Claude Sonnet 4 API로 포스트 자동 번역하는 법 (1) - 프롬프트 디자인
마크다운 텍스트 파일의 다국어 번역을 위한 프롬프트를 디자인하고, Anthropic/Gemini API 키와 작성한 프롬프트를 적용하여 Python으로 작업을 자동화하는 과정을 다룬다. 이 포스트는 해당 시리즈의 첫 번째 글로, 프롬프트 디자인 방법과 과정을 소개한다.
들어가며
12024년 6월에 블로그 포스트의 다국어 번역을 위해 Anthropic의 Claude 3.5 Sonnet API를 도입한 이후, 수 차례의 프롬프트 및 자동화 스크립트 개선, 그리고 모델 버전 업그레이드를 거쳐 약 1년에 가까운 기간 동안 해당 번역 시스템을 만족스럽게 운용하고 있다. 이에 이 시리즈에서는 도입 과정에서 Claude Sonnet 모델을 선택하고 이후 Gemini 2.5 Pro를 추가 도입한 이유와 프롬프트 디자인 방법, 그리고 Python 스크립트를 통한 API 연동 및 자동화 구현 방법을 다루고자 한다.
시리즈는 2개의 글로 이루어져 있으며, 읽고 있는 이 글은 해당 시리즈의 첫 번째 글이다.
- 1편: Claude Sonnet/Gemini 2.5 모델 소개 및 선정 이유, 프롬프트 엔지니어링 (본문)
- 2편: API를 활용한 Python 자동화 스크립트 작성 및 적용
About Claude Sonnet
Claude 시리즈 모델은 모델 크기에 따라 Haiku, Sonnet, 그리고 Opus 버전이 제공된다.
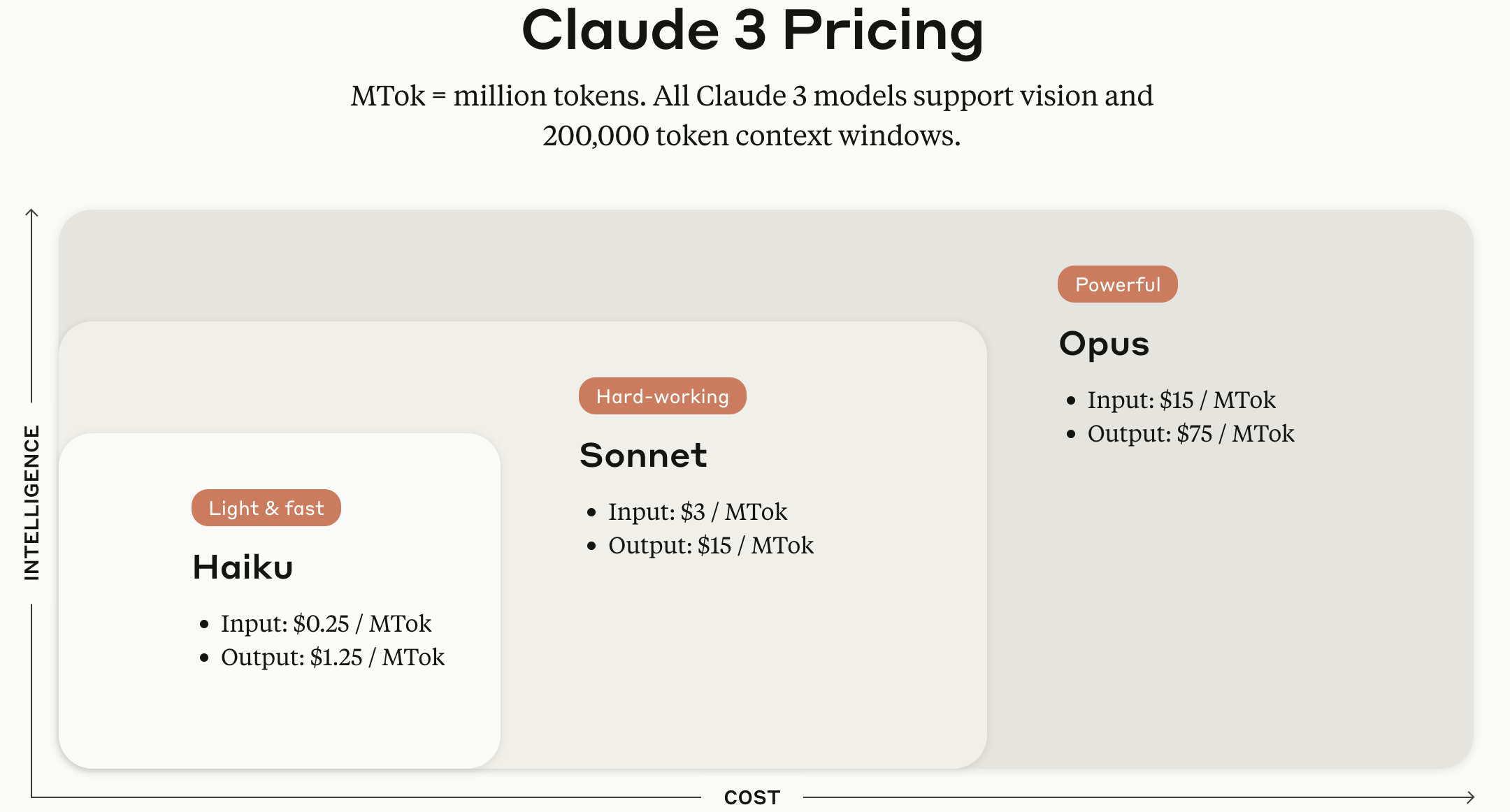
이미지 출처: Anthropic Claude API 공식 웹페이지
(12025.05.29. 추가)
1년 전 캡처한 이미지라 토큰당 요금이 구 버전인 Claude 3 기준으로 나와 있으나, 모델 크기에 따른 Haiku, Sonnet, Opus 구분은 아직 유효하다. 12025년 5월 말 기준으로 Anthropic에서 제공하는 각 모델별 가격 책정은 다음과 같다.
