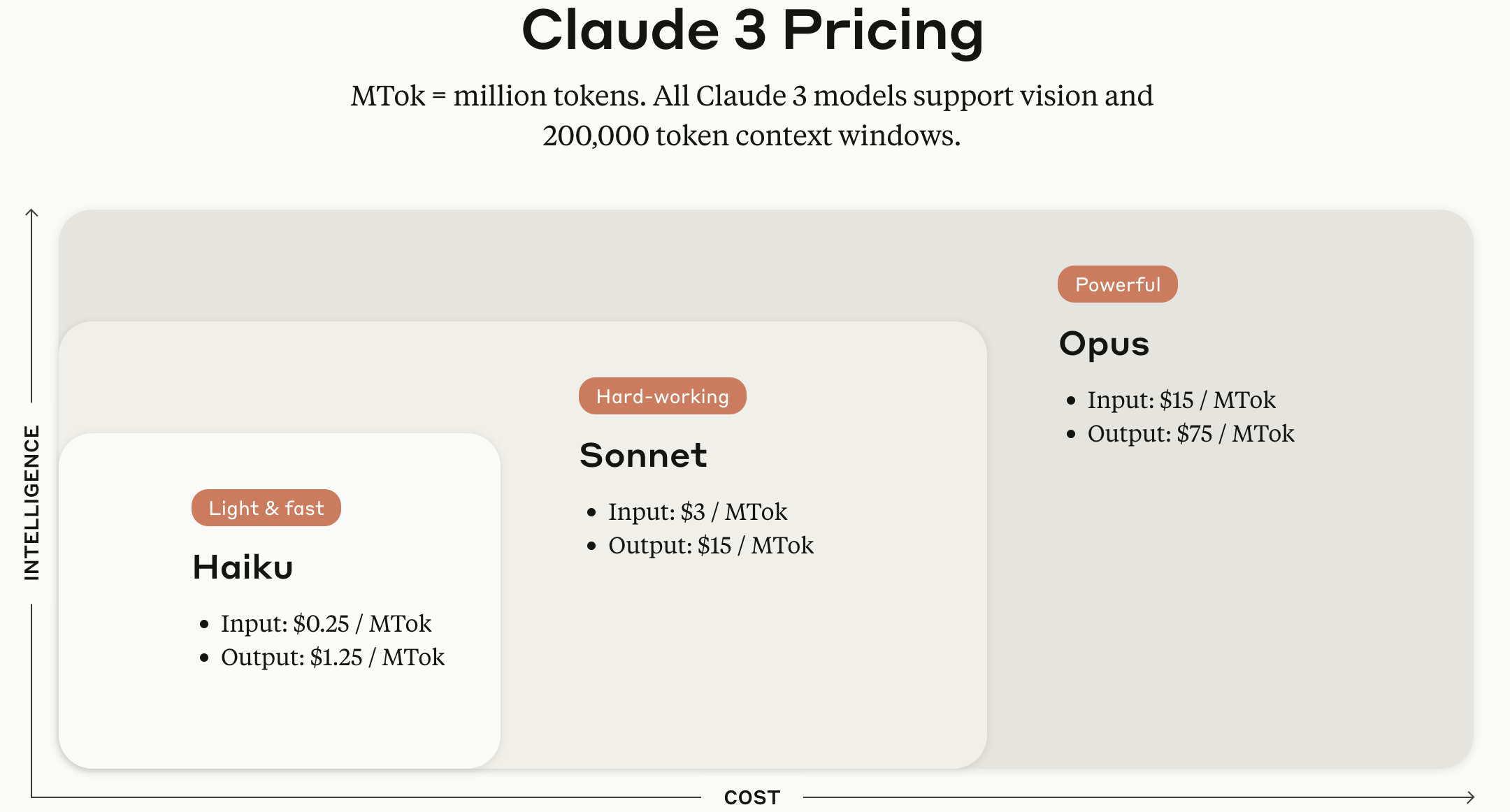
Bildquelle: Offizielle Webseite der Anthropic Claude API
(Hinzugefügt am 29.05.12025) Da das Bild vor einem Jahr aufgenommen wurde, sind die Kosten pro Token nach dem alten Claude-3-Standard angegeben, aber die Einteilung nach Modellgröße in Haiku, Sonnet und Opus ist weiterhin gültig. Stand Ende Mai 12025 lautet die Preisgestaltung von Anthropic für die jeweiligen Modelle wie folgt.
Modell Basis-Input-
Tokens5m Cache-
Schreibvorgänge1h Cache-
SchreibvorgängeCache-Treffer &
AktualisierungenAusgabe-
TokensClaude Opus 4 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Sonnet 4 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.7 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.5 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Haiku 3.5 $0.80 / MTok $1 / MTok $1.6 / MTok $0.08 / MTok $4 / MTok Claude Opus 3 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Haiku 3 $0.25 / MTok $0.30 / MTok $0.50 / MTok $0.03 / MTok $1.25 / MTok
Und das am 21. Juni 12024 nach koreanischer Zeit von Anthropic veröffentlichte Sprachmodell Claude 3.5 Sonnet (nach dem Holozän-Kalender) zeigt bei gleichen Kosten und gleicher Geschwindigkeit wie das bisherige Claude 3 Sonnet eine überlegene Schlussfolgerungsleistung gegenüber Claude 3 Opus. Es herrscht die allgemeine Meinung, dass es im Vergleich zum Konkurrenzmodell GPT-4 insbesondere in den Bereichen Texterstellung, sprachliches Schlussfolgern sowie mehrsprachiges Verständnis und Übersetzung Stärken aufweist. 
