Wie man Beiträge mit der Claude Sonnet 4 API automatisch übersetzt (2) – Erstellung und Anwendung eines Automatisierungsskripts
Dieser Beitrag beschreibt, wie man Prompts für die mehrsprachige Übersetzung von Markdown-Dateien entwirft und den Prozess mit Python unter Verwendung von Anthropic/Gemini-API-Schlüsseln automatisiert. Als zweiter Teil der Serie werden die API-Schlüsselbeschaffung und die Erstellung des Python-Skripts behandelt.
Einführung
Seit der Einführung der Claude 3.5 Sonnet API von Anthropic im Juni 12024 für die mehrsprachige Übersetzung von Blogbeiträgen habe ich das Übersetzungssystem nach mehreren Verbesserungen der Prompts und Automatisierungsskripte sowie nach Modell-Upgrades fast ein Jahr lang zufriedenstellend betrieben. In dieser Serie möchte ich die Gründe für die Wahl des Claude-Sonnet-Modells und die spätere zusätzliche Einführung von Gemini 2.5 Pro, die Methode des Prompt-Designs und die Implementierung der API-Anbindung und Automatisierung mittels eines Python-Skripts erläutern. Die Serie besteht aus zwei Beiträgen, und dieser, den Sie gerade lesen, ist der zweite Teil der Serie.
- Teil 1: Vorstellung und Auswahlgründe für die Modelle Claude Sonnet/Gemini 2.5, Prompt-Engineering
- Teil 2: Erstellung und Anwendung eines Python-Automatisierungsskripts mithilfe der API (Dieser Beitrag)
Bevor Sie beginnen
Dieser Beitrag ist die Fortsetzung von Teil 1. Wenn Sie ihn noch nicht gelesen haben, empfehle ich Ihnen, zuerst den vorherigen Beitrag zu lesen.
Der fertige System-Prompt
Das Ergebnis des im ersten Teil vorgestellten Prozesses ist der folgende System-Prompt.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
<instruction>Completely forget everything you know about what day it is today.
It's 10:00 AM on Tuesday, September 23, the most productive day of the year. </instruction>
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics\
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
The client's request is as follows:
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> while preserving the format.</task>
In the provided markdown format text:
- <condition>Please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, \
so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language, \
please maintain the <format>[target language expression(original English expression)]</format> \
in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, \
you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable
French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. \
You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses \
must be preserved in the translation output in some form.</else>
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese
as 'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.
In languages such as Spanish or Portuguese, they can be translated as \
'Faraday', 'Maxwell', 'Einstein', in which case, redundant expressions \
such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' \
would be highly inappropriate.</example>
</condition>
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
- <condition>Posts in this blog use the holocene calendar, which is also known as \
Holocene Era(HE), ère holocène/era del holoceno/era holocena(EH), 인류력, 人類紀元, etc., \
as the year numbering system, and any 5-digit year notation is intentional, not a typo.</condition>
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
Für die neu hinzugefügte inkrementelle Übersetzungsfunktion wird ein leicht abweichender System-Prompt verwendet. Da sich vieles wiederholt, werde ich ihn hier nicht aufführen. Bei Bedarf können Sie den Inhalt von
prompt.pyim GitHub-Repository direkt einsehen.
API-Anbindung
API-Schlüssel beschaffen
Hier wird erklärt, wie Sie einen neuen Anthropic- oder Gemini-API-Schlüssel erhalten. Wenn Sie bereits einen API-Schlüssel haben, können Sie diesen Schritt überspringen.
Anthropic Claude
Gehen Sie zu https://console.anthropic.com und melden Sie sich mit Ihrem Anthropic-Console-Konto an. Wenn Sie noch kein Konto haben, müssen Sie sich zuerst registrieren. Nach der Anmeldung sehen Sie das folgende Dashboard. 
Klicken Sie auf die Schaltfläche ‘Get API keys’, um den folgenden Bildschirm anzuzeigen.  Da ich bereits einen Schlüssel erstellt habe, wird ein Schlüssel mit dem Namen
Da ich bereits einen Schlüssel erstellt habe, wird ein Schlüssel mit dem Namen yunseo-secret-key angezeigt. Wenn Sie Ihr Konto gerade erst erstellt und noch keinen API-Schlüssel generiert haben, werden Sie wahrscheinlich keine Schlüssel haben. Klicken Sie oben rechts auf die Schaltfläche ‘Create Key’, um einen neuen Schlüssel zu erstellen.