Model Base Input
Tokens5m Cache
Writes1h Cache
WritesCache Hits &
RefreshesOutput
TokensClaude Opus 4 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Sonnet 4 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.7 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Sonnet 3.5 $3 / MTok $3.75 / MTok $6 / MTok $0.30 / MTok $15 / MTok Claude Haiku 3.5 $0.80 / MTok $1 / MTok $1.6 / MTok $0.08 / MTok $4 / MTok Claude Opus 3 $15 / MTok $18.75 / MTok $30 / MTok $1.50 / MTok $75 / MTok Claude Haiku 3 $0.25 / MTok $0.30 / MTok $0.50 / MTok $0.03 / MTok $1.25 / MTok
그리고 한국 시각으로 인류력 12024년 6월 21일에 Anthropic에서 공개한 언어모델 Claude 3.5 Sonnet는 기존의 Claude 3 Sonnet와 동일한 비용과 속도로 Claude 3 Opus를 능가하는 추론 성능을 보이며, 대체로 작문과 언어 추론, 다국어 이해 및 번역 분야에서 경쟁 모델인 GPT-4 대비 강점을 보인다는 평이 지배적이다.
이미지 출처: Anthropic Newsroom
포스트 번역을 위해 Claude 3.5를 도입한 이유
굳이 Claude 3.5나 GPT-4와 같은 언어모델이 아니더라도 구글 번역이나 DeepL과 같은 기존의 상용 번역 API가 존재한다. 그럼에도 번역 목적으로 LLM을 사용하기로 결정한 이유는 다른 상용 번역 서비스와 달리 사용자가 프롬프트 디자인을 통해 모델에게 글의 작성 목적이나 주요 주제 등 본문 외에도 추가적인 맥락 정보나 요구사항을 제공할 수 있고, 모델은 이에 맞추어 문맥을 고려한 번역을 제공할 수 있기 때문이다.
DeepL이나 구글 번역도 대체로 뛰어난 번역 품질을 보이는 편이지만, 글의 주제나 전체적인 맥락을 잘 파악하지 못하며 별도로 복잡한 요구사항을 전달할 수는 없다는 한계 때문에 일상적인 회화가 아닌 전문적인 주제의 긴 글을 번역하도록 요청했을 때는 상대적으로 번역 결과물이 부자연스러운 경우가 있고 필요로 하는 특정 형식(마크다운, YAML frontmatter 등)에 정확히 맞추어 출력하기 어렵다는 문제가 있다.
특히나 Claude는 상술하였듯 경쟁 모델인 GPT-4 대비 작문, 언어 추론, 다국어 이해 및 번역 분야에서는 상대적으로 더 뛰어나다는 평이 많았고 직접 간단히 테스트해 보았을 때도 GPT-4보다 좀 더 매끄러운 번역 품질을 보였기에, 도입을 고려하던 12024년 6월 당시 이 블로그에 기재하는 공학 관련 글들을 여러 언어로 번역하는 작업에 적합하다고 판단하였다.
업데이트 이력
12024.07.01.
별도의 글로 정리했다시피, Polyglot 플러그인을 적용하고 그에 맞춰 _config.yml과 html 헤더, sitemap을 수정하는 초기 작업을 완료하였다. 뒤이어 Claude 3.5 Sonnet 모델을 번역 목적으로 채택하고, 이 시리즈에서 다루고 있는 API 연동 파이썬 스크립트의 초기 구현 및 검증을 마친 후에 적용하였다.
12024.10.31.
12024년 10월 22일, Anthropic에서 Claude 3.5 Sonnet의 업그레이드 버전 API(“claude-3-5-sonnet-20241022”)와 Claude 3.5 Haiku를 발표하였다. 다만 후술할 문제로 인해 아직은 본 블로그에는 기존의 “claude-3-5-sonnet-20240620” API를 적용하고 있다.
12025.04.02.
적용 모델을 “claude-3-5-sonnet-20240620”에서 “claude-3-7-sonnet-20250219”로 전환하였다.
12025.05.29.
적용 모델을 “claude-3-7-sonnet-20250219”에서 “claude-sonnet-4-20250514”로 전환하였다.