Bildquelle: Anthropic Newsroom
Gründe für die Einführung von Claude 3.5 für die Beitragsübersetzung
Auch ohne Sprachmodelle wie Claude 3.5 oder GPT-4 gibt es bereits kommerzielle Übersetzungs-APIs wie Google Übersetzer oder DeepL. Der Grund, warum ich mich dennoch für die Verwendung eines LLM für Übersetzungszwecke entschieden habe, liegt darin, dass der Benutzer im Gegensatz zu anderen kommerziellen Übersetzungsdiensten dem Modell durch Prompt-Design zusätzliche kontextbezogene Informationen oder Anforderungen über den eigentlichen Text hinaus, wie z. B. den Zweck des Schreibens oder die Hauptthemen, zur Verfügung stellen kann, und das Modell darauf basierend eine kontextbezogene Übersetzung liefern kann.
Obwohl DeepL oder Google Übersetzer im Allgemeinen eine hervorragende Übersetzungsqualität aufweisen, haben sie die Einschränkung, dass sie das Thema oder den Gesamtkontext eines Textes nicht gut erfassen und keine komplexen Anforderungen separat übermittelt werden können. Daher sind die Übersetzungsergebnisse bei der Anforderung, lange Texte zu professionellen Themen anstelle von alltäglichen Gesprächen zu übersetzen, tendenziell unnatürlicher, und es ist schwierig, die Ausgabe genau in einem bestimmten erforderlichen Format (Markdown, YAML-Frontmatter usw.) zu erhalten.
Insbesondere Claude wurde, wie oben erwähnt, im Vergleich zum Konkurrenzmodell GPT-4 in den Bereichen Texterstellung, sprachliches Schlussfolgern, mehrsprachiges Verständnis und Übersetzung als relativ überlegen bewertet. Auch bei meinen eigenen einfachen Tests zeigte es eine flüssigere Übersetzungsqualität als GPT-4. Daher hielt ich es zum Zeitpunkt der Einführung im Juni 12024 für geeignet, die in diesem Blog veröffentlichten ingenieurwissenschaftlichen Artikel in mehrere Sprachen zu übersetzen.