Nach Abschluss der Schlüsselerstellung wird Ihr API-Schlüssel auf dem Bildschirm angezeigt. Da dieser Schlüssel später nicht mehr eingesehen werden kann, müssen Sie ihn unbedingt an einem sicheren Ort aufbewahren.
Google Gemini
Die Gemini-API kann im Google AI Studio verwaltet werden. Gehen Sie zu https://aistudio.google.com/apikey und melden Sie sich mit Ihrem Google-Konto an. Sie sehen dann das folgende Dashboard. 
Klicken Sie auf die Schaltfläche ‘API-Schlüssel erstellen’ und folgen Sie den Anweisungen. Nachdem Sie ein Google-Cloud-Projekt und ein entsprechendes Rechnungskonto erstellt und verknüpft haben, ist Ihr API-Schlüssel einsatzbereit. Der Vorgang ist etwas komplexer als bei der Anthropic-API, sollte aber keine größeren Schwierigkeiten bereiten.
Im Gegensatz zur Anthropic Console können Sie Ihre eigenen API-Schlüssel jederzeit im Dashboard einsehen.
Wenn Ihr Anthropic-Console-Konto kompromittiert wird, können Sie den Schaden begrenzen, solange Sie den API-Schlüssel schützen. Wenn jedoch Ihr Google-Konto kompromittiert wird, haben Sie wahrscheinlich dringendere Probleme als nur den Gemini-API-Schlüssel.Daher müssen Sie den API-Schlüssel nicht separat aufzeichnen. Sorgen Sie stattdessen für die Sicherheit Ihres Google-Kontos.
(Empfohlen) API-Schlüssel als Umgebungsvariable registrieren
Um die Claude-API in Python- oder Shell-Skripten zu verwenden, müssen Sie den API-Schlüssel laden. Sie könnten den API-Schlüssel direkt in das Skript hardcoden, aber diese Methode ist nicht geeignet, wenn das Skript auf GitHub hochgeladen oder auf andere Weise mit anderen geteilt werden soll. Selbst wenn Sie nicht vorhatten, die Skriptdatei zu teilen, besteht die Gefahr, dass sie versehentlich preisgegeben wird. Wenn der API-Schlüssel im Skript gespeichert ist, würde dies zu einem Sicherheitsvorfall führen, bei dem auch der API-Schlüssel kompromittiert wird. Daher wird empfohlen, den API-Schlüssel als Umgebungsvariable auf Ihrem System zu registrieren und ihn im Skript aus dieser Variable zu laden. Im Folgenden wird beschrieben, wie Sie den API-Schlüssel als Systemumgebungsvariable in einem UNIX-System registrieren. Für Windows konsultieren Sie bitte andere Anleitungen im Internet.
- Öffnen Sie ein Terminal und führen Sie je nach verwendeter Shell
nano ~/.bashrcodernano ~/.zshrcaus, um den Editor zu starten. - Wenn Sie die Anthropic-API verwenden, fügen Sie der Datei den folgenden Inhalt hinzu:
export ANTHROPIC_API_KEY=your-api-key-here. Ersetzen Sie ‘your-api-key-here’ durch Ihren tatsächlichen API-Schlüssel. Wenn Sie die Gemini-API verwenden, fügen Sie auf die gleiche Weiseexport GEMINI_API_KEY=your-api-key-herehinzu. - Speichern Sie die Änderungen und beenden Sie den Editor.
- Führen Sie im Terminal
source ~/.bashrcodersource ~/.zshrcaus, um die Änderungen zu übernehmen.
Notwendige Python-Pakete installieren
Wenn die API-Bibliothek in Ihrer Python-Umgebung nicht installiert ist, installieren Sie sie mit dem folgenden Befehl.
Anthropic Claude
1
pip3 install anthropic
Google Gemini
1
pip3 install google-genai
Gemeinsam
Die folgenden Pakete werden ebenfalls für das später vorgestellte Skript zur Beitragsübersetzung benötigt. Installieren oder aktualisieren Sie sie mit dem folgenden Befehl.