이미지 출처: Anthropic Newsroom
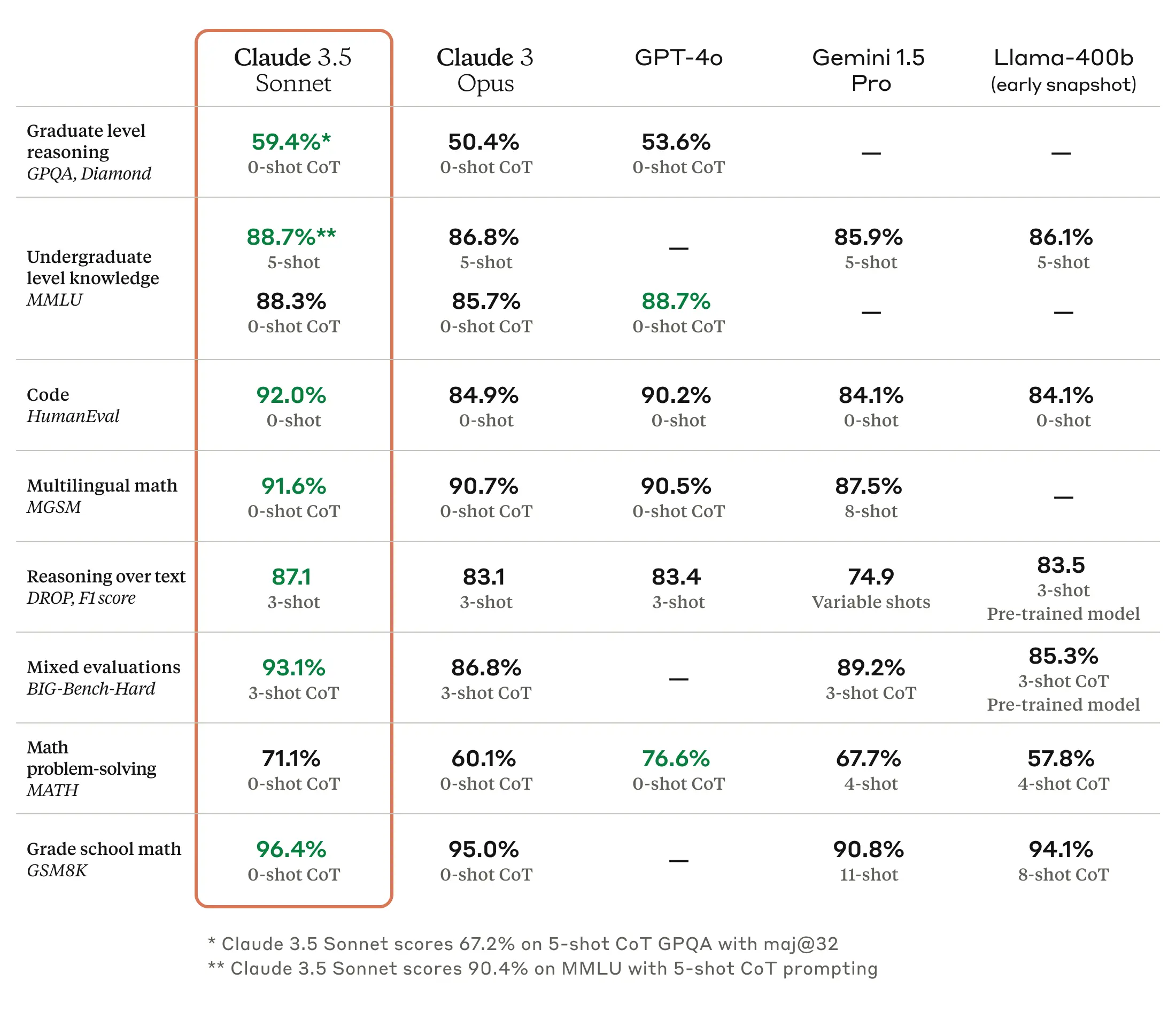
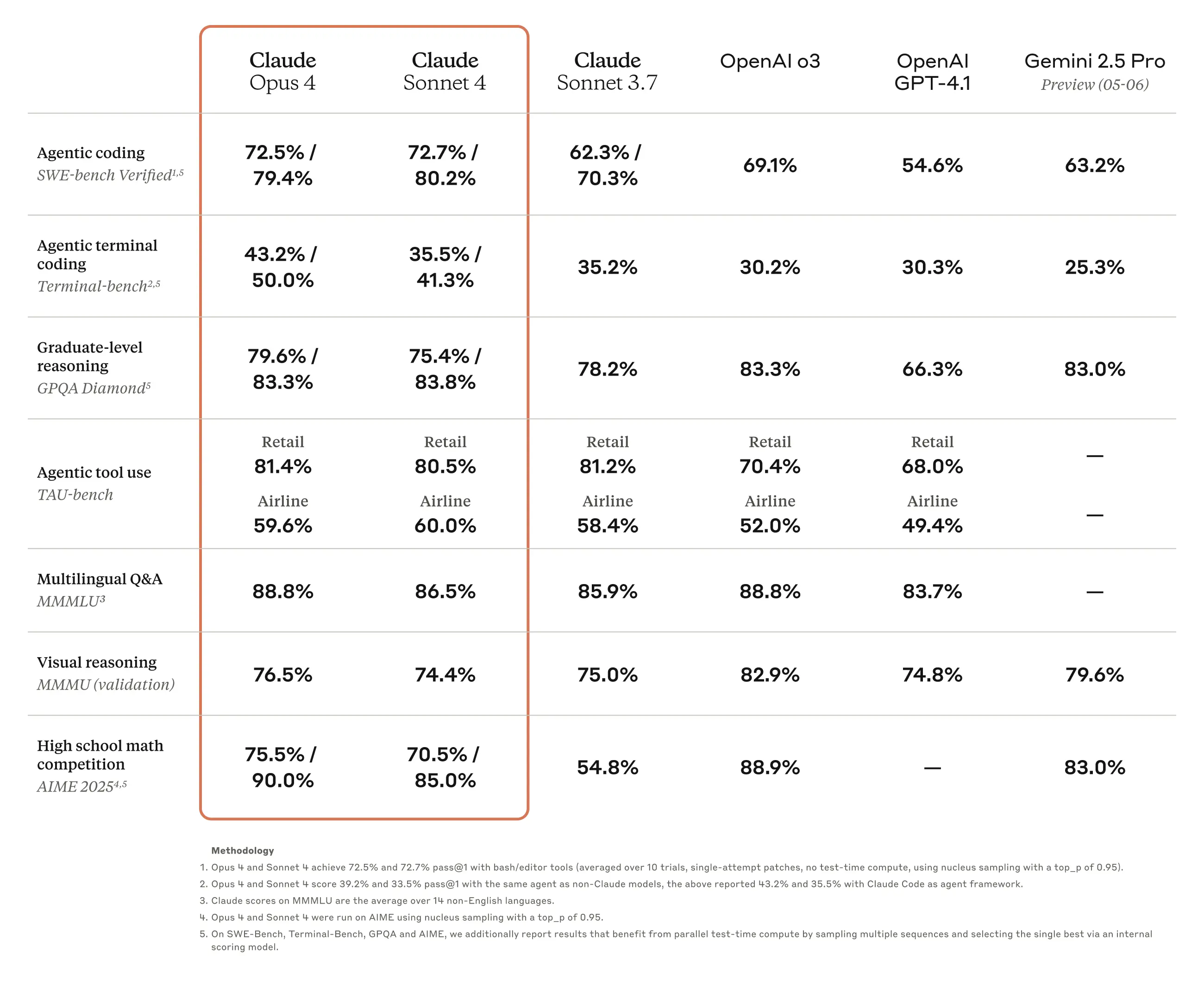
사용 조건에 따라 차이가 있을 수는 있겠지만, 대체로 Claude 3.7 Sonnet 모델이 나온 이래로 코딩에 있어서는 Claude가 가장 강력한 모델이라는 것에 이견이 별로 없는 분위기이다. Anthropic 역시 OpenAI나 Google 등의 경쟁 모델 대비 우수한 코딩 성능을 자사 모델의 주요 강점으로 적극적으로 내세우고 있는 상황이다. 이번 Claude Opus 4와 Claude Sonnet 4 발표에서도 코딩 성능을 강조하며 개발자들을 주 고객층으로 노리는 기조를 이어가는 것을 확인할 수 있다.