Update-Verlauf
01.07.12024
Wie in einem separaten Beitrag beschrieben, wurden die anfänglichen Arbeiten zur Anwendung des Polyglot-Plugins und zur entsprechenden Anpassung von _config.yml, HTML-Headern und der Sitemap abgeschlossen. Anschließend wurde nach der Auswahl des Claude 3.5 Sonnet-Modells für Übersetzungszwecke und dem Abschluss der anfänglichen Implementierung und Überprüfung des in dieser Serie behandelten Python-Skripts zur API-Anbindung dieses angewendet.
31.10.12024
Am 22. Oktober 12024 kündigte Anthropic eine aktualisierte Version der Claude 3.5 Sonnet API (“claude-3-5-sonnet-20241022”) und Claude 3.5 Haiku an. Aufgrund des weiter unten beschriebenen Problems wird in diesem Blog jedoch vorerst weiterhin die bisherige “claude-3-5-sonnet-20240620” API verwendet.
02.04.12025
29.05.12025
Bildquelle: Anthropic Newsroom
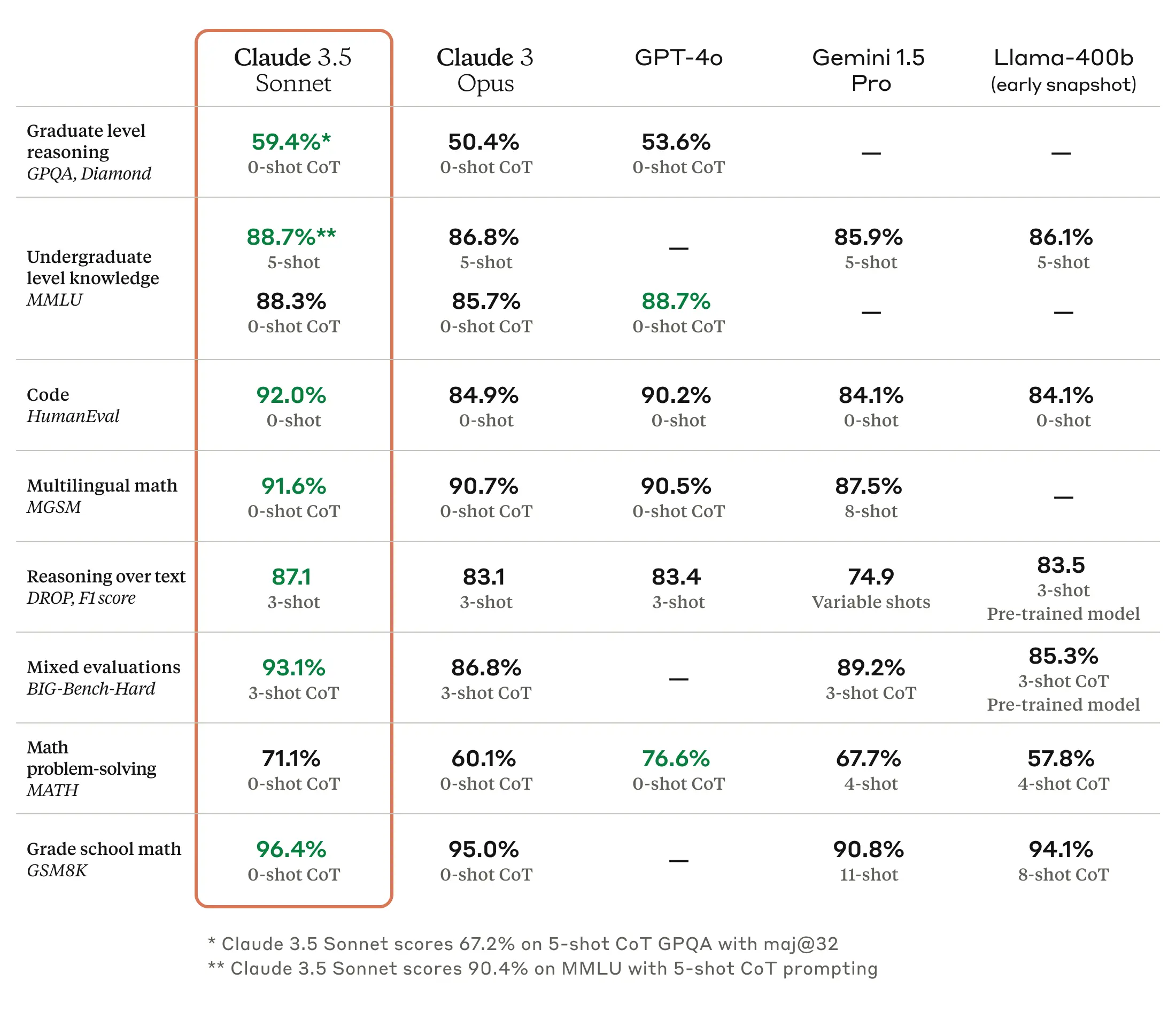
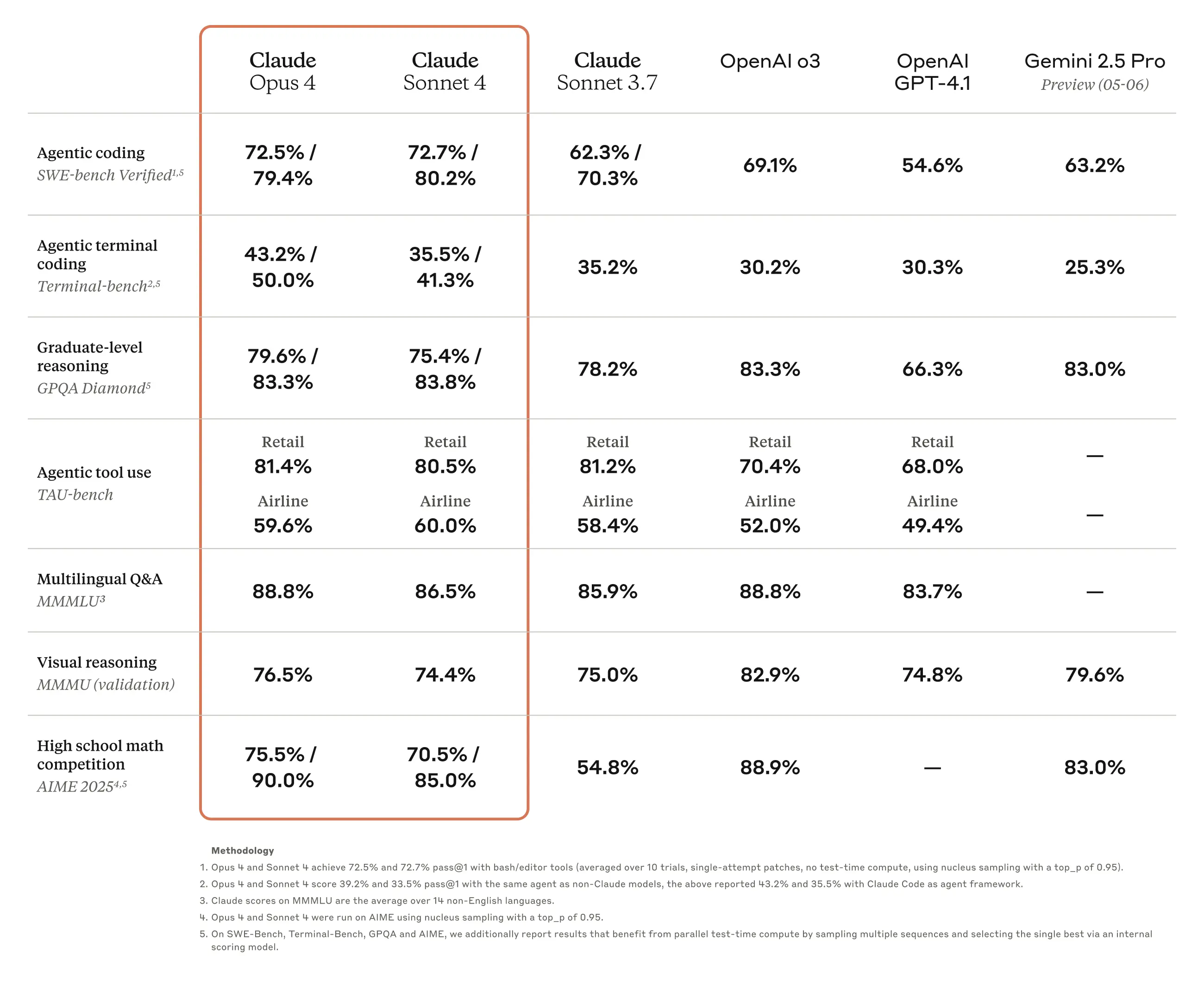
Obwohl es je nach Anwendungsbedingungen Unterschiede geben kann, herrscht seit der Veröffentlichung des Claude 3.7 Sonnet-Modells weitgehend Einigkeit darüber, dass Claude das leistungsstärkste Modell für das Programmieren ist. Anthropic bewirbt die überlegene Programmierleistung seiner Modelle im Vergleich zu Konkurrenzmodellen wie OpenAI oder Google aktiv als eine der Hauptstärken. Auch bei der Ankündigung von Claude Opus 4 und Claude Sonnet 4 wird die Programmierleistung betont, was die fortgesetzte Ausrichtung auf Entwickler als Hauptzielgruppe bestätigt.