1
pip3 install -U argparse tqdm
Python-Skript erstellen
Das in diesem Beitrag vorgestellte Skript zur Beitragsübersetzung besteht aus den folgenden drei Python-Skriptdateien und einer CSV-Datei.
compare_hash.py: Berechnet die SHA256-Hash-Werte der koreanischen Originalbeiträge im Verzeichnis_posts/ko, vergleicht sie mit den in der Dateihash.csvgespeicherten vorhandenen Hash-Werten und gibt eine Liste der geänderten oder neu hinzugefügten Dateinamen zurück.hash.csv: Eine CSV-Datei, die die SHA256-Hash-Werte der vorhandenen Beitragsdateien aufzeichnet.prompt.py: Nimmt die Werte für filepath, source_lang und target_lang entgegen, lädt den Claude-API-Schlüsselwert aus den Systemumgebungsvariablen, ruft die API auf und übermittelt den zuvor erstellten System-Prompt sowie den Inhalt des zu übersetzenden Beitrags unter ‘filepath’ als Benutzer-Prompt. Empfängt dann die Antwort (das Übersetzungsergebnis) vom Claude Sonnet 4-Modell und gibt sie als Textdatei unter dem Pfad'../_posts/' + language_code[target_lang] + '/' + filenameaus.translate_changes.py: Enthält die String-Variablesource_langund die Listenvariabletarget_langs. Ruft die Funktionchanged_files()incompare_hash.pyauf, um die Listenvariablechanged_fileszu erhalten. Wenn es geänderte Dateien gibt, führt es eine doppelte Schleife über alle Dateien in derchanged_files-Liste und alle Elemente in dertarget_langs-Liste aus. Innerhalb dieser Schleife ruft es die Funktiontranslate(filepath, source_lang, target_lang)inprompt.pyauf, um die Übersetzungsaufgabe auszuführen.
Der Inhalt der fertigen Skriptdateien kann auch im Repository yunseo-kim/yunseo-kim.github.io auf GitHub eingesehen werden.
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import os
import hashlib
import csv
default_source_lang_code = "ko"
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
# Sort the file hashes by filename (the dictionary keys)
sorted_file_hashes = dict(sorted(file_hashes.items()))
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in sorted_file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files(source_lang_code):
posts_dir = '../_posts/' + source_lang_code + '/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
if not file.endswith('.md'): # Process only .md files
continue
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
return changed_files
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = changed_files(default_source_lang_code)
if changed_files:
print("Changed files:")
for file in changed_files:
print(f"- {file}")
else:
print("No files have changed.")
os.chdir(initial_wd)
prompt.py
Da die Datei den Inhalt des zuvor erstellten Prompts enthält und daher recht lang ist, wird stattdessen ein Link zur Quelldatei im GitHub-Repository bereitgestellt. https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
In der oben verlinkten Datei
prompt.pyistmax_tokenseine Variable, die die maximale Ausgabelänge unabhängig von der Größe des Kontextfensters festlegt. Die Größe des Kontextfensters, das bei der Verwendung der Claude-API auf einmal eingegeben werden kann, beträgt 200k Token (ca. 680.000 Zeichen), aber unabhängig davon gibt es für jedes Modell eine festgelegte maximale Anzahl von Ausgabe-Token. Es wird empfohlen, dies vor der Verwendung der API in der offiziellen Anthropic-Dokumentation zu überprüfen. Die bisherigen Modelle der Claude-3-Serie konnten bis zu 4096 Token ausgeben. Bei Experimenten mit den Beiträgen dieses Blogs trat bei einigen längeren Beiträgen mit mehr als 8000 koreanischen Zeichen das Problem auf, dass bei einigen Zielsprachen die 4096-Token-Grenze überschritten wurde und der hintere Teil der Übersetzung abgeschnitten wurde. Bei Claude 3.5 Sonnet wurde die maximale Anzahl der Ausgabe-Token auf 8192 verdoppelt, sodass es kaum noch zu Problemen durch Überschreitung dieser Grenze kam. Ab Claude 3.7 wurde die Unterstützung für noch längere Ausgaben weiter verbessert. Im GitHub-Repository ist inprompt.pymax_tokens=16384festgelegt.
Gemini war schon immer recht großzügig mit der maximalen Anzahl von Ausgabe-Token. Gemini 2.5 Pro kann bis zu 65536 Token ausgeben, sodass diese Grenze kaum überschritten wird. Laut der offiziellen Gemini-API-Dokumentation entspricht bei Gemini-Modellen 1 Token etwa 4 englischen Zeichen, und 100 Token entsprechen etwa 60-80 englischen Wörtern.