물론 공개한 벤치마크 결과를 보면 코딩 이외의 항목에서도 전반적으로 개선이 이루어졌으며, 이 글에서 다루는 번역 작업의 경우에는 다국어 질의응답(MMMLU)이나 수학 문제풀이(AIME 2025) 부문의 성능 향상이 특히 유효하게 작용할 것으로 보인다. 직접 간단히 테스트 해 본 결과, 이전 모델인 Claude 3.7 Sonnet 대비 Claude Sonnet 4의 번역 결과물이 표현의 자연스러움이나 전문성, 용어 사용의 일관성 등에서 더 뛰어난 것을 확인할 수 있었다.
현 시점에서, 적어도 이 블로그에서 다루는 것과 같이 기술적인 성격의 한국어로 쓰인 글을 다국어로 번역하는 작업에서는 Claude 모델이 여전히 가장 뛰어나다 생각한다. 다만 최근 들어 Google의 Gemini 모델의 성능이 눈에 띄게 좋아지고 있고, 올해 5월 들어서는 아직 Preview 단계이긴 하나 Gemini 2.5 모델까지 공개한 상황이다.
Gemini 2.0 Flash 모델과 Claude 3.7 Sonnet, Claude Sonnet 4 모델을 비교했을 때는 Claude의 번역 성능이 더 우수하다고 판단하였으나, Gemini의 다국어 성능도 상당히 훌륭한 편인데다 Preview 단계임에도 불구하고 Gemini 2.5 Preview 05-06의 수학, 물리 문제풀이 및 서술 능력은 오히려 Claude Opus 4보다도 더 뛰어난 상황이라 해당 모델이 정식 공개되고 다시 비교해보면 어떨지는 장담할 수 없다.
일정 사용량까지는 무료 등급(Free Tier)으로 사용이 가능한 데다 유료 등급(Paid Tier) 기준으로도 Claude 대비 저렴한 API 요금을 고려하면 Gemini 쪽의 가격 경쟁력이 월등하기 때문에, 어느 정도 대등한 성능만 나오더라도 Gemini가 합리적인 대안이 될 수 있다. Gemini 2.5는 아직 Preview 단계이니만큼 실제 자동화에 적용하기엔 이르다 판단하여 당장은 고려하고 있지 않으나, 추후 정식 버전이 공개되면 테스트를 해 볼 계획이다.
12025.07.04.
- 증분 번역 기능 추가
- 번역 도착 언어에 따른 적용 모델 이원화(Commit 3890c82, Commit fe0fc63)
- 영어, 대만 중국어, 독일어로 번역 시 “gemini-2.5-pro” 사용
- 일본어, 에스파냐어, 포르투갈어, 프랑스어로 번역 시 기존의 “claude-sonnet-4-20250514”를 계속 사용
temperature값을0.0에서0.2로 상향 조정하는 안을 고려하였으나 원래대로 롤백함
12025년 7월 4일, 마침내 Gemini 2.5 Pro 및 Gemini 2.5 Flash 모델이 Preview 단계를 벗어나 정식 공개되었다. 사용한 예문 수가 한정적이긴 하나, 개인적으로 테스트해 보니 영문 번역 기준으로는 Gemini 2.5 Flash만 해도 기존 Claude Sonnet 4보다 더 자연스럽게 처리하는 부분도 제법 있었다. Gemini 2.5 Pro와 Flash 모델의 출력 토큰당 요금이 유료 등급 기준으로도 Claude Sonnet 4보다 각각 1.5배, 6배 저렴하다는 점을 고려하면 영문 기준으로는 사실상 12025년 7월 현 시점에서 제일 경쟁력 있는 모델이라고 할 수 있다. 다만 Gemini 2.5 Flash 모델의 경우 소형 모델의 한계인지 출력 결과물이 대체로 뛰어나긴 하지만, 일부 마크다운 문서 형식이나 내부 링크가 깨지는 등의 문제가 있어 복잡한 문서 번역 및 가공 작업에는 적합하지 않았다. 또한 영문에 대해서는 Gemini 2.5 Pro가 확실히 뛰어난 성능을 보이나, 대부분의 포르투갈어(pt-BR) 포스트, 그리고 일부 에스파냐어 포스트에 대한 처리는 학습된 데이터의 양이 부족한 것인지 어려워하는 모습을 보였다. 발생한 오류들을 살펴보면 대부분 ‘í’와 ‘i’, ‘ó’와 ‘o’, ‘ç’와 ‘c’, 그리고 ‘ã’와 ‘a’ 등 비슷한 문자들을 혼동하여 발생한 문제들이었다. 또한 프랑스어에 대해서는 상술한 것과 같은 문제는 없었지만 종종 문장이 지나치게 장황하여 Claude Sonnet 4에 비해 가독성이 떨어지는 경우가 있었다.