Natürlich zeigen die veröffentlichten Benchmark-Ergebnisse, dass auch in anderen Bereichen als dem Programmieren allgemeine Verbesserungen erzielt wurden. Bei der in diesem Beitrag behandelten Übersetzungsarbeit dürften insbesondere die Leistungssteigerungen in den Bereichen mehrsprachige Frage-Antwort-Aufgaben (MMMLU) und mathematische Problemlösungen (AIME 2025) von Bedeutung sein. Eigene kurze Tests haben gezeigt, dass die Übersetzungsergebnisse von Claude Sonnet 4 im Vergleich zum Vorgängermodell Claude 3.7 Sonnet in Bezug auf die Natürlichkeit des Ausdrucks, die Professionalität und die Konsistenz der Terminologie überlegen sind.
Zum jetzigen Zeitpunkt bin ich der Meinung, dass das Claude-Modell für die Übersetzung von technisch geprägten, auf Koreanisch verfassten Texten in andere Sprachen, wie sie in diesem Blog behandelt werden, nach wie vor am besten geeignet ist. Allerdings hat sich die Leistung des Gemini-Modells von Google in letzter Zeit merklich verbessert, und seit Mai dieses Jahres wurde sogar das Gemini 2.5-Modell veröffentlicht, wenn auch noch in der Preview-Phase. Beim Vergleich des Gemini 2.0 Flash-Modells mit Claude 3.7 Sonnet und Claude Sonnet 4 habe ich festgestellt, dass die Übersetzungsleistung von Claude überlegen ist. Die mehrsprachige Leistung von Gemini ist jedoch ebenfalls recht beeindruckend, und obwohl es sich noch in der Preview-Phase befindet, sind die Fähigkeiten von Gemini 2.5 Preview 05-06 beim Lösen und Beschreiben von mathematischen und physikalischen Problemen sogar besser als die von Claude Opus 4. Es ist also ungewiss, wie der Vergleich ausfallen wird, wenn das Modell offiziell veröffentlicht wird. Da die Nutzung bis zu einem gewissen Grad über die kostenlose Stufe (Free Tier) möglich ist und die API-Gebühren selbst in der kostenpflichtigen Stufe (Paid Tier) im Vergleich zu Claude günstiger sind, ist die Preiswettbewerbsfähigkeit von Gemini überragend. Daher könnte Gemini eine vernünftige Alternative sein, solange eine einigermaßen vergleichbare Leistung erzielt wird. Da sich Gemini 2.5 noch in der Preview-Phase befindet, halte ich es für verfrüht, es in die eigentliche Automatisierung zu integrieren, aber ich plane, es zu testen, sobald die offizielle Version veröffentlicht wird.
04.07.12025
- Inkrementelle Übersetzungsfunktion hinzugefügt
- Zweiteilung der angewendeten Modelle je nach Zielsprache der Übersetzung (Commit 3890c82, Commit fe0fc63)
- Bei Übersetzungen ins Englische, traditionelle Chinesisch (Taiwan) und Deutsche wird “gemini-2.5-pro” verwendet.
- Bei Übersetzungen ins Japanische, Spanische, Portugiesische und Französische wird weiterhin das bisherige “claude-sonnet-4-20250514” verwendet.
- Die Anhebung des
temperature-Wertes von0.0auf0.2wurde erwogen, aber wieder auf den ursprünglichen Wert zurückgesetzt.
Am 4. Juli 12025 wurden die Modelle Gemini 2.5 Pro und Gemini 2.5 Flash endlich aus der Preview-Phase entlassen und offiziell veröffentlicht. Obwohl die Anzahl der verwendeten Beispiele begrenzt ist, haben persönliche Tests ergeben, dass bei englischen Übersetzungen bereits Gemini 2.5 Flash teilweise natürlichere Ergebnisse liefert als das bisherige Claude Sonnet 4. Berücksichtigt man, dass die Kosten pro Ausgabe-Token für die Modelle Gemini 2.5 Pro und Flash selbst in der kostenpflichtigen Stufe 1,5- bzw. 6-mal günstiger sind als für Claude Sonnet 4, kann man sagen, dass es für englische Übersetzungen Stand Juli 12025 das wettbewerbsfähigste Modell ist. Allerdings zeigte das Gemini 2.5 Flash-Modell, möglicherweise aufgrund der Einschränkungen eines kleineren Modells, trotz allgemein hervorragender Ergebnisse Probleme wie das Brechen einiger Markdown-Dokumentformate oder interner Links, was es für komplexe Dokumentenübersetzungs- und -verarbeitungsaufgaben ungeeignet machte. Während Gemini 2.5 Pro für Englisch eine deutlich überlegene Leistung zeigte, hatte es Schwierigkeiten bei der Verarbeitung der meisten portugiesischen (pt-BR) Beiträge und einiger spanischer Beiträge, möglicherweise aufgrund einer unzureichenden Menge an Trainingsdaten. Die aufgetretenen Fehler waren meist auf die Verwechslung ähnlicher Zeichen wie ‘í’ und ‘i’, ‘ó’ und ‘o’, ‘ç’ und ‘c’ sowie ‘ã’ und ‘a’ zurückzuführen. Bei Französisch gab es zwar keine derartigen Probleme, aber die Sätze waren oft übermäßig langatmig, was die Lesbarkeit im Vergleich zu Claude Sonnet 4 beeinträchtigte.