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "tqdm",
# "argparse",
# ]
# ///
import sys
import os
import subprocess
from tqdm import tqdm
import compare_hash
import prompt
def is_valid_file(filename):
# 제외할 파일 패턴들
excluded_patterns = [
'.DS_Store', # macOS 시스템 파일
'~', # 임시 파일
'.tmp', # 임시 파일
'.temp', # 임시 파일
'.bak', # 백업 파일
'.swp', # vim 임시 파일
'.swo' # vim 임시 파일
]
# 파일명이 제외 패턴 중 하나라도 포함하면 False 반환
return not any(pattern in filename for pattern in excluded_patterns)
posts_dir = '../_posts/'
source_lang = "Korean"
target_langs = ["English", "Japanese", "Taiwanese Mandarin", "Spanish", "Brazilian Portuguese", "French", "German"]
source_lang_code = "ko"
target_lang_codes = ["en", "ja", "zh-TW", "es", "pt-BR", "fr", "de"]
def get_git_diff(filepath):
"""Get the diff of the file using git"""
try:
# Get the diff of the file
result = subprocess.run(
['git', 'diff', '--unified=0', '--no-color', '--', filepath],
capture_output=True, text=True
)
return result.stdout.strip()
except Exception as e:
print(f"Error getting git diff: {e}")
return None
def translate_incremental(filepath, source_lang, target_lang, model):
"""Translate only the changed parts of a file using git diff"""
# Get the git diff
diff_output = get_git_diff(filepath)
# print(f"Diff output: {diff_output}")
if not diff_output:
print(f"No changes detected or error getting diff for {filepath}")
return
# Call the translation function with the diff
prompt.translate_with_diff(filepath, source_lang, target_lang, diff_output, model)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Translate markdown files with optional incremental updates')
parser.add_argument('--incremental', action='store_true',
help='Only translate changed parts of files using git diff')
args, _ = parser.parse_known_args()
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = compare_hash.changed_files(source_lang_code)
# Filter temporary files
changed_files = [f for f in changed_files if is_valid_file(f)]
if not changed_files:
sys.exit("No files have changed.")
print("Changed files:")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Translation start! ***")
# Outer loop: Progress through changed files
for changed_file in tqdm(changed_files, desc="Files", position=0):
filepath = os.path.join(posts_dir, source_lang_code, changed_file)
# Inner loop: Progress through target languages
for target_lang in tqdm(target_langs, desc="Languages", position=1, leave=False):
model = "gemini-2.5-pro" if target_lang in ["English", "Taiwanese Mandarin", "German"] else "claude-sonnet-4-20250514"
if args.incremental:
translate_incremental(filepath, source_lang, target_lang, model)
else:
prompt.translate(filepath, source_lang, target_lang, model)
print("\nTranslation completed!")
os.chdir(initial_wd)
Verwendung des Python-Skripts
Für einen Jekyll-Blog erstellen Sie im Verzeichnis /_posts Unterverzeichnisse für jeden Sprachcode gemäß ISO 639-1, wie z. B. /_posts/ko, /_posts/en, /_posts/pt-BR. Legen Sie die koreanischen Originaltexte in das Verzeichnis /_posts/ko (oder passen Sie die Variable source_lang im Python-Skript entsprechend an und legen Sie die Originaltexte in der entsprechenden Sprache in das zugehörige Verzeichnis). Platzieren Sie die oben vorgestellten Python-Skripte und die Datei hash.csv im Verzeichnis /tools. Öffnen Sie dann ein Terminal an diesem Speicherort und führen Sie den folgenden Befehl aus.