내가 영어 외의 언어는 잘은 몰라서 상세하고 정확한 비교는 어려우나, 개략적인 언어별 응답 품질을 비교해 보면 다음과 같았다.
- 영어, 독일어, 대만 중국어: Gemini가 우수함
- 일본어, 프랑스어, 에스파냐어, 포르투갈어: Claude가 우수함
또한 포스트 번역 스크립트에 증분 번역(Incremental Translation) 기능을 추가하였다. 글을 처음 작성할 때 꼼꼼하게 검토하려 노력하지만 그럼에도 글을 올리고 나서 뒤늦게 오탈자 등 사소한 오류를 발견하거나, 혹은 추가/수정하면 좋을 내용이 떠오를 때가 있다. 그런데 이런 경우에 전체 글 중 수정한 분량은 제한적임에도 불구하고, 기존 스크립트는 전체 글을 처음부터 끝까지 다시 번역하고 출력해야 해서 API 사용량 측면에서 다소 비효율적인 문제가 있었다. 이에 git과 연동하여 한국어 원문의 버전 비교를 수행하고, 원문의 변경된 부분을 diff 형식으로 추출하여 변경 이전의 번역문 전문과 함께 프롬프트로 입력한 뒤 번역문에 대한 diff 패치를 출력으로 받아서 필요한 부분만 선택적으로 수정하는 기능을 추가하였다. 입력 토큰당 요금이 출력 토큰당 요금보다 크게 저렴하기 때문에 유의미한 비용 절감 효과를 기대할 수 있고, 따라서 앞으로는 글을 일부분만 수정한 경우에도 각 언어별 번역문을 직접 수정하지 않고 부담 없이 자동 번역 스크립트를 적용할 수 있을 것이다.
한편, temperature란 언어 모델이 응답을 출력하는 과정에서 각 단어에 대해 그 다음에 올 단어를 선택할 때 어느 정도의 무작위성을 부여할 것인지 조정하는 매개변수이다. 음이 아닌 실수(*후술하겠지만 보통 $[0,1]$ 내지 $[0,2]$의 범위)의 값을 갖는데, 0에 가까운 작은 값일수록 더 결정론적이고 일관적인 응답을 생성하고 값이 커질수록 보다 다양하고 창의적인 응답을 생성한다.
번역의 목적은 원문의 의미, 어조를 다른 언어로 최대한 정확하고 일관적이게 전달하는 것이지 창의적으로 새로운 내용을 만들어 내는 것이 아니므로, 번역의 정확성, 일관성, 그리고 예측 가능성을 확보하기 위해서는 낮은 temperature 값을 사용해야 한다. 다만 temperature를 0.0으로 설정하면 모델이 항상 가장 확률이 높은 단어만을 선택하게 되는데, 경우에 따라선 번역을 너무 직역에 가깝게 만들거나 부자연스럽고 뻣뻣한 문장을 생성할 수 있어서 응답이 지나치게 경직되는 것을 막고 어느 정도는 유연성을 부여하기 위해 temperature 값을 0.2로 약간 상향 조정하는 안을 고려하였으나 부분 식별자(Fragment identifier)를 포함하는 복잡한 링크에 대한 처리 정확도가 급감하는 문제가 있어 적용하지 않기로 하였다.
* 대부분의 경우 실용적으로 사용되는
temperature값은 0 이상 1 이하의 범위이며, Anthropic API에서의 허용 범위 또한 $[0,1]$이다. OpenAI API나 Gemini API에서는 보다 넓은 $[0,2]$의temperature값을 허용하지만,temperature범위가 $[0,2]$로 확장되었다고 해서 스케일도 2배가 되는 것은 아니며 $T=1$의 의미는 $[0,1]$ 범위를 쓰는 모델과 동일하다.언어모델이 출력을 생성할 때 내부적으로는 프롬프트 및 이전까지의 출력 토큰들을 입력으로 받아 다음에 나올 토큰의 확률 분포를 응답으로 내놓는 일종의 함수로 동작하며, 그 확률분포에 따른 시행의 결과가 다음 토큰으로 결정되어 출력된다. 해당 확률분포를 그대로 사용하는 기준값이 $T=1$로, $T<1$일 경우에는 확률분포를 좁고 뾰족하게 만들어 가장 확률이 높은 단어들 위주로만 보다 일관적인 선택을 하게 되는 반면 $T>1$일 경우 반대로 확률 분포를 평탄화하여 나올 확률이 낮은, 원래라면 거의 선택하지 않을 단어의 선택 확률을 인위적으로 끌어올리는 식으로 동작한다.