Da ich außer Englisch keine anderen Sprachen gut beherrsche, ist ein detaillierter und genauer Vergleich schwierig, aber ein grober Vergleich der Antwortqualität pro Sprache sieht wie folgt aus:
- Englisch, Deutsch, traditionelles Chinesisch (Taiwan): Gemini ist überlegen
- Japanisch, Französisch, Spanisch, Portugiesisch: Claude ist überlegen
Zudem wurde dem Skript für die Beitragsübersetzung eine Funktion zur inkrementellen Übersetzung (Incremental Translation) hinzugefügt. Obwohl ich mich bemühe, beim ersten Schreiben eines Beitrags alles sorgfältig zu überprüfen, entdecke ich dennoch manchmal nachträglich Tippfehler oder andere kleine Fehler, oder mir fallen Inhalte ein, die hinzugefügt oder geändert werden sollten. In solchen Fällen war das bisherige Skript in Bezug auf die API-Nutzung etwas ineffizient, da es den gesamten Beitrag von Anfang bis Ende neu übersetzen und ausgeben musste, obwohl nur ein begrenzter Teil des Textes geändert wurde. Daher wurde eine Funktion hinzugefügt, die in Verbindung mit Git einen Versionsvergleich des koreanischen Originaltextes durchführt, die geänderten Teile des Originals im Diff-Format extrahiert und diese zusammen mit dem vollständigen, unveränderten übersetzten Text als Prompt eingibt, um einen Diff-Patch für den übersetzten Text als Ausgabe zu erhalten und nur die erforderlichen Teile selektiv zu ändern. Da die Kosten pro Eingabe-Token deutlich geringer sind als die pro Ausgabe-Token, ist eine signifikante Kosteneinsparung zu erwarten. Daher kann ich in Zukunft auch bei geringfügigen Änderungen am Text das automatische Übersetzungsskript bedenkenlos anwenden, ohne die Übersetzungen für jede Sprache manuell bearbeiten zu müssen.
Der Parameter temperature steuert den Grad der Zufälligkeit, mit dem ein Sprachmodell bei der Ausgabe einer Antwort für jedes Wort das nächste Wort auswählt. Er nimmt einen nicht-negativen reellen Wert an (normalerweise im Bereich von $[0,1]$ oder $[0,2]$, wie weiter unten erläutert). Ein kleiner Wert nahe 0 erzeugt deterministischere und konsistentere Antworten, während ein größerer Wert vielfältigere und kreativere Antworten erzeugt. Der Zweck einer Übersetzung ist es, die Bedeutung und den Ton des Originaltextes so genau und konsistent wie möglich in eine andere Sprache zu übertragen, nicht kreativ neue Inhalte zu erfinden. Daher sollte ein niedriger temperature-Wert verwendet werden, um die Genauigkeit, Konsistenz und Vorhersehbarkeit der Übersetzung zu gewährleisten. Allerdings kann die Einstellung von temperature auf 0.0 dazu führen, dass das Modell immer nur das wahrscheinlichste Wort wählt, was die Übersetzung manchmal zu wörtlich oder die Sätze unnatürlich und steif machen kann. Um eine übermäßige Starrheit der Antwort zu vermeiden und eine gewisse Flexibilität zu ermöglichen, wurde eine leichte Anhebung des temperature-Wertes auf 0.2 erwogen. Dies wurde jedoch nicht umgesetzt, da die Genauigkeit bei der Verarbeitung komplexer Links, die einen Fragmentbezeichner (Fragment identifier) enthalten, stark abnahm.
* In den meisten praktischen Fällen liegt der
temperature-Wert im Bereich von 0 bis 1, und auch der zulässige Bereich in der Anthropic-API ist $[0,1]$. Die OpenAI-API oder die Gemini-API erlauben einen breiterentemperature-Wert von $[0,2]$, aber die Erweiterung des Bereichs auf $[0,2]$ bedeutet nicht, dass die Skala verdoppelt wird; die Bedeutung von $T=1$ ist die gleiche wie bei Modellen, die den Bereich $[0,1]$ verwenden.Intern funktioniert ein Sprachmodell bei der Erzeugung einer Ausgabe wie eine Art Funktion, die den Prompt und die bisherigen Ausgabe-Token als Eingabe nimmt und eine Wahrscheinlichkeitsverteilung für das nächste Token als Antwort ausgibt. Das Ergebnis einer Stichprobe gemäß dieser Wahrscheinlichkeitsverteilung wird als nächstes Token festgelegt und ausgegeben. Der Referenzwert, bei dem diese Wahrscheinlichkeitsverteilung unverändert verwendet wird, ist $T=1$. Bei $T<1$ wird die Wahrscheinlichkeitsverteilung schmaler und spitzer gemacht, sodass eine konsistentere Auswahl hauptsächlich aus den wahrscheinlichsten Wörtern getroffen wird. Bei $T>1$ wird die Wahrscheinlichkeitsverteilung hingegen abgeflacht, um die Auswahlwahrscheinlichkeit von Wörtern künstlich zu erhöhen, die eine geringe Wahrscheinlichkeit haben und normalerweise kaum ausgewählt würden.