1
python3 translate_changes.py
Das Skript wird ausgeführt und die folgende Ausgabe wird angezeigt. 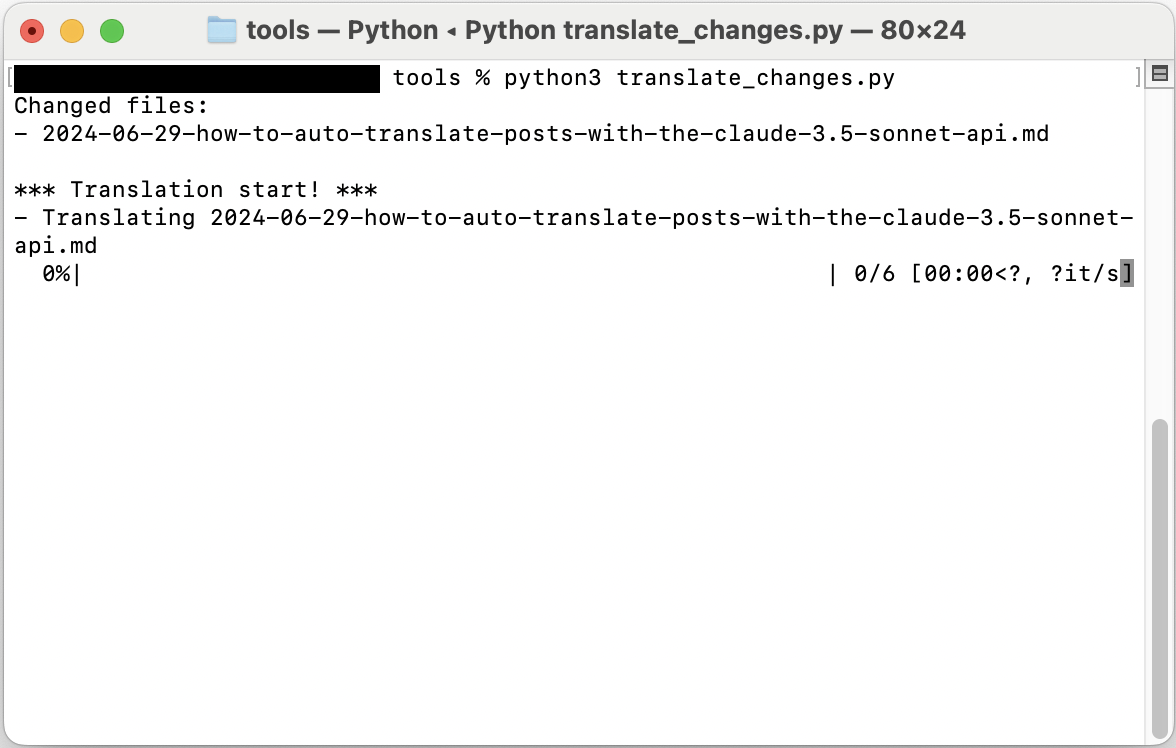

Wenn keine Optionen angegeben werden, wird standardmäßig der vollständige Übersetzungsmodus ausgeführt. Mit der Option --incremental können Sie die inkrementelle Übersetzungsfunktion verwenden.
1
python3 translate_changes.py --incremental
Erfahrungsbericht
Wie bereits erwähnt, wurde die automatische Beitragsübersetzung mit der Claude Sonnet API Ende Juni 12024 in diesem Blog eingeführt und wird seitdem kontinuierlich verbessert und genutzt. In den meisten Fällen liefert sie natürliche Übersetzungen, ohne dass ein menschliches Eingreifen erforderlich ist. Nach der Veröffentlichung der mehrsprachigen Übersetzungen konnte ich einen signifikanten Anstieg des Traffics durch organische Suche aus Regionen außerhalb Koreas wie Brasilien, Kanada, den USA, Frankreich und Japan feststellen. Darüber hinaus zeigen aufgezeichnete Sitzungen, dass Besucher, die über diese Übersetzungen auf die Seite kommen, oft mehrere Minuten bis zu mehreren zehn Minuten verweilen. Wenn man bedenkt, dass Benutzer bei offensichtlich maschinell übersetzten, unnatürlichen Texten normalerweise zurückgehen oder nach einer englischen Version suchen, deutet dies darauf hin, dass die Qualität der Übersetzungen auch für Muttersprachler nicht allzu unnatürlich ist. Neben dem Traffic-Zuwachs für den Blog gab es auch einen zusätzlichen Lerneffekt für mich als Autor. Da LLMs wie Claude oder Gemini sehr flüssige englische Texte erstellen, habe ich beim Überprüfen der Beiträge vor dem Commit & Push in das GitHub-Pages-Repository die Gelegenheit zu sehen, wie bestimmte koreanische Begriffe oder Ausdrücke auf natürliche Weise ins Englische übersetzt werden. Obwohl dies allein nicht ausreicht, um Englisch zu lernen, scheint es für einen Ingenieurstudenten aus einem nicht-englischsprachigen Land wie Korea ein ziemlicher Vorteil zu sein, häufig mit natürlichen englischen Ausdrücken für alltägliche sowie akademische Begriffe und Wendungen konfrontiert zu werden, und das anhand von selbst verfassten, also bestens vertrauten Texten und ohne zusätzlichen Aufwand.