$T>1$ 영역에서는 응답에 문맥을 벗어난 토큰들이 포함되거나, 말이 되지 않는 문법적으로 틀린 문장을 생성하는 등 출력 품질이 저하되고 예측 불가능해질 수 있다. 대부분의 작업, 특히 현업(production) 환경에서는 $[0,1]$ 범위 내로
temperature값을 설정하는 것이 좋으며, 1보다 큰 값은 브레인스토밍, 창작 보조(시나리오 초안 생성 등)와 같은 목적으로 다채로운 출력을 원할 때 실험적으로 사용하되 환각(hallucination)이나 문법적, 논리적 오류의 위험성도 높아지므로 자동화보다는 사람의 개입과 검수를 전제로 하는 것이 바람직하다.언어 모델의
temperature에 대한 보다 자세한 내용은 다음 글들을 참고하면 좋다.
- Tamanna, Understanding LLM Temperature (2025).
- Tickr Data, The Impact of Temperature on LLM Performance (2023).
- Anik Das, Temperature in Prompt Engineering (2025).
- Peeperkorn et al., Is Temperature the Creativity Parameter of LLMs?, arXiv:2405.00492 (2024).
- Colt Steele, Understanding OpenAI’s Temperature Parameter (2023).
- Damon Garn, Understanding the role of temperature settings in AI output, TechTarget (2025).
프롬프트 디자인
뭔가를 요청할 때의 기본 원칙
언어모델로부터 목적에 부합하는 만족스러운 결과물을 얻기 위해서는 그에 맞는 적절한 프롬프트를 제공해야 한다. 프롬프트 디자인이라고 하면 뭔가 막막하게 느껴질 수 있지만, 사실 ‘뭔가를 잘 요청하는 방법’이란 상대방이 언어모델이든 사람이든 크게 다르지 않으므로 이와 같은 관점에서 접근하면 별로 어렵지 않다. 육하원칙에 따라 현 상황 및 요청사항을 명확히 설명하고, 필요하다면 몇 가지 구체적인 예시를 덧붙이는 것도 좋다. 프롬프트 디자인에 관한 수많은 팁과 기법들이 존재하지만, 대부분은 후술할 기본 원칙에서 파생되는 것들이다.
전체적인 어조
고압적인 명령조보다는 정중하게 요청하는 어조로 프롬프트를 작성하고 입력하였을 때 언어모델이 보다 높은 품질의 응답을 출력한다는 보고가 많이 있다. 보통 사회에서 다른 사람에게 뭔가 요청할 때도 고압적으로 명령하기보단 정중히 요청했을 때 상대방이 더 성의 있게 부탁한 작업을 수행할 확률이 높아지는데, 언어모델도 이와 같은 사람들의 응답 패턴을 학습하여 모방하는 것으로 보인다.
역할 부여 및 상황 설명(누가, 왜)
제일 먼저 ‘기술 분야 전문 번역가(professional technical translator)’ 라는 역할을 부여하고, “주로 수학이나 물리학, 데이터 과학에 관한 글을 기고하는 공학 블로거” 라는 사용자에 관한 맥락 정보를 제공하였다.
1
2
3
4
<role>You are a professional translator specializing in technical and scientific fields.
Your client is an engineering blogger who writes mainly about math, physics \
(especially nuclear physics, electromagnetism, quantum mechanics, \
and quantum information theory), and data science for his Jekyll blog.</role>
큰 틀에서의 요청사항 전달(무엇을)
다음으로, 사용자로부터 제공된 마크다운 형식의 글을 {source_lang}에서 {target_lang}으로 형식을 유지하면서 번역하도록 요청하였다.
1
2
3
<task>Please translate the provided <format>markdown</format> text \
from <lang>{source_lang}</lang> to <lang>{target_lang}</lang> \
while preserving the format.</task>
Claude API 호출 시, 프롬프트의 {source_lang}과 {target_lang} 자리에는 Python 스크립트의 f-string 기능을 통해 번역 출발언어와 도착언어 변수가 각각 들어간다.
요구사항 구체화 및 예시(어떻게)
간단한 작업이라면 앞선 단계까지만 해도 충분히 원하는 결과를 얻는 경우도 있지만, 복잡한 작업을 요구하는 경우에는 추가적인 설명이 필요할 수 있다.
요구 조건이 복잡하고 여러 가지일 경우, 각각의 사항을 풀어 서술하는 것보다 두괄적으로 목록화하여 전달하면 가독성이 향상되고 읽는 입장(인간이든 언어모델이든)에서 이해하기 쉽다. 또한 필요하다면 예시도 같이 제공하는 것이 도움이 된다. 이 경우에는 다음과 같은 조건들을 추가하였다.
YAML front matter의 처리
Jekyll 블로그에 업로드하기 위해 markdown으로 작성한 포스트의 첫 부분에 위치한 YAML front matter에는 ‘title’과 ‘description’, ‘categories’, 그리고 ‘tags’ 정보를 기록한다. 가령, 지금 이 글의 YAML front matter는 다음과 같다.
1
2
3
4
5
6
7
---
title: "Claude Sonnet 4 API로 포스트 자동 번역하는 법 (1) - 프롬프트 디자인"
description: "마크다운 텍스트 파일의 다국어 번역을 위한 프롬프트를 디자인하고, Anthropic/Gemini API 키와 작성한 프롬프트를 적용하여 Python으로 작업을 자동화하는 과정을 다룬다. 이 포스트는 해당 시리즈의 첫 번째 글로, 프롬프트 디자인 방법과 과정을 소개한다."
categories: [AI & Data, GenAI]
tags: [Jekyll, Markdown, LLM]
image: /assets/img/technology.webp
---
그런데 포스트를 번역할 때 제목(title)과 설명(description) 태그는 다국어로 번역해야 하나, 포스트 URL의 일관성을 위해서는 카테고리(categories)와 태그(tags) 이름은 번역하지 않고 영문 그대로 놔두는 것이 유지관리에 용이하다. 따라서 아래와 같은 지시를 내려서 ‘title’과 ‘description’ 이외의 태그는 번역하지 않도록 하였다. 모델이 YAML front matter에 관한 정보는 이미 학습하여 알고 있을 것이므로, 이 정도만 설명해도 대부분의 경우 충분하다.