Im Bereich $T>1$ kann die Ausgabequalität sinken und unvorhersehbar werden, da die Antwort kontextfremde Token enthalten oder grammatikalisch falsche, unsinnige Sätze erzeugen kann. Für die meisten Aufgaben, insbesondere in Produktionsumgebungen, ist es ratsam, den
temperature-Wert im Bereich $[0,1]$ festzulegen. Werte über 1 können experimentell für Zwecke wie Brainstorming oder kreative Unterstützung (z. B. Erstellung von Szenarioentwürfen) verwendet werden, wenn eine vielfältige Ausgabe gewünscht wird. Da jedoch das Risiko von Halluzinationen (Hallucination) sowie grammatikalischen und logischen Fehlern steigt, sollte dies eher unter der Voraussetzung menschlicher Eingriffe und Überprüfungen als in der Automatisierung erfolgen.Für weitere Details zur
temperaturevon Sprachmodellen sind die folgenden Artikel empfehlenswert.
- Tamanna, Understanding LLM Temperature (2025).
- Tickr Data, The Impact of Temperature on LLM Performance (2023).
- Anik Das, Temperature in Prompt Engineering (2025).
- Peeperkorn et al., Is Temperature the Creativity Parameter of LLMs?, arXiv:2405.00492 (2024).
- Colt Steele, Understanding OpenAI’s Temperature Parameter (2023).
- Damon Garn, Understanding the role of temperature settings in AI output, TechTarget (2025).
Prompt-Design
Grundprinzipien für Anfragen
Um von einem Sprachmodell zufriedenstellende Ergebnisse zu erhalten, die dem Zweck entsprechen, muss ein passender Prompt bereitgestellt werden. Prompt-Design mag zunächst entmutigend klingen, aber tatsächlich unterscheidet sich die “Methode, etwas gut zu erfragen” nicht wesentlich, ob der Gegenüber ein Sprachmodell oder ein Mensch ist. Wenn man es aus dieser Perspektive betrachtet, ist es nicht schwer. Es ist gut, die aktuelle Situation und die Anforderungen klar nach den W-Fragen zu erklären und bei Bedarf einige konkrete Beispiele hinzuzufügen. Es gibt unzählige Tipps und Techniken zum Prompt-Design, aber die meisten leiten sich von den folgenden Grundprinzipien ab.
Allgemeiner Tonfall
Es gibt viele Berichte, dass Sprachmodelle qualitativ hochwertigere Antworten ausgeben, wenn Prompts in einem höflichen, anfragenden Ton anstatt in einem herrischen Befehlston verfasst und eingegeben werden. Normalerweise ist die Wahrscheinlichkeit, dass eine Person eine Bitte gewissenhafter ausführt, auch höher, wenn man sie höflich bittet, anstatt herrisch zu befehlen. Es scheint, dass Sprachmodelle dieses Antwortmuster von Menschen lernen und nachahmen.
Rollenvergabe und Situationsbeschreibung (Wer, Warum)
Zuerst wurde die Rolle eines ‘professionellen technischen Übersetzers (professional technical translator)’ zugewiesen und kontextbezogene Informationen über den Benutzer als “ein Ingenieur-Blogger, der hauptsächlich über Mathematik, Physik und Datenwissenschaft schreibt” bereitgestellt.
1
2
3
4
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics \
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
Übermittlung der Hauptanforderung (Was)
Als Nächstes wurde die Anweisung gegeben, den vom Benutzer bereitgestellten Text im Markdown-Format von {source_lang} nach {target_lang} zu übersetzen, wobei das Format beibehalten werden soll.
1
2
3
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> \
while preserving the format.</task>
Beim Aufruf der Claude-API werden die Platzhalter {source_lang} und {target_lang} im Prompt durch die Variablen für die Ausgangs- und Zielsprache des Python-Skripts mithilfe der f-string-Funktionalität ersetzt.
Spezifizierung der Anforderungen und Beispiele (Wie)
Bei einfachen Aufgaben kann man bereits mit den vorherigen Schritten das gewünschte Ergebnis erzielen, aber bei komplexen Aufgaben können zusätzliche Erklärungen erforderlich sein.
Wenn die Anforderungen komplex und zahlreich sind, verbessert die Gliederung der einzelnen Punkte in einer Liste anstelle einer ausführlichen Beschreibung die Lesbarkeit und erleichtert das Verständnis für den Leser (ob Mensch oder Sprachmodell). Bei Bedarf ist es auch hilfreich, Beispiele bereitzustellen. In diesem Fall wurden die folgenden Bedingungen hinzugefügt.
Verarbeitung des YAML-Frontmatters
Im YAML-Frontmatter, das sich am Anfang eines für einen Jekyll-Blog in Markdown geschriebenen Beitrags befindet, werden Informationen zu ‘title’, ‘description’, ‘categories’ und ‘tags’ aufgezeichnet. Zum Beispiel lautet das YAML-Frontmatter dieses Beitrags wie folgt:
1
2
3
4
5
6
7
---
title: "Wie man Beiträge mit der Claude Sonnet 4 API automatisch übersetzt (1) – Prompt-Design"
description: "Ein Leitfaden zum Entwerfen von Prompts für die mehrsprachige Übersetzung von Markdown-Dateien und zur Automatisierung des Prozesses mit Python unter Verwendung von Anthropic/Gemini-API-Schlüsseln. Dieser erste Teil der Serie stellt die Methode und den Prozess des Prompt-Designs vor."
categories: [AI & Data, GenAI]
tags: [Jekyll, Markdown, LLM]
image: /assets/img/technology.webp
---
Beim Übersetzen eines Beitrags müssen jedoch die Tags für Titel (title) und Beschreibung (description) mehrsprachig übersetzt werden, während es für die Konsistenz der Beitrags-URL und die Wartungsfreundlichkeit besser ist, die Namen der Kategorien (categories) und Tags (tags) nicht zu übersetzen und sie auf Englisch zu belassen. Daher wurde die folgende Anweisung gegeben, um zu verhindern, dass andere Tags als ‘title’ und ‘description’ übersetzt werden. Da das Modell bereits über Informationen zum YAML-Frontmatter gelernt haben wird, reicht diese Erklärung in den meisten Fällen aus.
1
2
- <condition>please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
Mit dem Zusatz “under any circumstances, regardless of the language you are translating to” wurde betont, dass die anderen Tags des YAML-Frontmatters ausnahmslos nicht geändert werden dürfen.
(Update vom 02.04.12025) Zudem wurde angewiesen, den Inhalt des description-Tags unter Berücksichtigung von SEO in angemessener Länge zu verfassen.
1
2
3
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
Umgang mit Fällen, in denen der Originaltext andere Sprachen als die Ausgangssprache enthält
Beim Verfassen von Originaltexten auf Koreanisch kommt es häufig vor, dass bei der erstmaligen Einführung der Definition eines Konzepts oder bei der Verwendung einiger Fachbegriffe der englische Ausdruck in Klammern mit angegeben wird, wie z. B. ‘중성자 감쇠 (Neutron Attenuation)’. Bei der Übersetzung solcher Ausdrücke gab es das Problem, dass die Übersetzungsmethode inkonsistent war, mal wurden die Klammern beibehalten, mal wurde der in Klammern angegebene englische Ausdruck weggelassen. Daher wurden die folgenden detaillierten Richtlinien festgelegt.
- Bei Fachbegriffen:
- Bei der Übersetzung in eine nicht-lateinische Sprache wie Japanisch wird das Format ‘übersetzter Ausdruck (englischer Ausdruck)’ beibehalten.
- Bei der Übersetzung in eine lateinische Sprache wie Spanisch, Portugiesisch oder Französisch sind sowohl die alleinige Angabe des ‘übersetzten Ausdrucks’ als auch die parallele Angabe ‘übersetzter Ausdruck (englischer Ausdruck)’ zulässig, und das Modell kann autonom die passendere Variante wählen.
- Bei Eigennamen muss die ursprüngliche Schreibweise in irgendeiner Form im Übersetzungsergebnis erhalten bleiben.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language,
please maintain the <format>[target language expression(original English expression)]</format> in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' wird im Japanischen zu '中性子減衰(Neutron Attenuation)' übersetzt.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' wird zu '三角関数の合成(調和加法定理, Harmonic Addition Theorem)'</example>
<if>the target language is a Roman alphabet-based language, you can omit the parentheses if you deem them unnecessary.</if>
- <example>Sowohl 'Röntgenstrahlung' als auch 'Röntgenstrahlung(X-ray)' sind akzeptable deutsche Übersetzungen für 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Sowohl 'Le puits carré infini 1D' als auch 'Le puits carré infini 1D(The 1D Infinite Square Well)' sind akzeptable französische Übersetzungen für '1차원 무한 사각 우물(The 1D Infinite Square Well)'. You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses must be preserved in the translation output in some form.</else> \n\
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' sollten ins Japanische als \
'ファラデー(Faraday)', 'マクスウェル(Maxwell)' und 'アインシュタイン(Einstein)' übersetzt werden.\
In Sprachen wie Spanisch oder Portugiesisch können sie als 'Faraday', 'Maxwell', 'Einstein' übersetzt werden, in welchem Fall \
redundante Ausdrücke wie 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' höchst unangebracht wären.</example>\
</condition>\n\n
Verarbeitung von Links zu anderen Beiträgen
Einige Beiträge enthalten Links zu anderen Beiträgen. In der Testphase, als hierzu keine gesonderten Anweisungen gegeben wurden, trat häufig das Problem auf, dass interne Links brachen, weil der Pfadteil der URL als zu übersetzendes Ziel interpretiert und geändert wurde. Dieses Problem wurde durch Hinzufügen dieses Abschnitts zum Prompt gelöst.
1
2
3
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
(Update vom 06.04.12025) Die Bereitstellung der obigen Anweisung führt dazu, dass der Pfadteil von Links bei der Übersetzung korrekt behandelt wird, was die Häufigkeit von gebrochenen Links erheblich reduziert. Bei Links, die einen Fragmentbezeichner (Fragment identifier) enthalten, konnte das grundlegende Problem jedoch nicht gelöst werden, da das Sprachmodell den Fragmentbezeichner immer noch erraten musste, solange es den Inhalt des verlinkten Beitrags nicht kannte. Daher wurden das Python-Skript und der Prompt verbessert, um Kontextinformationen zu den verlinkten Beiträgen im XML-Tag <reference_context> des Benutzer-Prompts bereitzustellen und die Link-Übersetzung entsprechend diesem Kontext zu verarbeiten. Nach Anwendung dieses Updates konnten Probleme mit gebrochenen Links weitgehend vermieden werden, und es ist zu erwarten, dass bei eng miteinander verbundenen Beitragsserien eine konsistentere Übersetzung über mehrere Beiträge hinweg erzielt wird.