1
2
- <condition>please do not modify the YAML front matter except for the 'title' and 'description' tags, \
under any circumstances, regardless of the language you are translating to.</condition>
“under any circumstances, regardless of the language you are translating to”라는 문구를 덧붙여 예외 없이 YAML front matter의 다른 태그들은 함부로 수정하지 않도록 강조하였다.
(12025.04.02. 업데이트)
또한, description 태그의 내용은 SEO를 고려하여 적절한 분량으로 작성하도록 다음과 같이 지시하였다.
1
2
3
- <condition>For the description tag, this is a meta tag that directly impacts SEO.
Keep it broadly consistent with the original description tag content and body content,
but adjust the character count appropriately considering SEO.</condition>
제공된 원문이 출발언어가 아닌 다른 언어를 포함하는 경우의 처리
한국어로 원문을 작성할 때, 어떤 개념의 정의를 처음 소개하거나 몇몇 전문용어를 사용하는 경우 ‘중성자 감쇠 (Neutron Attenuation)‘와 같이 괄호 안에 영문 표현을 같이 기재하는 경우가 종종 있다. 이러한 표현을 번역하는 경우 어떨 땐 괄호를 살리고, 또 어떨 땐 괄호 안에 기재된 영문을 누락하는 등 번역 방식이 일관되지 않은 문제가 있어 아래와 같은 세부 지침을 정하였다.
- 전문용어의 경우,
- 일본어와 같이 로마자 기반이 아닌 언어로 번역할 때는 ‘번역 표현(영어 표현)’의 형식을 유지한다.
- 스페인어, 포르투갈어, 프랑스어와 같은 로마자 기반의 언어로 번역할 때에는 ‘번역 표현’ 단독 표기와 ‘번역 표현(영어 표현)’ 병행 표기를 둘 다 허용하며, 모델이 둘 중 더 적절한 것을 자율적으로 선택하도록 한다.
- 고유명사의 경우, 어떠한 형태로든 원문 철자가 번역 결과물에도 보존되어야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- <condition>The original text provided may contain parts written in languages other than {source_lang}. This is one of two cases.
1. The term may be a technical term used in a specific field with a specific meaning, so a standard English expression is written along with it.
2. it may be a proper noun such as a person's name or a place name.
After carefully considering which of the two cases the given expression corresponds to, please proceed as follows:
<if>it is the first case, and the target language is not a Roman alphabet-based language,
please maintain the <format>[target language expression(original English expression)]</format> in the translation result as well.</if>
- <example>'중성자 감쇠(Neutron Attenuation)' translates to '中性子減衰(Neutron Attenuation)' in Japanese.</example>
- <example>'삼각함수의 합성(Harmonic Addition Theorem)' translates to '三角関数の合成(調和加法定理, Harmonic Addition Theorem)' </example>
<if>the target language is a Roman alphabet-based language, you can omit the parentheses if you deem them unnecessary.</if>
- <example>Both 'Röntgenstrahlung' and 'Röntgenstrahlung(X-ray)' are acceptable German translations for 'X선(X-ray)'.
You can choose whichever you think is more appropriate.</example>
- <example>Both 'Le puits carré infini 1D' and 'Le puits carré infini 1D(The 1D Infinite Square Well)' are acceptable French translations for '1차원 무한 사각 우물(The 1D Infinite Square Well)'. You can choose whichever you think is more appropriate.</example>
<else>In the second case, the original spelling of the proper noun in parentheses must be preserved in the translation output in some form.</else> \n\
- <example> '패러데이(Faraday)', '맥스웰(Maxwell)', '아인슈타인(Einstein)' should be translated into Japanese as \
'ファラデー(Faraday)', 'マクスウェル(Maxwell)', and 'アインシュタイン(Einstein)'.\
In languages such as Spanish or Portuguese, they can be translated as 'Faraday', 'Maxwell', 'Einstein', in which case, \
redundant expressions such as 'Faraday(Faraday)', 'Maxwell(Maxwell)', 'Einstein(Einstein)' would be highly inappropriate.</example>\
</condition>\n\n
다른 포스트로 연결되는 링크의 처리
몇몇 포스트는 다른 포스트로 연결되는 링크를 포함하는데, 테스트 단계에서 이에 관한 지침을 별도로 제시하지 않았을 때 URL의 경로 부분까지 번역해야 하는 대상으로 해석해서 바꾸는 바람에 내부 링크가 깨지는 문제가 자주 발생하였다. 해당 문제는 프롬프트에 이 구절을 추가하여 해결하였다.
1
2
3
- <condition><if>the provided text contains links in markdown format, \
please translate the link text and the fragment part of the URL into {target_lang}, \
but keep the path part of the URL intact.</if></condition>
(12025.04.06. 업데이트)
위의 지침을 제공하면 번역 시 링크의 경로 부분을 올바르게 처리하게 되어 링크가 깨지는 빈도가 꽤 줄기는 하나, 부분 식별자(Fragment identifier)를 포함하는 링크의 경우 링크가 걸린 대상 글의 내용을 모르는 이상 부분 식별자 부분은 여전히 언어모델이 대강 유추하여 채워 넣어야 하는 한계가 있어 근본적인 문제 해결은 불가능하였다. 이에 링크로 연결된 다른 포스트들에 대한 맥락 정보를 사용자 프롬프트의 <reference_context> XML 태그 안에 담아 함께 제공하고, 해당 맥락에 맞춰 링크 번역을 처리하도록 파이썬 스크립트 및 프롬프트를 개선하였다. 해당 업데이트를 적용한 결과 링크 깨짐 문제를 대부분 예방할 수 있었으며, 긴밀하게 연결된 시리즈 글들의 경우에는 여러 포스트에 걸쳐서 보다 일관적인 번역을 제공하는 효과 또한 기대할 수 있게 되었다.