Im System-Prompt wird die folgende Anweisung gegeben.
1
2
3
4
5
6
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
Und der <reference_context>-Teil des Benutzer-Prompts ist wie folgt aufgebaut und wird nach dem Inhalt des zu übersetzenden Haupttextes bereitgestellt.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<reference_context>
The following are contents of posts linked with hash fragments in the original post.
Use these for context when translating links and references:
<referenced_post path="{post_1_path}" hash="{hash_fragment_1}">
{post_content}
</referenced_post>
<referenced_post path="{post__2_path}" hash="{hash_fragment_2}">
{post_content}
</referenced_post>
...
</reference_context>
Wie dies konkret umgesetzt wurde, können Sie im Teil 2 dieser Serie und im Inhalt des Python-Skripts im GitHub-Repository nachlesen.
Nur das Übersetzungsergebnis ausgeben
Zuletzt wird der folgende Satz angegeben, um sicherzustellen, dass bei der Antwort keine zusätzlichen Bemerkungen gemacht werden und nur das Übersetzungsergebnis ausgegeben wird.
1
2
3
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
Zusätzliche Techniken des Prompt-Designs
Es gibt jedoch auch zusätzliche Techniken, die speziell für Sprachmodelle gelten, im Gegensatz zu Anfragen an Menschen. Hierzu gibt es viele nützliche Ressourcen im Web, aber hier sind einige repräsentative Tipps, die allgemein nützlich sind. Hauptsächlich wurde der Prompt-Engineering-Leitfaden in der offiziellen Anthropic-Dokumentation als Referenz verwendet.
Strukturierung mithilfe von XML-Tags
Tatsächlich wurde dies bereits bisher verwendet. Bei komplexen Prompts, die verschiedene Kontexte, Anweisungen, Formate und Beispiele enthalten, hilft die angemessene Verwendung von XML-Tags wie <instructions>, <example>, <format> dem Sprachmodell, den Prompt genau zu interpretieren und eine qualitativ hochwertige Ausgabe zu erzeugen, die der Absicht entspricht. Das GitHub-Repository GENEXIS-AI/prompt-gallery enthält eine gute Zusammenfassung nützlicher XML-Tags für die Prompterstellung, die ich zur Lektüre empfehle.
Schritt-für-Schritt-Schlussfolgern (CoT, Chain-of-Thought)
Bei Aufgaben, die ein hohes Maß an Schlussfolgerungen erfordern, wie das Lösen von mathematischen Problemen oder das Verfassen komplexer Dokumente, kann die Leistung erheblich gesteigert werden, wenn das Sprachmodell dazu angeleitet wird, das Problem schrittweise zu durchdenken. Beachten Sie jedoch, dass dies die Antwortlatenz erhöhen kann und diese Technik nicht für alle Aufgaben immer nützlich ist.
Prompt-Chaining-Technik
Bei der Durchführung komplexer Aufgaben kann ein einzelner Prompt an seine Grenzen stoßen. In diesem Fall kann man in Betracht ziehen, den gesamten Arbeitsablauf von Anfang an in mehrere Schritte zu unterteilen, für jeden Schritt einen spezialisierten Prompt zu geben und die Antwort aus dem vorherigen Schritt als Eingabe für den nächsten Schritt zu verwenden. Diese Technik wird als Prompt-Chaining bezeichnet.
Vorausfüllen des Antwortanfangs
Indem man beim Eingeben des Prompts den Anfang der zu beantwortenden Inhalte vorgibt und das Modell auffordert, die nachfolgende Antwort zu verfassen, kann man unnötige Einleitungen wie Begrüßungen überspringen oder eine Antwort in einem bestimmten Format wie XML oder JSON erzwingen. Bei der Anthropic-API kann diese Technik verwendet werden, indem beim Aufruf nicht nur eine User-Nachricht, sondern auch eine Assistant-Nachricht übermittelt wird.
Verhinderung von Faulheit (31.10.12024 Halloween-Patch)
Obwohl es seit der ersten Erstellung dieses Beitrags ein oder zwei kleinere Verbesserungen am Prompt und Konkretisierungen der Anweisungen gab, funktionierte das Automatisierungssystem vier Monate lang ohne größere Probleme.
Doch am 31.10.12024 gegen 18:00 Uhr koreanischer Zeit trat wiederholt ein anormales Verhalten auf: Wenn die Übersetzung eines neu verfassten Beitrags in Auftrag gegeben wurde, wurde nur der erste ‘TL;DR’-Teil des Beitrags übersetzt und die Übersetzung dann willkürlich abgebrochen.
Die vermuteten Ursachen und Lösungen für dieses Problem werden in einem separaten Beitrag behandelt. Bitte lesen Sie diesen Beitrag.
Der fertige System-Prompt
Das Ergebnis des oben beschriebenen Prompt-Designs kann im nächsten Teil eingesehen werden.
Weiterführende Lektüre
Fortsetzung in Teil 2