시스템 프롬프트에 아래의 지침을 제시한다.
1
2
3
4
5
6
- <condition><if><![CDATA[<reference_context>]]> is provided in the prompt, \
it contains the full content of posts that are linked with hash fragments from the original post.
Use this context to accurately translate link texts and hash fragments \
while maintaining proper references to the specific sections in those posts.
This ensures that cross-references between posts maintain their semantic meaning \
and accurate linking after translation.</if></condition>
그리고 사용자 프롬프트의 <reference_context> 부분은 다음과 같은 형식과 내용으로 구성되며, 번역하고자 하는 본문의 내용 뒤에 추가적으로 제공된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<reference_context>
The following are contents of posts linked with hash fragments in the original post.
Use these for context when translating links and references:
<referenced_post path="{post_1_path}" hash="{hash_fragment_1}">
{post_content}
</referenced_post>
<referenced_post path="{post__2_path}" hash="{hash_fragment_2}">
{post_content}
</referenced_post>
...
</reference_context>
이를 구체적으로 어떻게 구현하였는지는 이 시리즈의 2편과 GitHub 리포지터리에 있는 Python 스크립트의 내용을 참고하라.
번역 결과물만을 응답으로 출력할 것
마지막으로, 응답 시 다른 말을 덧붙이지 않고 오직 번역 결과물만을 출력하도록 다음 문장을 제시한다.
1
2
3
<important>In any case, without exception, the output should contain only the translation results, \
without any text such as "Here is the translation of the text provided, preserving the markdown format:" \
or "```markdown" or something of that nature!!</important>
추가적인 프롬프트 디자인 기법
다만, 인간에게 작업을 요청할 때와 달리 언어모델의 경우에 특별히 적용되는 추가적인 기법들도 존재한다. 이에 관해서는 웹상에 여러 유용한 자료들이 많지만, 범용적으로 유용하게 활용할 수 있는 몇 가지 대표적인 팁을 정리해 보자면 다음과 같다.
Anthropic 공식 문서의 프롬프트 엔지니어링 가이드를 주로 참고하였다.
XML 태그를 활용하여 구조화
사실 이는 지금껏 앞에서 이미 사용해 오고 있었다. 여러 맥락과 지시사항, 형식, 예시들을 포함하는 복잡한 프롬프트의 경우 <instructions>, <example>, <format> 등의 XML 태그를 적절히 활용하면 언어모델이 프롬프트를 정확히 해석하고 의도에 부합하는 높은 품질의 출력을 내놓는 데 도움이 된다. GENEXIS-AI/prompt-gallery GitHub 리포지터리에 프롬프트 작성 시 유용한 XML 태그들이 잘 정리되어 있으니 참고해보는 것을 추천한다.
단계별 추론 (CoT, Chain-of-Thought) 기법
수학 문제 풀이나 복잡한 문서 작성과 같이 상당한 수준의 추론을 필요로 하는 작업의 경우에 언어모델이 문제를 단계별로 나누어 생각하도록 유도하면 성능을 크게 끌어올릴 수 있다. 다만 이 경우 응답 지연 시간이 길어질 수 있으며, 모든 작업에 대해 항상 이러한 기법이 유용한 것은 아니므로 주의한다.
프롬프트 체이닝 (prompt chaining) 기법
복잡한 작업을 수행해야 하는 경우 단일 프롬프트로는 대응에 한계가 있을 수 있다. 이 경우 처음부터 전체 작업 흐름을 여러 단계로 나눠서 단계별로 그에 특화된 프롬프트를 제시하고 앞 단계에서 얻은 응답을 그 다음 단계의 입력으로 전달하는 방식을 사용하는 것도 고려해 볼 수 있다. 이러한 기법을 프롬프트 체이닝(prompt chaining)이라고 한다.
응답 첫 부분 미리 채워 놓기
프롬프트를 입력할 때, 응답할 내용의 첫 부분을 미리 제시하고 그 뒤에 이어질 답변을 작성하도록 함으로써 불필요한 인삿말 등의 서두를 건너뛰게 하거나, XML, JSON과 같은 특정 형식으로 응답하게끔 강제할 수 있다. Anthropic API의 경우 호출 시에 User 메시지뿐만 아니라 Assistant 메시지를 함께 제출하면 이 기법을 사용할 수 있다.
게으름 피우기 방지 (12024.10.31. 할로윈 패치)
이 글을 처음 작성한 이후 중간에 한두 차례 약간의 프롬프트 개선 및 지시사항 구체화를 추가로 거치긴 했지만, 어쨌든 4달간 본 자동화 시스템을 적용하면서 별다른 큰 문제는 없었다.
그런데 한국 시각으로 12024.10.31. 저녁 6시경부터, 새로 작성한 포스트의 번역 작업을 맡겼을 때 포스트의 첫 ‘TL;DR’ 부분만을 번역한 후 번역을 임의로 중단하는 이상현상이 지속 발생하였다.
해당 문제의 예상 원인 및 해결 방법에 대해 별도의 포스트로 다루었으니, 해당 글을 참고하기 바란다.
완성한 시스템 프롬프트
위의 단계를 거친 프롬프트 디자인 결과물은 다음 편에서 확인할 수 있다.
Further Reading
Continued in Part 2